爬虫之获取猫眼电影10W评论
第一步
打开一个电影的评论界面:
哪吒之魔童降世:https://maoyan.com/films/1211270
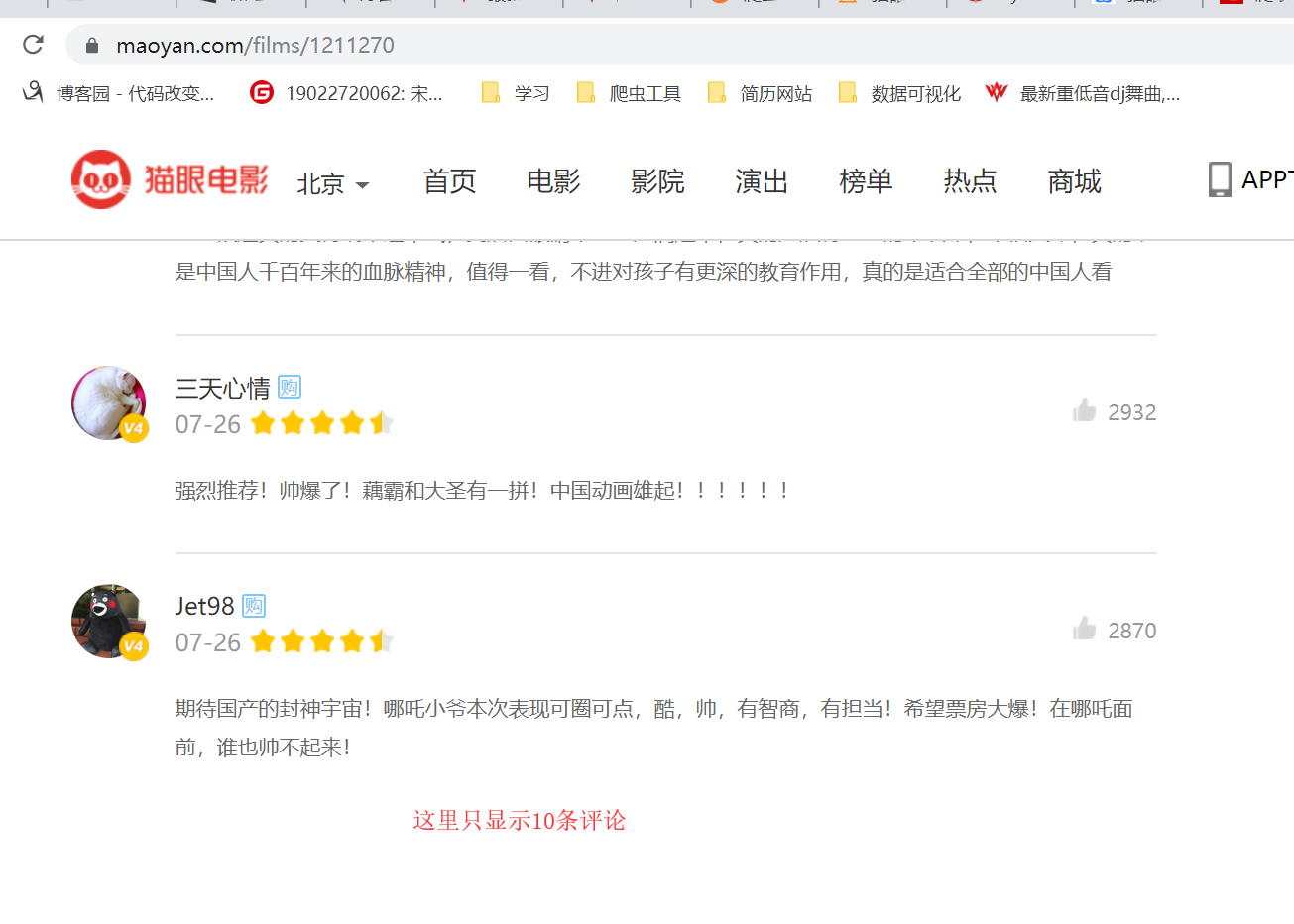
我们发现这里只显示10条评论,而我们需要爬取10w条数据,所以不能从此页面进行抓包,所以放弃!!!!
