python网络爬虫(12)去哪网酒店信息爬取
目的意义
爬取某地的酒店价格信息,示例使用selenium在Firefox中的使用。
来源
少部分来源于书。python爬虫开发与项目实战
构造
本次使用简易的方案,模拟浏览器访问,然后输入字段,查找,然后抓取网页中的信息。存储csv中。然后再转换为Excel,并对其中的数据进行二次处理。
代码
整个过程相当于获取网页,下载,然后粗糙的存储过程,最终完成。
不能理解的是,这样是使用了Phantomjs么。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import re
import csv
import time class goWhere():
def __init__(self):
self.toCity=u'焦作'
self.driver=webdriver.Firefox()
self.driver.get("https://hotel.qunar.com/")
self.get_element()
for i in range(30):
self.get_response()
self.parser_store()
self.get_next_page() def get_element(self):
self.elem_toCity=self.driver.find_element_by_name(u"toCity")
self.elem_fromDate=self.driver.find_element_by_name(u"fromDate")
self.elem_toDate=self.driver.find_element_by_name(u"toDate")
self.elem_search=self.driver.find_element_by_class_name('search-btn')
self.elem_toCity.clear()
self.elem_toCity.send_keys(self.toCity)
self.elem_search.click() def get_response(self):
for i in range(5):
try:
WebDriverWait(self.driver,30).until(EC.presence_of_element_located((
By.CLASS_NAME,"item_price")))
break
except Exception as e:
self.driver.refresh()
print(e)
if(i==10):
self.driver.close()
exit()
js="window.scrollTo(0,document.body.scrollHeight);"
self.driver.execute_script(js)
time.sleep(5)
self.all=self.driver.find_elements_by_class_name("b_result_bd")
if(len(self.all)<16 or self.all[0].text==''):
self.driver.refresh()
self.get_response() def parser_store(self):
pattern=re.compile('(.*\s?)')
for each in self.all:
each_text=re.findall(pattern, each.text)
print(each_text)
with open('text.csv','a',encoding='gb18030',newline='') as f:
f_csv=csv.writer(f,)
if len(each_text)==8:
each_text.pop(5)
if len(each_text)==6:
each_text.insert(2,'None')
f_csv.writerow(each_text)
print('finished') def get_next_page(self):
self.nextBtn=self.driver.find_element_by_class_name('next')
self.nextBtn.click() if __name__=='__main__':
goWhere()
print('task finish')
效果举例
二次处理的过程包括处理价格中的??,处理查看地图,处理礼品卡等字段,然后去掉起字,设定价格单元格为人民币格式。
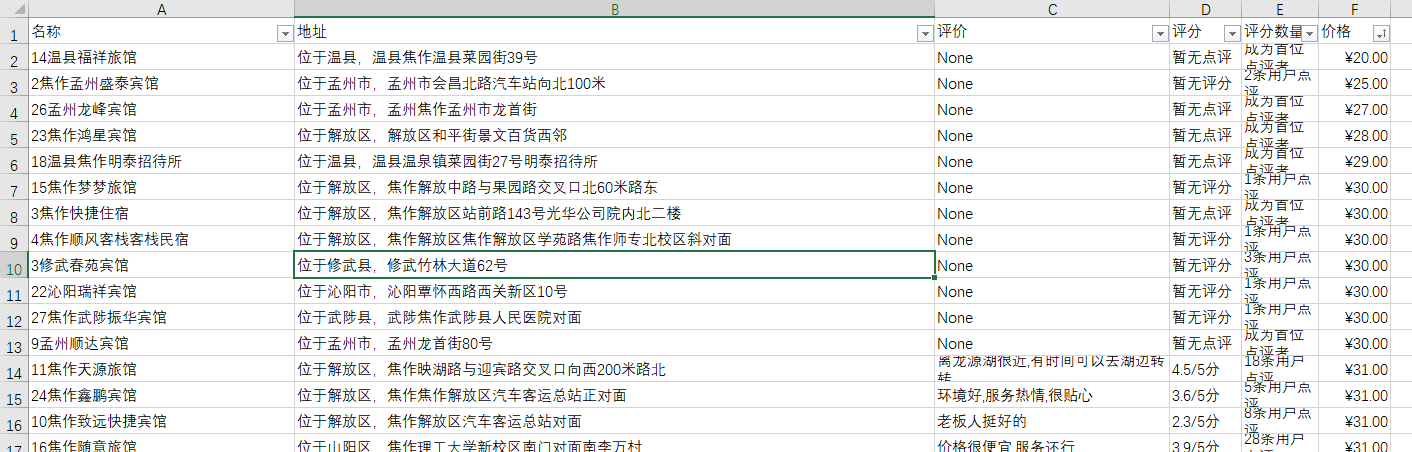
后续
在实际操作过程中,有时网页不容易加载完成,有时加载正常。本次爬取的界面为26个左右共计780余数据。并没有完成数据爬取过程。
python网络爬虫(12)去哪网酒店信息爬取的更多相关文章
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
- Python 爬虫练手项目—酒店信息爬取
from bs4 import BeautifulSoup import requests import time import re url = 'http://search.qyer.com/ho ...
