Hadoop经典案例(排序&Join&topk&小文件合并)
①自定义按某列排序,二次排序
writablecomparable中的compareto方法

②topk
a利用treemap,缺点:map中的key不允许重复:https://blog.csdn.net/u010660276/article/details/50967054
b封装mapper<key,value>中的key实现writablecompareable接口,实现排序https://blog.csdn.net/lzm1340458776/article/details/43228191
③自定义分区函数:实现按省份输出信息
分区的目的:将相同的key值放到一个reduce中处理,将reduce处理完的数据按key分别存到不同的文件中
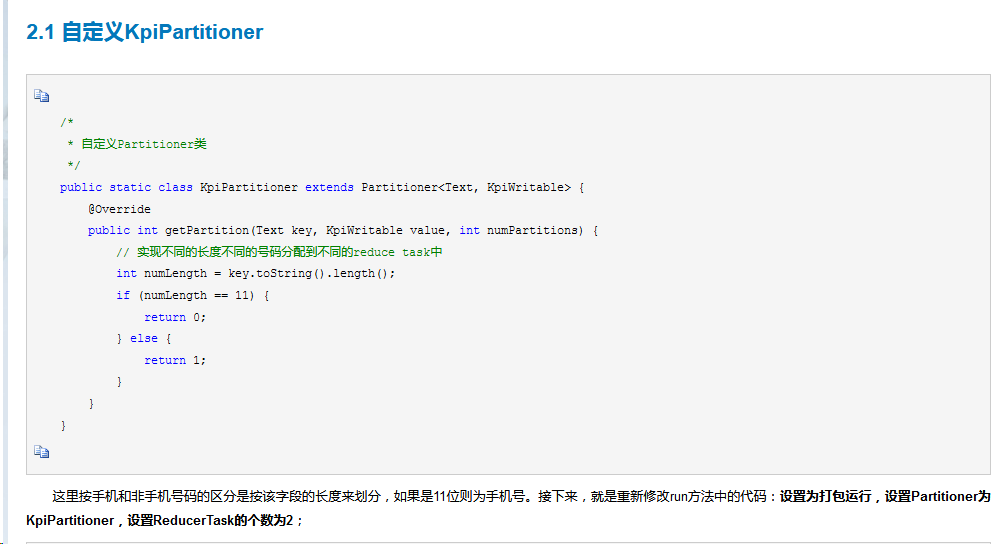
④数据去重
由于在map阶段之后会将相同key的value分组,分组之后的每一个key都是唯一的,消除数据去重时可以将数据直接作为map的key然后输出,map之后就会是唯一的,在reduce阶段直接输出就可。
⑤常用的输入格式:https://blog.csdn.net/u011812294/article/details/63262624
⑥mapreduce中的join:map端join和reduce端join(将需要连接操作的表同时或者选择小的加载到内存中)
map端join和reduce端join举例:https://blog.csdn.net/litianxiang_kaola/article/details/71598632
https://blog.csdn.net/guxin0729/article/details/84035513
map端join:在map的setup()中将小的表加入hashmap中,(指定小表path将表存入话说hashmap中)(在setup中读取小文件)
map()中实现读取一行将条件去匹配hashmap中的值,构造join表类
在main()中只需要指定inputmapperpath为map()中需要读取的大文件即可
reduce端join:mapper中将条件作为key,join的类为value
reducer中创建ArrayList,然后实现join
两者的对比:https://blog.csdn.net/weixin_39979119/article/details/85041438
如何选择:
reduce端join,当两个文件的大小差距较大时,会产生数据倾斜,在reducer中需要结合List
map端join,仅适用于大小表或者小小表关联
⑦小文件合并
Hadoop经典案例(排序&Join&topk&小文件合并)的更多相关文章
- hadoop 将HDFS上多个小文件合并到SequenceFile里
背景:hdfs上的文件最好和hdfs的块大小的N倍.如果文件太小,浪费namnode的元数据存储空间以及内存,如果文件分块不合理也会影响mapreduce中map的效率. 本例中将小文件的文件名作为k ...
