开源通用爬虫框架YayCrawler-开篇
各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品——YayCrawler,其在GitHub上的网址是:https://github.com/liushuishang/YayCrawler,欢迎大家关注和反馈。
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们知道目前爬虫框架很多,有简单的,也有复杂的,有轻量型的,也有重量型的。您也许会问:你这个爬虫框架的优势在哪里呢?额,这个是一个很重要的问题!在这个开篇中,我先简单的介绍一下我这个爬虫框架的特点,后面的章幅会详细介绍并讲解它的实现,一图胜千言:
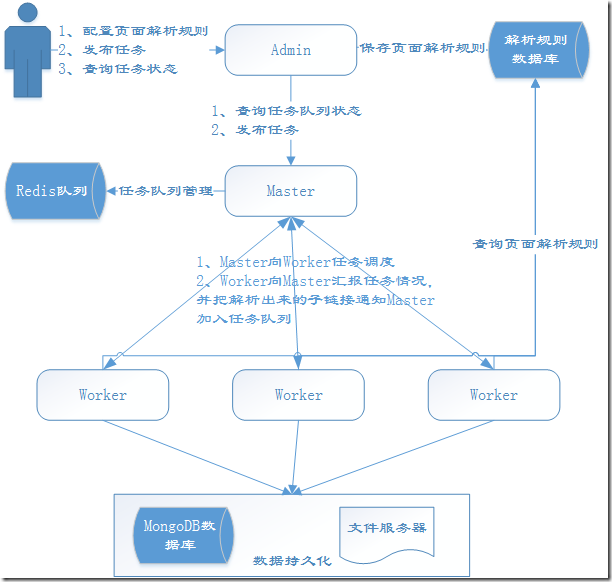
1、分布式:YayCrawler就是一个大哥(Master)多个小弟(Worker)的架构(这种结构才是宇宙的真理),当然大哥还有一个小秘(Admin)和外界交往。
2、通用性:我们很多时候需要爬取不同网站的数据,各个网站的结构和内容都有很大的差别,基本上大部分人都是遇到一个网站写一份代码,没法做到工具的复用。YayCrawler就是想改变这种情况,把不同的部分抽象出来,用规则来指导爬虫做事。也就是说用户可以在界面上配置如何抓取某个页面的数据的规则,等爬虫在爬取这个页面的时候就会用这个事先配置好的规则来解析数据,然后把数据持久化。
3、可扩展的任务队列:任务队列由Redis实现,根据任务的状态有四种不同的任务队列:初始、执行中、成功、失败。您也可以扩展不同的任务调度算法,默认是公平调度。
4、可定义持久化方式:爬取结果中,属性数据默认持久化到MongoDB,图片会被下载到文件服务器,当然您可以扩展更多的存储方式。
5、稳定和容错:任何一个失败的爬虫任务都会重试和记录,只有任务真正成功了才会被移到成功队列,失败会有失败的原因描述。
6、反监控组件:网站为了防止爬虫也是煞费苦心,想了一系列的监控手段来反爬虫。作为对立面,我们自然也要有反监控的手段来保障我们的爬虫任务,目前主要考虑的因素有:cookie失效(需要登陆)、刷验证码、封IP(自动换代理)。
7、可以对任务设置定时刷新,比如隔一天更新某个网站的数据。
……
上面说了一大堆优点的目的只有一个:希望您能有兴趣继续看下去,哈哈。
言归正传,本文作为开篇,只是一个总览,现在我们来整理一下后续文章的结构安排:
- 开源通用爬虫框架YayCrawler-运行与调试
- 开源通用爬虫框架YayCrawler-框架的运行机制
- 开源通用爬虫框架YayCrawler-页面的抽取规则定义
- 开源通用爬虫框架YayCrawler-任务队列详解
- 开源通用爬虫框架YayCrawler-页面下载器详解
- 开源通用爬虫框架YayCrawler-规则解析器详解
- 开源通用爬虫框架YayCrawler-数据持久化详解
- 开源通用爬虫框架YayCrawler-反监控组件详解
- 开源通用爬虫框架YayCrawler-案例演示
- 开源通用爬虫框架YayCrawler-待完善的功能
开源通用爬虫框架YayCrawler-开篇的更多相关文章
- 开源通用爬虫框架YayCrawler-页面的抽取规则定义
本节我将向大家介绍一下YayCrawler的核心-页面的抽取规则定义,这也是YayCrawler能够做到通用的主要原因之一.如果我要爬去不同的网站的数据,尽管他们的网站采用的开发技术不同.页面的结构不 ...
