KUDU数据导入尝试一:TextFile数据导入Hive,Hive数据导入KUDU
背景
- SQLSERVER数据库中单表数据几十亿,分区方案也已经无法查询出结果。故:采用导出功能,导出数据到Text文本(文本>40G)中。
- 因上原因,所以本次的实验样本为:【数据量:61w条,文本大小:74M】
选择DataX原因
- 试图维持统一的异构数据源同步方案。(其实行不通)
- 试图进入Hive时,已经是压缩ORC格式,降低存储大小,提高列式查询效率,以便后续查询HIVE数据导入KUDU时提高效率(其实行不通)
1. 建HIVE表
进入HIVE,必须和TextFile中的字段类型保持一致
create table event_hive_3(
`#auto_id` string
,`#product_id` int
,`#event_name` string
,`#part_date` int
,`#server_id` int
,`#account_id` bigint
,`#user_id` bigint
,part_time STRING
,GetItemID bigint
,ConsumeMoneyNum bigint
,Price bigint
,GetItemCnt bigint
,TaskState bigint
,TaskType bigint
,BattleLev bigint
,Level bigint
,ItemID bigint
,ItemCnt bigint
,MoneyNum bigint
,MoneyType bigint
,VIP bigint
,LogID bigint
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS ORC;
2. 建Kudu表
这个过程,自行发挥~
#Idea中,执行单元测试【EventAnalysisRepositoryTest.createTable()】即可
public void createTable() throws Exception {
repository.getClient();
repository.createTable(Event_Sjmy.class,true);
}
3. 建立Impala表
进入Impala-shell 或者hue;
use sd_dev_sdk_mobile;
CREATE EXTERNAL TABLE `event_sjmy_datax` STORED AS KUDU
TBLPROPERTIES(
'kudu.table_name' = 'event_sjmy_datax',
'kudu.master_addresses' = 'sdmain:7051')
4. 编辑Datax任务
不直接load进hive的目的是为了进行一步文件压缩,降低内存占用,转为列式存储。
# 编辑一个任务
vi /home/jobs/textToHdfs.json;
{
"setting": {},
"job": {
"setting": {
"speed": {
"channel": 2
}
},
"content": [
{
"reader": {
"name": "txtfilereader",
"parameter": {
"path": ["/home/data"],
"encoding": "GB2312",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "int"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "int"
},
{
"index": 4,
"type": "int"
},
{
"index": 5,
"type": "long"
},
{
"index": 6,
"type": "long"
},
{
"index": 7,
"type": "string"
},
{
"index": 8,
"type": "long"
},
{
"index": 9,
"type": "long"
},
{
"index": 10,
"type": "long"
},{
"index": 11,
"type": "long"
},{
"index": 12,
"type": "long"
},
{
"index": 13,
"type": "long"
},
{
"index": 14,
"type": "long"
},
{
"index": 15,
"type": "long"
},
{
"index": 17,
"type": "long"
},
{
"index": 18,
"type": "long"
},
{
"index": 19,
"type": "long"
},
{
"index": 20,
"type": "long"
},
{
"index": 21,
"type": "long"
}
],
"fieldDelimiter": "/t"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [{"name":"#auto_id","type":" STRING"},{"name":"#product_id","type":" int"},{"name":"#event_name","type":" STRING"},{"name":"#part_date","type":"int"},{"name":"#server_id","type":"int"},{"name":"#account_id","type":"bigint"},{"name":"#user_id","type":" bigint"},{"name":"part_time","type":" STRING"},{"name":"GetItemID","type":" bigint"},{"name":"ConsumeMoneyNum","type":"bigint"},{"name":"Price ","type":"bigint"},{"name":"GetItemCnt ","type":"bigint"},{"name":"TaskState ","type":"bigint"},{"name":"TaskType ","type":"bigint"},{"name":"BattleLev ","type":"bigint"},{"name":"Level","type":"bigint"},{"name":"ItemID ","type":"bigint"},{"name":"ItemCnt ","type":"bigint"},{"name":"MoneyNum ","type":"bigint"},{"name":"MoneyType ","type":"bigint"},{"name":"VIP ","type":"bigint"},{"name":"LogID ","type":"bigint"}],
"compress": "NONE",
"defaultFS": "hdfs://sdmain:8020",
"fieldDelimiter": "\t",
"fileName": "event_hive_3",
"fileType": "orc",
"path": "/user/hive/warehouse/dataxtest.db/event_hive_3",
"writeMode": "append"
}
}
}
]
}
}
4.1 执行datax任务
注意哦,数据源文件,先放在/home/data下哦。数据源文件必须是个数据二维表。
#textfile中数据例子如下:
{432297B4-CA5F-4116-901E-E19DF3170880} 701 获得筹码 201906 2 4974481 1344825 00:01:06 0 0 0 0 0 0 0 0 0 0 100 2 3 31640
{CAAF09C6-037D-43B9-901F-4CB5918FB774} 701 获得筹码 201906 2 5605253 1392330 00:02:25 0 0 0 0 0 0 0 0 0 0 390 2 10 33865
cd $DATAX_HOME/bin
python datax.py /home/job/textToHdfs.json
效果图:
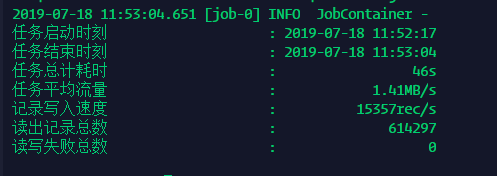
使用Kudu从HIVE读取写入到Kudu表中
进入shell
#进入shell:
impala-shell;
#选中库--如果表名有指定库名,可省略
use sd_dev_sdk_mobile;
输入SQL:
INSERT INTO sd_dev_sdk_mobile.event_sjmy_datax
SELECT `#auto_id`,`#event_name`,`#part_date`,`#product_id`,`#server_id`,`#account_id`,`#user_id`,part_time,GetItemID,ConsumeMoneyNum,Price,GetItemCnt,TaskState,TaskType,BattleLev,Level,ItemID,ItemCnt,MoneyNum,MoneyType,VIP,LogID
FROM event_hive_3 ;
效果图:


看看这可怜的结果
这速度难以接受,我选择放弃。
打脸环节-原因分析:
- DataX读取TextFile到HIVE中的速度慢: DataX对TextFile的读取是单线程的,(2.0版本后可能会提供多线程ReaderTextFile的能力),这直接浪费了集群能力和12核的CPU。且,文件还没法手动切割任务分节点执行。
- Hive到KUDU的数据慢:insert into xxx select * 这个【*】一定要注意,如果读取所有列,那列式查询的优势就没多少了,所以,转ORC多此一举。
- Impala读取HIVE数据时,内存消耗大!
唯一的好处: 降低硬盘资源的消耗(74M文件写到HDFS,压缩后只有15M),但是!!!这有何用?我要的是导入速度!如果只是为了压缩,应该Load进Hive,然后启用Hive的Insert到ORC新表,充分利用集群资源!
代码如下
//1. 数据加载到textfile表中
load data inpath '/home/data/event-19-201906.txt' into table event_hive_3normal;
//2. 数据查询出来写入到ORC表中。
insert into event_hive_3orc
select * from event_hive_3normal
实验失败~
优化思路:1.充分使用集群的CPU资源
2.避免大批量数据查询写入
优化方案:掏出我的老家伙,单Flume读取本地数据文件sink到Kafka, 集群中多Flume消费KAFKA集群,sink到Kudu !下午见!
KUDU数据导入尝试一:TextFile数据导入Hive,Hive数据导入KUDU的更多相关文章
- hive的数据导入与数据导出:(本地,云hdfs,hbase),列分隔符的设置,以及hdfs上传给pig如何处理
hive表的数据源有四种: hbase hdfs 本地 其他hive表 而hive表本身有两种: 内部表和外部表. 而hbase的数据在hive中,可以建立对应的外部表(参看hive和hbase整合) ...
- Hive中数据的导入与导出
最近在做一个小任务,将一个CDH平台中Hive的部分数据同步到另一个平台中.毕竟我也刚开始工作,在正式开始做之前,首先进行了一段时间的练习,下面的内容就是练习时写的文档中的内容.如果哪里有错误或者疏漏 ...
