Papers | 图像/视频增强 + 深度学习
目录
I. ARCNN
Compression Artifacts Reduction by a Deep Convolutional Network
2015年发表,2018年12月引用165次。
1. Motivation
压缩图像或视频最显著的问题就是 artifacts 。比如块效应,振铃效应和图像模糊。
块效应是由块内 DCT 导致的;振铃效应是因为高频分量的粗量化(原本频谱是渐进过渡的;由于粗量化,频谱出现陡变,导致像素域振荡);图像模糊是由于高频分量的丢失( IDCT 引入)。
而现存的算法中,要么着力于消除块效应,但导致图像更模糊(错杀友军);要么着力于去模糊,但引入振铃效应(带通滤波器边缘导致)。
说白了,这些都是传统图像处理方法的局限性,用于压缩图像或视频显然是不合适的。
关键原因是:传统方法复杂度太低,往往顾此失彼。
但压缩又是不可避免的,因为要节省带宽和存储空间。
因此,我们引入深度学习方法,来 seamlessly 缓解压缩效应。
该工作是受深度学习网络 DCN 应用于超分辨的启发。
2. Contribution
本文有两大贡献点:
第一,第一个用深度学习方法解决压缩图像/视频的质量增强问题。
第二,用浅层网络学习特征,再用深度网络提升质量。第一个证明了迁移学习在 low-level 学习任务中的有效性。
下面具体说第二点。
超分辨深度学习网络的鼻祖:SRCNN,用于该任务非常不合适。
原因是:许多不同的 artifact 耦合在一起,导致 SRCNN 第一层提取到的特征充满了噪声,恢复也是混乱的。
说白了,就是特征提取比较困难。
解决方法也很简单,在特征提取以后,我们需要用更多的层,来消除这些噪声。
尽管深度有其优势,但深度在 low-level 的视觉任务中同样有其弊端,即训练出现了困难。
Specifically, “deeper is not better” has been pointed out in super-resolution [4], where training a five-layer network becomes a bottleneck. The difficulty of training is partially due to the sub-optimal initialization settings.
为此,作者提出,先用 shallow network 提取特征,再用深度网络进一步处理,可以解决这一难题。
这就是所谓的 "easy to hard" 思想,在图像分类任务上同样适用。
此外,作者还发现许多有意思的应用:
- 先学习高质量压缩视频的增强模型,再在低质量样本上继续迭代,收敛速度比随机初始化更快;
- 先学习单一压缩模式得到的模型,再在复杂、多种压缩模式得到的样本上继续训练,效果会更好。
简单来说,就是 fine-tune 简单模型。
现在由于引入了残差学习、BN 等一系列方法,深度网络训练已不成问题。
3. Artifacts Reduction Convolutional Neural Networks (ARCNN)
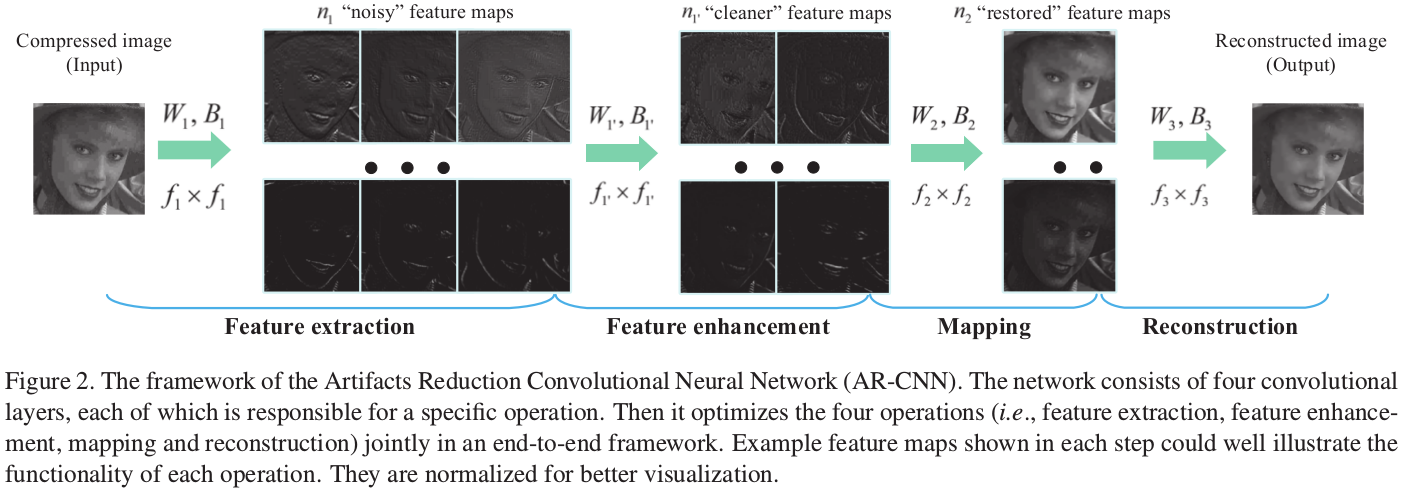
乍一看,还以为 ARCNN 只是 SRCNN 的加深版。但实际上不是的。
ARCNN 的精髓在于其特征再提取。
作者在 JPEG 压缩实验中发现,一些量化噪声和高频细节耦合在一起,被放大,因而在锐利边缘处引入了新的失真。
此外,在一些平坦区域的块效应没有被识别出来。
因此,作者引入了 feature enhancement layer ,进一步精炼提取到的特征。
作者对此的解释:
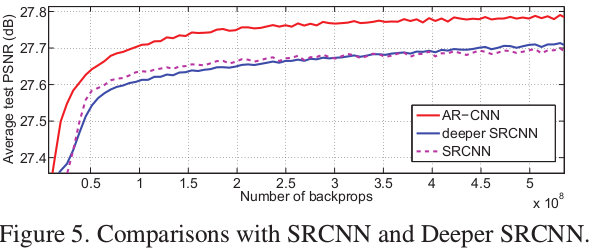
