Hadoop_23_MapReduce倒排索引实现
1.1.倒排索引
根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确
定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(invertedindex)
例如:单词——文档矩阵(将属性值放在前面作为索引)
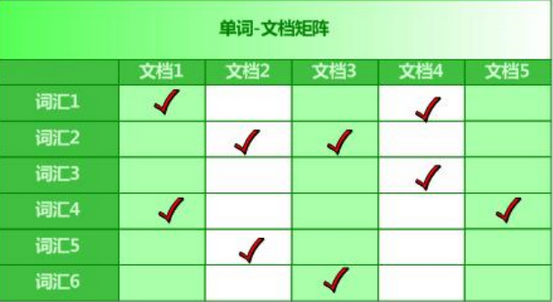
1.2.MapReduce实现倒排索引
需求:对大量的文本(文档、网页),需要建立搜索索引
代码实现:
package cn.bigdata.hdfs.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* 使用MapRedeuce程序建立倒排索引文件
* 文件列表如下:
* a.txt b.txt c.txt
* hello tom hello jerry hello jerry
* hello jerry hello jerry hello tom
* hello tom tom jerry
*/ public class InverIndexStepOne { static class InverIndexStepOneMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
//将得到的每行文本数据根据空格" "进行切分
String [] words = line.split(" "); //根据切片信息获取文件名
FileSplit inputSplit = (FileSplit)context.getInputSplit();
String fileName = inputSplit.getPath().getName();
for(String word : words){
k.set(word + "--" + fileName);
context.write(k, v);
}
}
} static class InverIndexStepOneReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override
protected void reduce(Text key, Iterable<IntWritable> values ,Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable value : values){
count += value.get();
}
context.write(key, new IntWritable(count));
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf); job.setJarByClass(InverIndexStepOne.class); job.setMapperClass(InverIndexStepOneMapper.class);
job.setReducerClass(InverIndexStepOneReducer.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); //输入文件路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true);
}
}
运行结果输出文件:E:\inverseOut\part-r-00000
hello--a.txt 3
hello--b.txt 2
hello--c.txt 2
jerry--a.txt 1
jerry--b.txt 3
jerry--c.txt 1
tom--a.txt 2
tom--b.txt 1
tom--c.txt 1
在原来的基础上进行二次合并,格式如上图单词矩阵,代码实现如下:
package cn.bigdata.hdfs.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 对第一次的输出结果进行合并,使得一个value对应的多个文档记录组成一条完整记录
* @author Administrator
*
*/ public class IndexStepTwo { static class IndexStepTwoMapper extends Mapper<LongWritable, Text, Text, Text>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] files = line.split("--");
context.write(new Text(files[0]), new Text(files[1]));
}
} static class IndexStepTwoReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//定义Buffer缓冲数组
StringBuffer sb = new StringBuffer();
for (Text text : values) {
sb.append(text.toString().replace("\t", "-->") + "\t");
}
context.write(key, new Text(sb.toString()));
}
} public static void main(String[] args) throws Exception{
if (args.length < 1 || args == null) {
args = new String[]{"E:/inverseOut/part-r-00000", "D:/inverseOut2"};
} Configuration config = new Configuration();
Job job = Job.getInstance(config); job.setMapperClass(IndexStepTwoMapper.class);
job.setReducerClass(IndexStepTwoReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 1:0);
}
}
运行结果:
hello c.txt-->2 b.txt-->2 a.txt-->3
jerry c.txt-->1 b.txt-->3 a.txt-->1
tom c.txt-->1 b.txt-->1 a.txt-->2
总结:
对大量的文档建立索引无非就两个过程,一个是分词,另一个是统计分词在每个文档中出现的次数,根据分词在每个文档
中出现的次数建立索引文件,下次搜索词的时候直接查询索引文件,从而返回文档的摘要等信息;
Hadoop_23_MapReduce倒排索引实现的更多相关文章
- Hadoop之倒排索引
前言: 从IT跨度到DT,如今的数据每天都在海量的增长.面对如此巨大的数据,如何能让搜索引擎更好的工作呢?本文作为Hadoop系列的第二篇,将介绍分布式情况下搜索引擎的基础实现,即“倒排索引”. 1. ...
- MapReduce实现倒排索引(类似协同过滤)
一.问题背景 倒排索引其实就是出现次数越多,那么权重越大,不过我国有凤巢....zf为啥不管,总局回应推广是不是广告有争议... eclipse里ctrl+t找接口或者抽象类的实现类,看看都有啥方法, ...