- [Python3网络爬虫开发实战] 7-动态渲染页面爬取
在前一章中,我们了解了Ajax的分析和抓取方式,这其实也是JavaScript动态渲染的页面的一种情形,通过直接分析Ajax,我们仍然可以借助requests或urllib来实现数据爬取. 不过Jav ...
- Python网络爬虫笔记(一):网页抓取方式和LXML示例
(一) 三种网页抓取方法 1. 正则表达式: 模块使用C语言编写,速度快,但是很脆弱,可能网页更新后就不能用了. 2. Beautiful Soup 模块使用Python编写,速度慢. ...
- 《精通Python网络爬虫》|百度网盘免费下载|Python爬虫实战
<精通Python网络爬虫>|百度网盘免费下载|Python爬虫实战 提取码:7wr5 内容简介 为什么写这本书 网络爬虫其实很早就出现了,最开始网络爬虫主要应用在各种搜索引擎中.在搜索引 ...
- Python网络爬虫入门篇
1. 预备知识 学习者需要预先掌握Python的数字类型.字符串类型.分支.循环.函数.列表类型.字典类型.文件和第三方库使用等概念和编程方法. 2. Python爬虫基本流程 a. 发送请求 使用 ...
- 学习推荐《精通Python网络爬虫:核心技术、框架与项目实战》中文PDF+源代码
随着大数据时代的到来,我们经常需要在海量数据的互联网环境中搜集一些特定的数据并对其进行分析,我们可以使用网络爬虫对这些特定的数据进行爬取,并对一些无关的数据进行过滤,将目标数据筛选出来.对特定的数据进 ...
- 【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:掌握定向网络数据爬取和网页解析的基本能力the Website is the API- 1 python ide 文本ide:IDLE,Sublime Text集成ide:Pychar ...
- Python网络爬虫:空姐网、糗百、xxx结果图与源码
如前面所述,我们上手写了空姐网爬虫,糗百爬虫,先放一下传送门: Python网络爬虫requests.bs4爬取空姐网图片Python爬虫框架Scrapy之爬取糗事百科大量段子数据Python爬虫框架 ...
随机推荐
- JDK动态代理、CGLIB动态代理详解
Spring的AOP其就是通过动态代理的机制实现的,所以理解动态代理尤其重要. 动态代理比静态代理的好处: 1.一个动态代理类可以实现多个业务接口.静态代理的一个代理类只能对一个业务接口的实现类进行包 ...
- State Threads之Co-routine的调度
1. 相关结构体 1.1 _st_epoll_data static struct _st_epolldata { _epoll_fd_data_t *fd_data; /* 调用 epoll_wai ...
- 关于colab的一些技巧
1.指定工作文件夹(运行可以相对路径!) # 指定当前的工作文件夹 import os # 此处为google drive中的文件路径,drive为之前指定的工作根目录,要加上 os.chdir(&q ...
- linux出现Redirecting to /bin/systemctl start mysqld.service,解决方法
上去就是一个命令 /bin/systemctl start httpd.service
- vue中如何刷新页面
vue中刷新页面的方法 1. 不能使用 this.$router.go(0) 或者 window.reload() 不起作用还特别恶心 这个才是有效果的刷新页面,只要照图敲,就能有效果 我们在 app ...
- 构建 JVM(HotSpot) 源码调试环境(OpenJDK8)
原本想在 Windows 下编译调试,但过程中遇到了诸多错误(老是报路径错误...),最后只好放弃. 此次记录调试的方法为 CentOS7 上编译,Windows 上使用 Clion 远程调试(也可直 ...
- nvl(sum(字段),0) 的时候,能展示数据0,但是group by 下某个伪列的时候,查不到数据(转载)
今天碰到一个比较有疑惑的问题,就是在统计和的时候,我们往往有时候查不到数据,都会再加个 nvl(sum(字段),0) 来显示这个字段,但是如果我们再加个group by ,就算有加入这个 nvl(nu ...
- Volley源码分析
取消请求的源码分析: public void cancelAll(RequestFilter filter) { synchronized (mCurrentRequests) { for (Requ ...
- 阶段3 3.SpringMVC·_04.SpringMVC返回值类型及响应数据类型_8 响应json数据之响应json格式数据
springMvc的框架已经帮我们做好了.发过来的数据转换为javaBean对象 发过来的键值的形式,如果属性和javaBean对应的话,可以直接封装到对象中. key做额外的转换的时候,需要另外的j ...
- 八十:memcached之安装与参数
Memcached是一个高并发的内存键值对缓存系统,它的主要作用是将数据库查询结果,内容,以及其它一些耗时的计算结果缓存到系统内存中,从而加速Web应用程序的响应速度. 官网:http://memca ...