It is worth noticing that AR-CNN is not equal to a deeper SRCNN that contains more than one non-linear mapping layers 2.
A deeper SRCNN imposes more non-linearity in the mapping stage, which equals to adopting a more ro-
bust regressor between the low-level features and the final output. Similar ideas have been proposed in some sparse-coding-based methods [14, 2].
However, as the compression artifacts are complex, low-level features extracted by a single layer are noisy. Thus the performance bottleneck lies on the features but not the regressor.
AR-CNN improves the mapping accuracy by enhancing the extracted low-level features, and the first two layers together can be regarded as a better feature extractor. This leads to better performance than a deeper SRCNN.
最后,实验结果也证明了 ARCNN 要比深一层的 SRCNN 出色。
在实验中, ARCNN 的设置为:kernel size 分别为 \(9 \times 9, 7 \times 7, 1 \times 1, 5 \times 5 (9-7-1-5)\),滤波器数量分别为 \(64,32,16,1(64-32-16-1)\) 。
与之对比, SRCNN 只有3层,分别为 \(9-1-5\) 和 \(64-32-1\) 。
更进一步,作者还设置了 Deeper SRCNN ,配置为 \(9-1-1-5\) 和 \(64-16-32-1\) 。

II. DnCNN
Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising
2016年发表,2018年12月引用量约500。
1. Introduction
在此之前, Discriminative model 用于图像去噪已经取得了巨大的成功。
在这篇文章中,作者尝试了前向深度网络: Denoising convolutional neural networks (DnCNNs) 。
在此过程中,作者加入了 BN 和残差学习技巧,既加快训练速度,也提升模型性能。
引入残差学习的好处:不同图像任务,大多只区别于残差;比如加不同程度的高斯噪声。因此 DnCNNs 在多种图像去噪任务上都可以胜任。
上述思路,在2016年还行得通。但在深度学习泛滥的今天,骨头汤里的肉已经被吃完了,只剩骨头了。因此,单纯增加深度和引入结构性设计,是很难作为创新点的。
由贝叶斯学派的观点,对于图片去噪,当似然已知时,图像的先验就是决定性因素。
事实上,过去多年内,许多人都在朝这一方向努力。如 nonlocal self-similarity (NSS) models ,稀疏模型等。
但它们都有两个共同缺点:
- 在测试阶段,这些方法都包含一个复杂的优化过程,非常耗时。
- 这些模型大体上都是非凸的,并且包含手工设计的参数。
后人做了一些改进,着力于取代测试阶段复杂的迭代优化过程。然而,它们的性能仍然受到先验类别的局限。具体来说,它们对特征的挖掘存在局限,并且包含了大量手工设计的参数。