- Hadoop MapReduce编程 API入门系列之小文件合并(二十九)
不多说,直接上代码. Hadoop 自身提供了几种机制来解决相关的问题,包括HAR,SequeueFile和CombineFileInputFormat. Hadoop 自身提供的几种小文件合并机制 ...
- Hadoop案例(六)小文件处理(自定义InputFormat)
小文件处理(自定义InputFormat) 1.需求分析 无论hdfs还是mapreduce,对于小文件都有损效率,实践中,又难免面临处理大量小文件的场景,此时,就需要有相应解决方案.将多个小文件合并 ...
- hadoop经典案例
hadoop经典案例http://blog.csdn.net/column/details/sparkhadoopdemo.html
- MR案例:小文件合并SequeceFile
SequeceFile是Hadoop API提供的一种二进制文件支持.这种二进制文件直接将<key, value>对序列化到文件中.可以使用这种文件对小文件合并,即将文件名作为key,文件 ...
- hive小文件合并设置参数
Hive的后端存储是HDFS,它对大文件的处理是非常高效的,如果合理配置文件系统的块大小,NameNode可以支持很大的数据量.但是在数据仓库中,越是上层的表其汇总程度就越高,数据量也就越小.而且这些 ...
- HDFS操作及小文件合并
小文件合并是针对文件上传到HDFS之前 这些文件夹里面都是小文件 参考代码 package com.gong.hadoop2; import java.io.IOException; import j ...
- Hive merge(小文件合并)
当Hive的输入由非常多个小文件组成时.假设不涉及文件合并的话.那么每一个小文件都会启动一个map task. 假设文件过小.以至于map任务启动和初始化的时间大于逻辑处理的时间,会造成资源浪费.甚至 ...
- hive优化之小文件合并
文件数目过多,会给HDFS带来压力,并且会影响处理效率,可以通过合并Map和Reduce的结果文件来消除这样的影响: set hive.merge.mapfiles = true ##在 map on ...
随机推荐
- Spring Boot 2.0 新特性和发展方向
以Java 8 为基准 Spring Boot 2.0 要求Java 版本必须8以上, Java 6 和 7 不再支持. 内嵌容器包结构调整 为了支持reactive使用场景,内嵌的容器包结构被重构了 ...
- HTTP状态码简单总结
状态码数字的第一位表明了响应类别,如以下5种: 类别 原因短语 1XX Informational(信息性状态码) 接受的请求正在处理 2XX Success(成功状态码) 请求正常处理完毕 ...
- Redis的数据结构之List
存储list: ArrayList使用数组方式 LinkedList使用双向链接方式 双向链接表中增加数据 双向链接表中删除数据 存储list常用命令 两端添加 两端弹出 扩展命令 lpush 方式添 ...
- spring相关jar包
spring.jar是包含有完整发布的单个jar 包,spring.jar中包含除了spring-mock.jar里所包含的内容外其它所有jar包的内容,因为只有在开发环境下才会用到 spring-m ...
- 【托业】toeic托业必背核心词汇_修正版
- Android studio中导入SlidingMenu问题
我们导入的library文件夹中的build.gradle 文件里面写的很清楚: android { compileSdkVersion 17 buildToolsVersion &q ...
- java框架之SpringMVC(2)-补充及拦截器
高级参数绑定 package com.zze.springmvc.web.controller; import org.springframework.stereotype.Controller; i ...
- C#:进程
using System; using System.Collections.Generic; using System.Diagnostics; using System.Linq; using S ...
- [转载]资深程序员点评当前某些对Lotus Domino 的不实评论
实现机关办公自动化工作需要计算机技术的支持,在计算机软件范围中,有网络操作系统软件.数据库软件和开发工具等基本系统软件,在此基础上开发出适合本单位使用的应用软件.对如何选用系统软件,笔者没有发言权,但 ...
- springboot 没有跳转到指定页面
Whitelabel Error Page 解决办法,添加依赖: <dependency> <groupId>org.springframework.boot</gr ...