- Hive数据导入——数据存储在Hadoop分布式文件系统中,往Hive表里面导入数据只是简单的将数据移动到表所在的目录中!
转自:http://blog.csdn.net/lifuxiangcaohui/article/details/40588929 Hive是基于Hadoop分布式文件系统的,它的数据存储在Hadoop ...
- hive之数据导入导出
hive数据导入导出 一.导入数据4种方式 建表语句 create table test( name string, friends array, children map<string, in ...
- 效率最高的Excel数据导入---(c#调用SSIS Package将数据库数据导入到Excel文件中【附源代码下载】) 转
效率最高的Excel数据导入---(c#调用SSIS Package将数据库数据导入到Excel文件中[附源代码下载]) 本文目录: (一)背景 (二)数据库数据导入到Excel的方法比较 ...
- 项目总结04:SQL批量导入数据:将具有多表关联的Excel数据,通过sql语句脚本的形式,导入到数据库
将具有多表关联的Excel数据,通过sql语句脚本的形式,导入到数据库 写在前面:本文用的语言是java:数据库是MySql: 需求:在实际项目中,经常会被客户要求,做批量导入数据:一般的简单的单表数 ...
- hive-hbase-handler方式导入hive表数据到hbase表中
Hive与HBase的整合功能的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive-hbase-handler.jar工具类 : hive-hbase-handler.jar在 ...
- rancher导入k8s集群后添加监控无数据
1.日志报错 rancher导入k8s集群后添加监控无数据,rancher日志报错: k8s.io/kube-state-metrics/pkg/collectors/builder.go:: Fai ...
- 用Python的导入csv、文本文件、Excel文件的数据
使用read_csv函数导入CSV文件 read.csv函数语法 read_csv(file,encoding) 例子: Age,Name 22,wangwei 23,lixin 24,liqing ...
随机推荐
- 关于 ESIM 网络的 资料 集合
1.https://blog.csdn.net/wcy23580/article/details/84990923 原理及Python keras 实现 2.https://www.kaggle.co ...
- c 判断一个字符是否为字母
#include <stdio.h> #include <wctype.h> int main () { ; wchar_t str[] = L"C++"; ...
- INNER JOIN连接两个表、三个表、五个表的SQL语句
1.连接两个数据表的用法: FROM Member INNER JOIN MemberSort ON Member.MemberSort=MemberSort.MemberSort 语法格式可以概括为 ...
- Apache搭建简单的图片访问服务器
安装apache后,修改httpd.conf文件 将根目录修改为你图片所在目录 DocumentRoot有这么一行,修改成你要指向的路径 DocumentRoot "/yang/pic&qu ...
- 2018-2019-2 20165330《网络对抗技术》Exp8 Web基础
目录 基础问题 相关知识 实验内容 实验步骤 实验总结与体会 实验内容 Web前端HTML 能正常安装.启停Apache.理解HTML,理解表单,理解GET与POST方法,编写一个含有表单的HTML ...
- .net reflector
https://www.red-gate.com/dynamic/products/dotnet-development/reflector/download https://github.com/s ...
- sentinel备忘
git https://github.com/alibaba/Sentinel https://github.com/dubbo/dubbo-sentinel-supportdubbo http: ...
- Linux 查看网卡速率及版本
查看网卡速率:ethtool 网卡名 如ethtool eth0 查看网卡驱动版本号:ethtool -i 网卡名 如ethtool -i eth0 示例: [root@nt3 ~]# etht ...
- react 实现数据双向绑定
好久没有更新了 只是都写在有道笔记中 今天整理下 一些基础的 大神勿喷 一个基础的不能再基础的数据双向绑定 因为react不同于vue 没有v-model指令 所以怎么实现呢? import Reac ...
- 前端知识点回顾之重点篇——AJAX
Ajax(Asynchronous JavaScript and XML) 这种技术就是无须刷新页面即可从服务器中取得数据,但不一定是XML数据.在原生方法上,Ajax技术的核心是XMLHttpReq ...