- [Search Engine] 搜索引擎技术之倒排索引
倒排索引是搜索引擎中最为核心的一项技术之一,可以说是搜索引擎的基石.可以说正是有了倒排索引技术,搜索引擎才能有效率的进行数据库查找.删除等操作. 1. 倒排索引的思想 倒排索引源于实际应用中需要根据属 ...
- Lucene 工作原理 之倒排索引
1.简介 倒排索引源于实际应用中需要根据属性的值来查找记录.这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址.由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排 ...
- MapReduce实例-倒排索引
环境: Hadoop1.x,CentOS6.5,三台虚拟机搭建的模拟分布式环境 数据:任意数量.格式的文本文件(我用的四个.java代码文件) 方案目标: 根据提供的文本文件,提取出每个单词在哪个文件 ...
- 倒排索引压缩:改进的PForDelta算法
由于倒排索引文件往往占用巨大的磁盘空间,我们自然想到对数据进行压缩.同时,引进压缩算法后,使得磁盘占用减少,操作系统在query processing过程中磁盘读取效率也能提升.另外,压缩算法不仅要考 ...
- hadoop学习笔记之倒排索引
开发工具:eclipse 目标:对下面文档phone_numbers进行倒排索引: 13599999999 1008613899999999 12013944444444 13800138000137 ...
- 【hadoop2.6.0】倒排索引遇到问题了
想实现书上倒排索引的例子,但是我不会java想用C++写,如果用hadoop streaming 那么输入必须是标准输入的形式, 那么我怎么获得每个文件的文件名呢? 查了一下,还有一种方法叫做hado ...
- hadoop倒排索引
1.前言 学习hadoop的童鞋,倒排索引这个算法还是挺重要的.这是以后展开工作的基础.首先,我们来认识下什么是倒拍索引: 倒排索引简单地就是:根据单词,返回它在哪个文件中出现过,而且频率是多少的结果 ...
随机推荐
- Spring Aop(四)——基于Aspectj注解的Advice介绍
转发地址:https://www.iteye.com/blog/elim-2395315 4 基于Aspectj注解的Advice介绍 之前介绍过,Advice一共有五种类型,分别是before.af ...
- Thinking - 一些有效阅读的方法
有策略,忌盲目.讲方法,别蛮干! 1- 阅读方法 1.1 做好眼前事 排除其他事项干扰,营造适合阅读的状态和环境,专注地投入阅读之中. 如果被一堆乱糟糟的事情烦扰,身心处于一个疲惫的状态,必然无法保持 ...
- mysqlslap 性能测试
--create-schema=name 指定测试的数据库名,默认是mysqlslap --engine=name 创建测试表所使用的存储引擎,可指定多个 --concurrency=N 模拟N个客户 ...
- Linux上安装Julia-1.1
Julia 在Linux上的安装 浙江大学Julia镜像: 浙江大学Julia镜像 下载1.1版本: wget https://mirrors.zju.edu.cn/julia/releases/v1 ...
- 除了 UCAN 发布的鹿班和普惠体,这些设计工具也来自阿里
在 4 月 27 日的 UCAN 2019 设计大会上,阿里巴巴对外发布了一款全新免费字体——阿里巴巴普惠体.其实,作为经济体的阿里巴巴,这些年早已默默推出了很多实用的设计工具,比如大名鼎鼎的 Ico ...
- [Agc030B]Tree Burning_贪心
Tree Burning 题目链接:https://atcoder.jp/contests/agc030/tasks/agc030_b 数据范围:略. 题解: 开始以为是左右左右这样,发现过不去样例. ...
- SQL SERVER YEAR函数
定义: YEAR函数返回指定日期的年的部分 语法: YEAR(date) 参数: ①date参数是合法的日期表达式. 返回值: int型数据 例: 声明:本文是本人查阅网上及书籍等各种资料,再加上自 ...
- Django 用Session和Cookie分别实现记住用户登录状态
简介 由于http协议的请求是无状态的.故为了让用户在浏览器中再次访问该服务端时,他的登录状态能够保留(也可翻译为该用户访问这个服务端其他网页时不需再重复进行用户认证).我们可以采用Cookie或Se ...
- 关于日志slf4j+logback&logback.xml配置
1.maven依赖 <!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-api --> <!-- <dependen ...
- linux 从远程服务器拷贝文件
1.从服务器复制文件到本地: scp root@192.168.1.100:/data/test.txt /home/myfile/ 2.从服务器复制文件夹到本地: scp -r root@192.1 ...