事实上,这也是大多数传统方法和深度学习方法相比较的劣势。深度学习方法可解释性不佳,但是很少需要人工介入,也很强大。
2. Denoising Convolutional Neural Networks (DnCNN) network
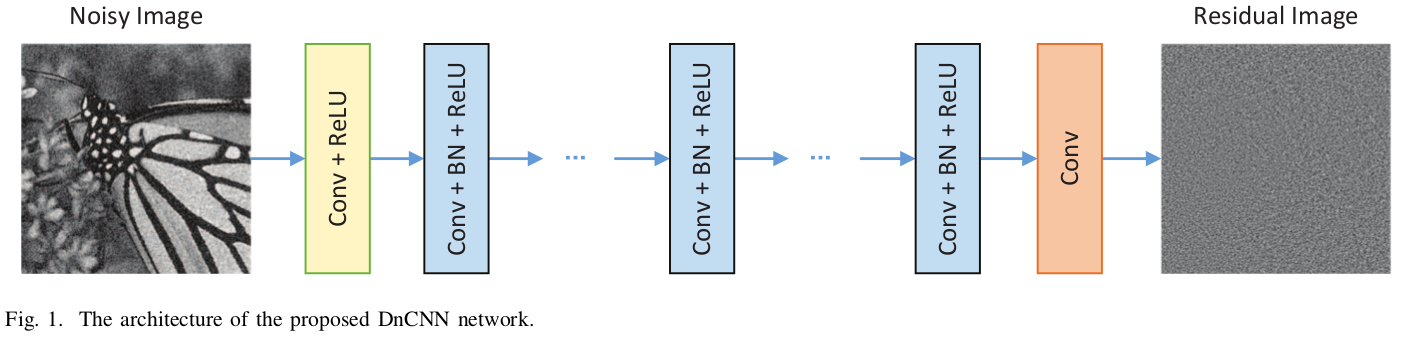
网络结构是简单的一条流水线:前面只用了简单 CNN 和 ReLU 激活单元,中间用 CNN Plus BN 加速训练,最后 CNN 输出。
整体上是学习残差。
该网络对比前任的优点还有:通过简单的零插值,就可以使输入、输出尺寸相同,避免了 Boundary artifacts 。
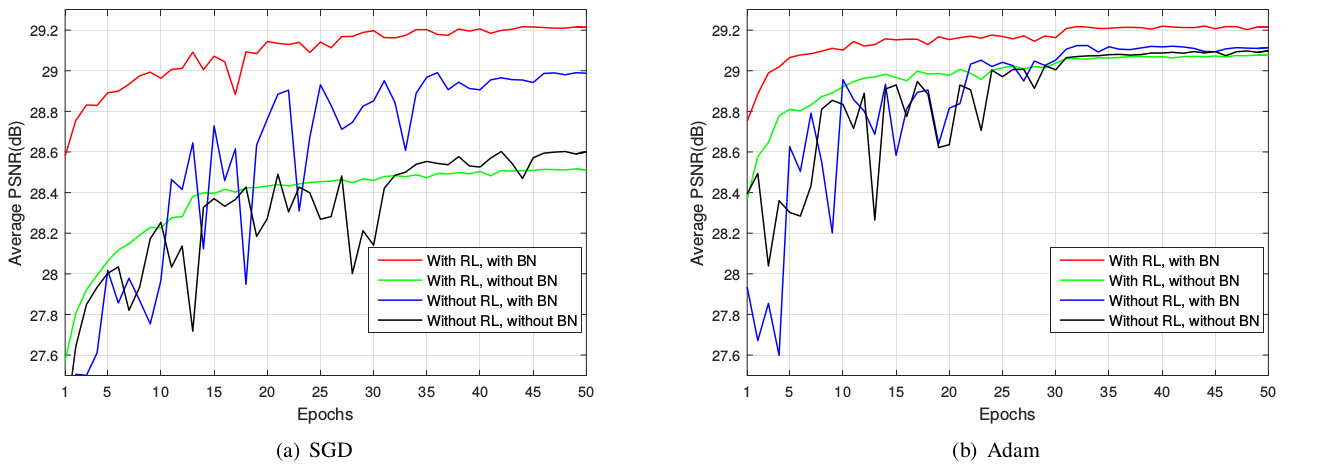
由于结构性创新是重点,因此作者比较了不同配置下网络的性能。有趣的是, BN 和 ResLearning 缺一不可,否则性能可能不如传统方法。
最后,为了实现所谓的多任务,作者在训练集中掺入不同噪声的训练样本, JPEG 压缩图像 或 降采样图像。实验表明,这样训练出来的单一模型,仍然可以胜任多任务。
III. Li et al.
An efficient deep convolutional neural networks model for compressed image deblocking.
这篇文章主要针对于JPEG图片的质量增强。该文章引用不多,我们主要关注其网络实现和其高效率。
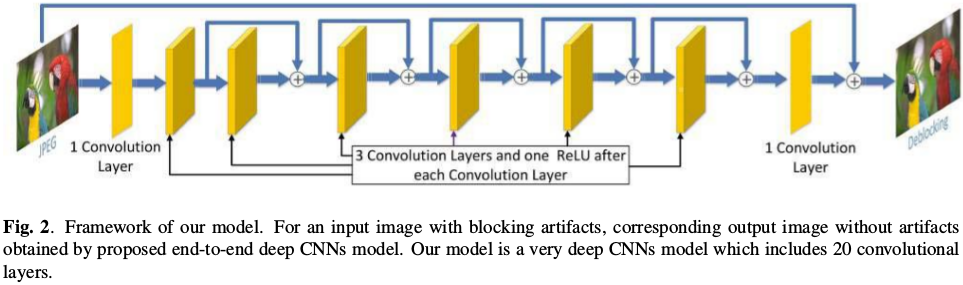
- 20 convolutional layers
- ReLU activation