于是又上网查,终于看到一篇文章说到开发者模式可以直接切换到手机模式;
第二步
切换开发者模式为手机模式
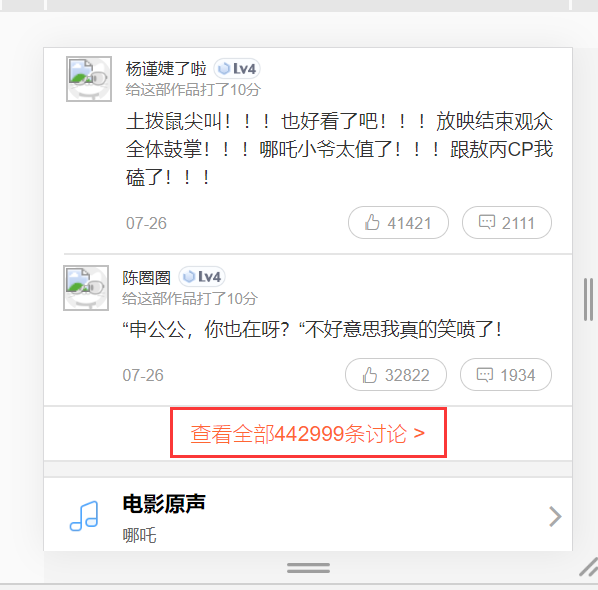
切换模式后可以看到所有评论都显示出来了,我们可以直接抓包进行分析
第三步
点击查看全部讨论
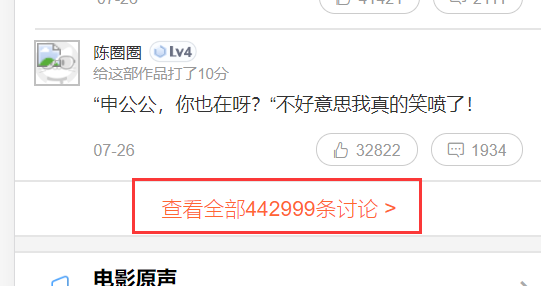
开发者工具切换切换XHR,然后一直下滑查看评论
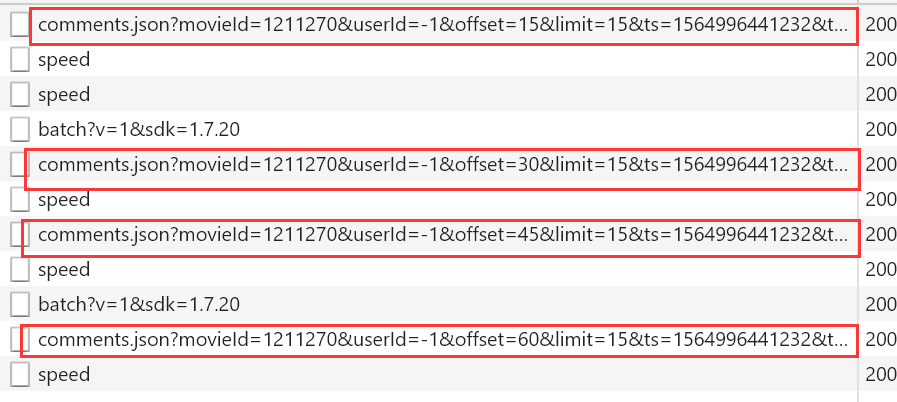
每条请求所对应的数据
http://m.maoyan.com/review/v2/comments.json?movieId=1211270&userId=-1&offset=15&limit=15&ts=1564996441232&type=3 # movieId 表示电影ID
# offset 表示偏移量
# limit 一页显示多少数据
# ts 当前时间戳
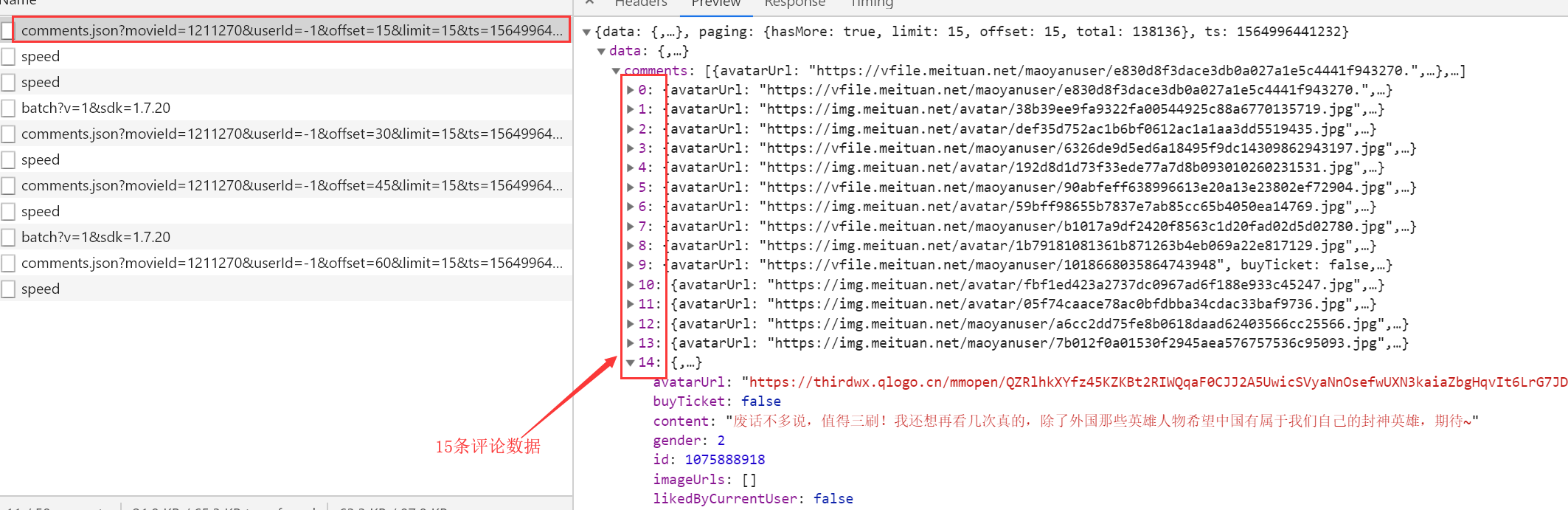
通过多次下滑观察可以看到每次都是offset在变化,而且每次加15,也就是增加15条评论,知道了这个规律其实大家都应该会做了,但是还有个问题,这个方法只能爬取1000条数据,除非改变时间戳,也就是ts,
第四步
我们在上面的方法基础上改变时间戳后发现也只能爬取1000条数据,我们只能另寻他法;