- 开源通用爬虫框架YayCrawler-运行与调试
本节我将向大家介绍如何运行与调试YayCrawler.该框架是采用SpringBoot开发的,所以可以通过java –jar xxxx.jar的方式运行,也可以部署在tomcat等容器中运行. 首先 ...
- 开源通用爬虫框架YayCrawler-框架的运行机制
这一节我将向大家介绍一下YayCrawler的运行机制,首先允许我上一张图: 首先各个组件的启动顺序建议是Master.Worker.Admin,其实不按这个顺序也没关系,我们为了讲解方便假定是这个启 ...
- 爬虫框架YayCrawler
爬虫框架YayCrawler 各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品——YayCrawler,其在GitHub上的网址是:https://github.com/liush ...
- 一个简单的开源PHP爬虫框架『Phpfetcher』
这篇文章首发在吹水小镇:http://blog.reetsee.com/archives/366 要在手机或者电脑看到更好的图片或代码欢迎到博文原地址.也欢迎到博文原地址批评指正. 转载请注明: 吹水 ...
- 基于 Java 的开源网络爬虫框架 WebCollector
原文:https://www.oschina.net/p/webcollector
- Scrapy爬虫框架第一讲(Linux环境)
1.What is Scrapy? 答:Scrapy是一个使用python语言(基于Twistec框架)编写的开源网络爬虫框架,其结构清晰.模块之间的耦合程度低,具有较强的扩张性,能满足各种需求.(前 ...
- [开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [一] 初衷与架构设计
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 为什么要造轮子 同学们可以去各大招聘网站查看一下爬虫工程师的要求,大多是招JA ...
- gRPC:Google开源的基于HTTP/2和ProtoBuf的通用RPC框架
gRPC:Google开源的基于HTTP/2和ProtoBuf的通用RPC框架 gRPC:Google开源的基于HTTP/2和ProtoBuf的通用RPC框架 Google Guava官方教程(中文版 ...
随机推荐
- File类_深度遍历文件夹_练习
遍历指定目录下的所有文件和文件夹 import java.io.File; public class FileTest { public static void main(String[] args) ...
- Django之form表单认证
Model常用操作: - 参数:filter 三种传参方式 - all(得到的是列表),values(字典),values_list(元祖) [obj(id,name,pwd,email),obj(i ...
- 小度之家SDK功能介绍
https://developer.dueros.baidu.com/doc/device-devkit/intro_markdown
- 为什么学习Lua
目前公认的最快的脚本语言 可以编译调试 与C/C++结合容易 Lua是对性能有要求的必备脚本 C++的缺点: 编译慢,调试难 学习难度大
- matlab的conv2、imfilter、filter2
1 conv2函数 C=conv2(A,B,shape); %卷积滤波 参数说明: A:输入图像 B:卷积核 shape的可选值为full.same.valid. 1)当shape=full时,返回全 ...
- Django rest framework集成微博第三方登录
Django restframework 集成第三方登录(微博.微信.QQ等) 友情链接 python-social-auth-app官方文档 微博开放者平台 QQ开放者平台 准备工作 1.注册微博开 ...
- Mongodb数据库连接
Mongodb数据库连接 1. 首先我们需要 在包中安装 mongodb, 使用命令: npm install mongodb; 在安装包后,我们需要引用该包:如下: var mongo = requ ...
- 对 String 字符串的理解
1.通过构造方法创建的字符串对象和直接赋值方式创建的字符串对象区别? 通过构造方法创建字符串对象是在堆内存. 直接赋值方式创建对象是在方法区的常量池. ==: 基本数据类型,比较的是基本数据类型的值是 ...
- python 全栈开发,Day37(操作系统的发展史)
昨日内容回顾: # C/S和B/S架构 # osi五层模型 # 应用层 # 自定义协议(struct) _ 解决黏包 # 验证客户端合法性 _ hmac os.urandom # 解决TCP协议的se ...
- 读《Top benefits of continuous integration》有感
看到一片文章<Top benefits of continuous integration>,这张图画的很棒.将整个CI流程各阶段,列举出来了. 作者在文章里面介绍了CI和TDD,以及采用 ...