- 32 feature maps, \(5 \times 5\) kernel
- 6 shortcut connection
- MSE loss
- SGD
- Weight decay (0.05)
IV. DCAD
A Novel Deep Learning-Based Method of Improving Coding Efficiency from the Decoder-End for HEVC.
2017年发表在DCC,2018年12月引用约18次。
1. Introduction
作者提出了一个很有趣的观点:解码的视频,在某种程度上可以看作是原始视频的压缩采样。
而根据压缩感知原理,通过一些恢复方法,解码视频的质量可以得到增强。
作者还提到,传统方法的局限性在于:它们只能利用单个图片的信息,而不能利用先验知识。
传统方法如滤波方法,现代方法如深度学习方法。
此外, patch matching 方法和 compressed sensing-based 方法都很耗时。
2. Deep CNN-based Auto Decoder (DCAD) network
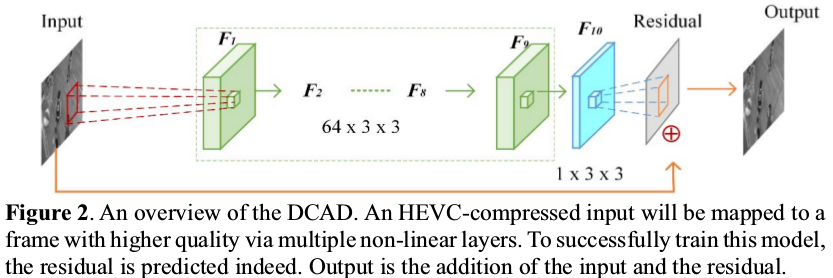
如图。作者试过20层,效果没有更好。
Papers | 图像/视频增强 + 深度学习的更多相关文章
- 阶段2-新手上路\项目-移动物体监控系统\Sprint2-摄像头子系统开发\第2节-V4L2图像编程接口深度学习
参考资料: http://www.cnblogs.com/emouse/archive/2013/03/04/2943243.htmlhttp://blog.csdn.net/eastmoon5021 ...
