MapReduce 框架原理
1. Hadoop 序列化
1.1 自定义Bean对象实现序列化接口
- 必须实现 Writable 接口;
- 反序列化时,需要反射调用空参构造函数,所以必须有空参构造;
- 重写序列化方法;
- 重写反序列化方法;
- 注意反序列化的顺序和序列化的顺序完全一致;
- 要想把结果显示在文件中,需要重写 toString(),可以"\t"分开,方便后续使用;
- 如果需要将自定义的Bean放在KEY中传输,则还需要实现 Comparable 接口,因为 MapReduce 框架中的 Shuffle 过程要求KEY必须能排序。
2. 切片与 MapTask 并行度决定机制
- MapTask 的并行度决定 Map 阶段的任务处理并发度,进而影响到整个 Job 的处理速度;
- MapTask 并行度决定机制
- 数据块:Block 是 HDFS 物理上把数据分成一块一块;
- 数据切片:数据切片只是逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储;
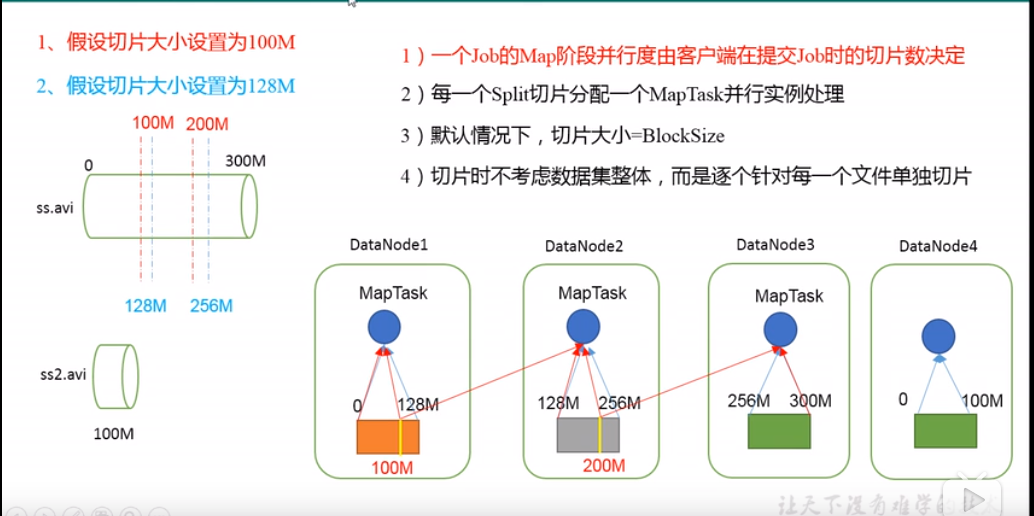
- 一个Job在Map阶段并行度由客户端在提交Job时的切片数决定;
- 每一个Split切片分配一个 MapTask 并行实例处理;
- 默认情况,切片大小=BlockSize;
=======================
3. WordCount 案例
4. FileInputFormat 实现类
- FileInputFormat 常见的接口实现类包括:
TextInputFormat,KeyValueTextInputFormat,NLineInputFormat,CombineTextInputFormat和自定义InputFormat等;
4.1 TextInputFormat
- TextInputFormat 是默认的 FileInputFormat 实现类。按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量, LongWritable 类型。值是这行的内容,不包括任何行终止符(换行符和回车符),Text 类型。
4.2 KeyValueTextInputFormat
- 每一行均为一条记录,被分隔符分割为key,value。可以通过在驱动类中设置
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, "\t");来设定分隔符。默认分隔符是tab(\t);
// 示例 a.txt
line1 Rich learning form
line2 Intelligent learning engine
line3 Learning more convenient
line4 From the real demand for more close to the enterprise
// 切割后的效果,键值对
(line1, Rich learning form)
(line2, Intelligent learning engine)
(line3, Learning more convenient)
(line4, From the real demand for more close to the enterprise)

=======================
4.3 NLineInputFormat
- 如果使用 NLineInputFormat, 代表每个map进程处理的 InputSplit 不再按 Block 块去划分,而是按 NLineInputFormat 指定的行数 N 来划分。即输入文件的总行数/N = 切片数, 如果不整除,切片数=商+1;
4.4 自定义 InputFormat
- 步骤:
- 自定义一个类继承 FileInputFormat;
- 改写 RecordReader,实现一次读取一个完整文件封装为KV;
- 在输出时,使用 SequenceFileOutPutFormat 输出合并文件;
5.OutputFormat 数据输出
- OutputFormat是MapReduce输出的积累,所有实现MapReduce输出都实现了OutputFormat接口。
- 常见实现类:
- TextOutputFormat(文本输出)
- 默认的输出格式。它把每条记录写为文本行。它的键和值可以是任意类型。
- SequenceFileOutputFormat
- 经常作为后续MapReduce任务的输入,因为它的格式紧凑,很容易被压缩。
- 自定义OutputFormat
- 步骤:自定义一个类继承 FileOutputFormat;
- 改写RecordWriter,具体改写输出数据的方法 write();
- TextOutputFormat(文本输出)
MapReduce 框架原理的更多相关文章
- java大数据最全课程学习笔记(6)--MapReduce精通(二)--MapReduce框架原理
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 MapReduce精通(二) MapReduce框架原理 MapReduce工作流程 InputFormat数据 ...