- NeuralEnhance: 提高图像分辨率的深度学习模型
NeuralEnhance是使用深度学习训练的提高图像分辨率的模型,使用Python开发,项目地址:https://github.com/alexjc/neural-enhance. 貌似很多电影都有 ...
- TX2之多线程读取视频及深度学习推理
背景 一般在TX2上部署深度学习模型时,都是读取摄像头视频或传入视频文件进行推理,从视频中抽取帧进行目标检测等任务.对于大点的模型,推理的速度是赶不上摄像头或视频的帧率的,如果我们使用单线程进行处理, ...
- [国嵌攻略][171][V4L2图像编程接口深度学习]
V4L2摄像编程模型 1.打开摄像头设备文件 2.获取驱动信息-VIDIOC_QUERYCAP 3.设置图像格式-VIDIOC_S_FMT 4.申请帧缓冲-VIDIOC_REQBUFS 5.获取帧缓冲 ...
- PyTorch中使用深度学习(CNN和LSTM)的自动图像标题
介绍 深度学习现在是一个非常猖獗的领域 - 有如此多的应用程序日复一日地出现.深入了解深度学习的最佳方法是亲自动手.尽可能多地参与项目,并尝试自己完成.这将帮助您更深入地掌握主题,并帮助您成为更好的深 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- 卷积在深度学习中的作用(转自http://timdettmers.com/2015/03/26/convolution-deep-learning/)
卷积可能是现在深入学习中最重要的概念.卷积网络和卷积网络将深度学习推向了几乎所有机器学习任务的最前沿.但是,卷积如此强大呢?它是如何工作的?在这篇博客文章中,我将解释卷积并将其与其他概念联系起来,以帮 ...
- 机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- 【PyTorch深度学习】学习笔记之PyTorch与深度学习
第1章 PyTorch与深度学习 深度学习的应用 接近人类水平的图像分类 接近人类水平的语音识别 机器翻译 自动驾驶汽车 Siri.Google语音和Alexa在最近几年更加准确 日本农民的黄瓜智能分 ...
随机推荐
- Postgres——pgadmin复制无主键单表至本地数据库
数据库中存在无主键单表gongan_address_all ,需要将余杭区数据导出成另外一张表,因为数据量太大,sql语句效率太差. 通过sql语句查询出余杭区数据,并导出成csv,sql等格式,再导 ...
- jsonp原理及同源策略
[个人学习笔记,如有问题还请前辈纠正] jsonp 是用来跨域读取数据的,为什么从不同的域访问数据要用jsop呢?这源于一个著名的安全策略--同源策略,即: 协议.端口号.域名相同 举例说明:http ...
- autocomplete input
<html> <head> <title>jQuery UI Autocomplete - Combobox</title> <link rel= ...
- 清除UIWebView缓存
//清除cookies NSHTTPCookie *cookie; NSHTTPCookieStorage *storage = [NSHTTPCookieStorage sharedHTTPCook ...
- python变量、注释、程序交互、格式化输入、基本运算符
变量 ...
- Android下的几种时间格式转换
更多更全的工具类,请参考github上的Blankj/AndroidUtilCode 将毫秒转换为小时:分钟:秒格式 public static String ms2HMS(int _ms){ Str ...
- ElasicSearch(3) 安装elasticsearch-head
https://github.com/mobz/elasticsearch-head 1.git install git 2.git clone git://github.com/mobz/elast ...
- js中json的使用
- 关于spfa
关于spfa的一些事宜.... 刚开始学的时候只会跑最短路,代码都是背下来的.以下是背的代码... inline void spfa(int s) { queue<int>q;q.push ...
- canvas(二) lineCap demo
var dom = document.getElementById('clock'), ctx = dom.getContext('2d'); ctx.beginPath(); ctx.moveTo( ...