- MapReduce框架原理
MapReduce框架原理 3.1 InputFormat数据输入 3.1.1 切片与MapTask并行度决定机制 1.问题引出 MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个J ...
- Hadoop(18)-MapReduce框架原理-WritableComparable排序和GroupingComparator分组
1.排序概述 2.排序分类 3.WritableComparable案例 这个文件,是大数据-Hadoop生态(12)-Hadoop序列化和源码追踪的输出文件,可以看到,文件根据key,也就是手机号进 ...
- Hadoop(16)-MapReduce框架原理-自定义FileInputFormat
1. 需求 将多个小文件合并成一个SequenceFile文件(SequenceFile文件是Hadoop用来存储二进制形式的key-value对的文件格式),SequenceFile里面存储着多个文 ...
- Hadoop(12)-MapReduce框架原理-Hadoop序列化和源码追踪
1.什么是序列化 2.为什么要序列化 3.为什么不用Java的序列化 4.自定义bean对象实现序列化接口(Writable) 在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop ...
- Hadoop(20)-MapReduce框架原理-OutputFormat
1.outputFormat接口实现类 2.自定义outputFormat 步骤: 1). 定义一个类继承FileOutputFormat 2). 定义一个类继承RecordWrite,重写write ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- Hadoop(13)-MapReduce框架原理--Job提交源码和切片源码解析
1.MapReduce的数据流 1) Input -> Mapper阶段 这一阶段的主要分工就是将文件切片和把文件转成K,V对 输入源是一个文件,经过InputFormat之后,到了Mapper ...
- MapReduce框架原理-MapTask和ReduceTask工作机制
MapTask工作机制 并行度决定机制 1)问题引出 maptask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度.那么,mapTask并行任务是否越多越好呢? 2)MapTa ...
随机推荐
- SIGAI机器学习第十集 线性判别分析
讲授LDA基本思想,寻找最佳投影矩阵,PCA与LDA的比较,LDA的实际应用 前边讲的数据降维算法PCA.流行学习都是无监督学习,计算过程中没有利用样本的标签值.对于分类问题,我们要达到的目标是提取或 ...
- AS400上的binary数据显示不出
1.用DbVisualizer查询,结果免费的版本不支持 DSPFFD查看该table,column的Coded Character Set Identifier(CCSID)是65535,普通的是3 ...
- 重新梳理一下adb操作app(golang版)
主要参考我之前整理的内容https://www.cnblogs.com/pu369/p/10490668.html,梳理简化一下思路,以便于用最简单的代码来应对无聊人士的要求. 需求主要是:打开手机. ...
- springboot项目:以run as-->spring boot app方式启动,配置热部署(亲测可用!!!)
1.在pom.xml中添加热部署依赖 <!-- 热部署 --> <!-- devtools可以实现页面热部署(即页面修改后会立即生效, 这个可以直接在application.prop ...
- webpack项目怎样修改package项目名称
使用vue-cli+webpack创建的项目,修改文件名称或者更改文件的位置,运营时会报错,是因为npm项目,在安装依赖(node_nodules)时,会记录当前的文件路径,当修改之后就无法正常启动. ...
- c实现队列
使用链表实现队列的入队和出队 #include <iostream> #include <stdio.h> #include <string.h> #include ...
- 存在日期类型的JSON数据,进行SpringMVC参数绑定时存在的问题和解决方案
这篇文章已经过时了. 请参考比较合适的前后端交互方式. 首先是发送AJAX请求的html页面 <!DOCTYPE html> <html> <head> <m ...
- Python3使用openpyxl读写Excel文件
Python中常用的操作Excel的三方包有xlrd,xlwt和openpyxl等,xlrd支持读取.xls和.xlsx格式的Excel文件,只支持读取,不支持写入.xlwt只支持写入.xls格式的文 ...
- Atcoder ABC 139E
Atcoder ABC 139E 题意: n支球队大循环赛,每支队伍一天只能打一场,求最少几天能打完. 解法: 考虑抽象图论模型,既然一天只能打一场,那么就把每一支球队和它需要交手的球队连边. 求出拓 ...
- vs.net2017在编辑的wpf的xaml文件引用本程序集下的类提示“找不到”
local对应就是当前exe程序下的类,会提示“...命令空间...找不到...” 因为我调整过生成的,于是尝试调回来anyCPU 问题解决. 看了一下vs.net2017的所在目录"C:\ ...