于是我们通过百度知道了有另外一个api可以获得猫眼电影的评论数据
http://m.maoyan.com/mmdb/comments/movie/1211270.json?_v_=yes&offset=0&startTime=2019-08-04%2018:18:53
# 只需要改变startTime,根据时间段来获取评论数据
# 每次获取的评论数据还是15条
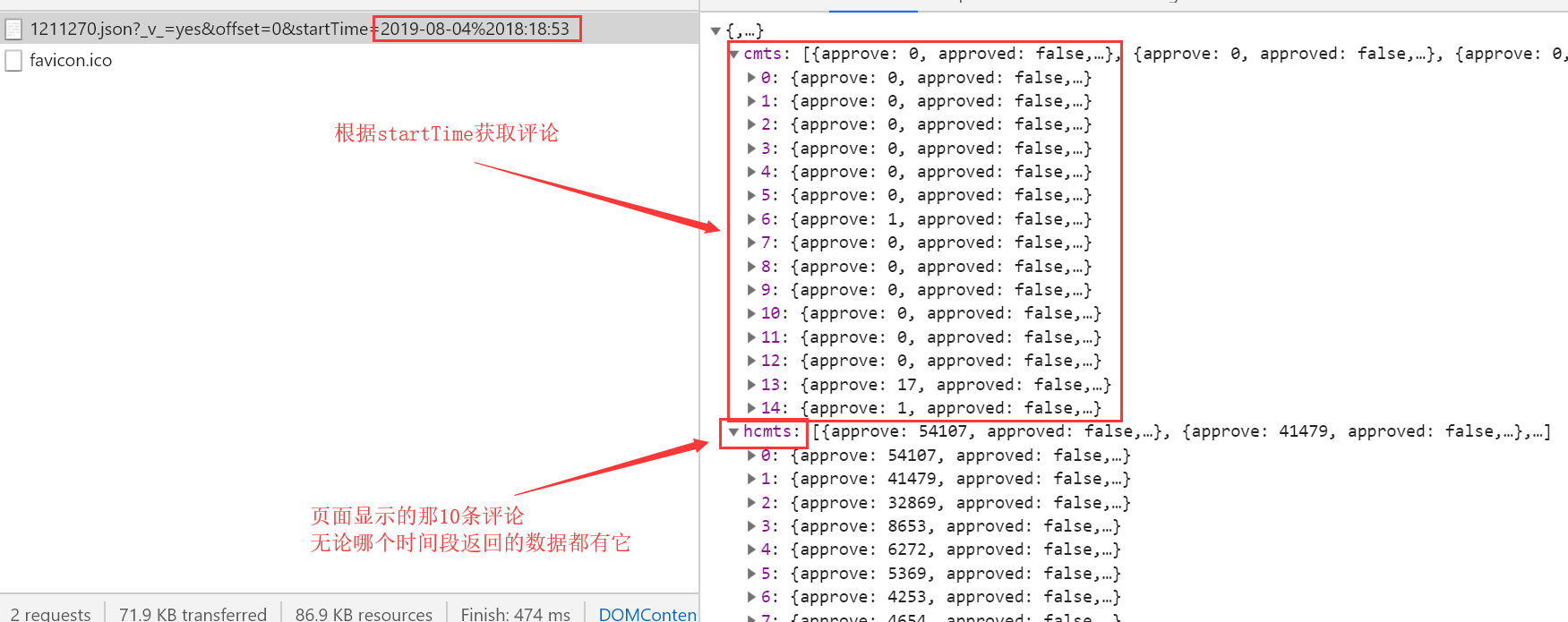
查看每页中最后一条数据的startTime
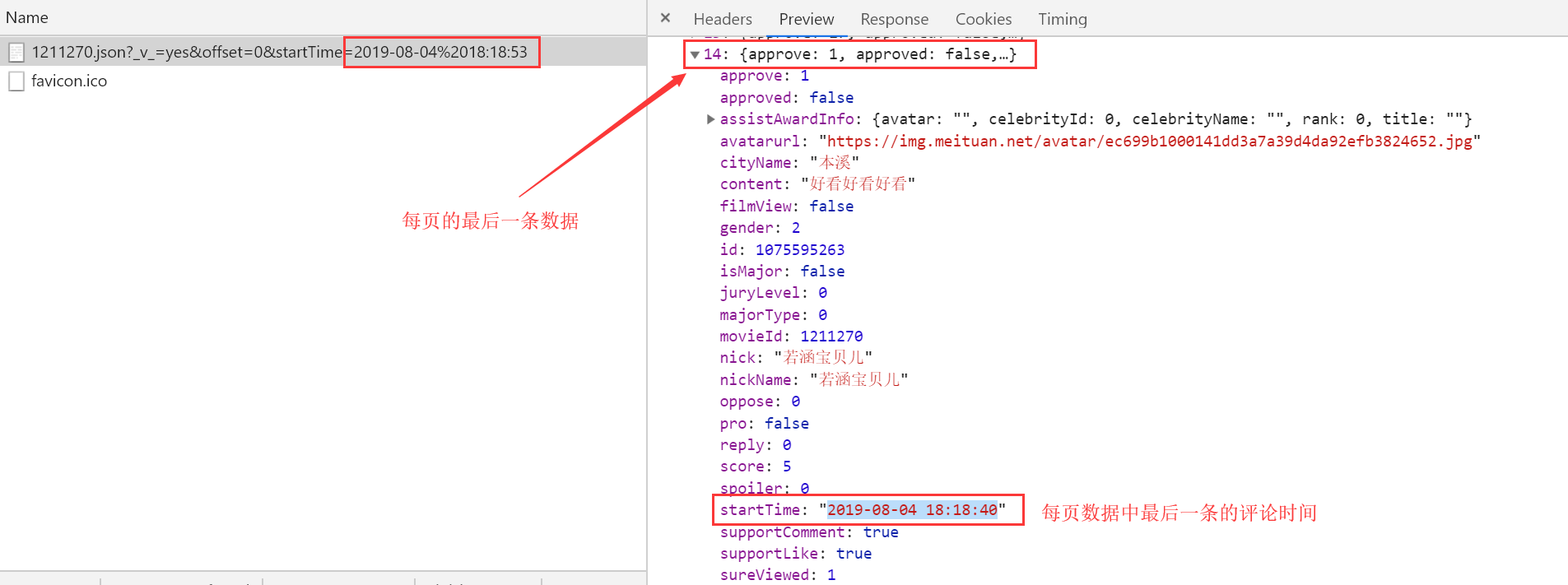
根据上面的原理我们制定爬取方案:
因为我们请求网页所得到的响应数据只用15条,且可以获取到最后一条数据的startTime; 第一次请求url中的startTime我们用当前时间,并获取响应数据中最后一条数据的startTime;
第二次请求时我们将时间替换为第一次请求时响应数据中最后一条数据的startTime,依次类推
直到时间为电影的上映时间即可获取该部电影的所有评论数据;
from pymongo import MongoClient
my_client = MongoClient("127.0.0.1",27017)
MDB = my_client["Movie_rating"] # 指定连接电影评分的库名
print(MDB.Movie_comment.find({}).count()) # 查看表中一共有多少条数据
指定存储数据库
import time
import random
import datetime
import requests
from mongo_db import MDB # 获取当前时间转换为2019/8/5 17:31:15形式空格用%20替换
now_time=datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S').replace(' ','%20') headers = {
'Host': 'm.maoyan.com',
'Referer': 'http://m.maoyan.com/movie/1211270/comments?_v_=yes',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36',
'X-Requested-With': 'superagent',
} time.sleep(random.random()) # 从当前时间往前爬取2000个url的数据,每个url有15条数据
for num in range(1,2000):
url = "http://m.maoyan.com/mmdb/comments/movie/1211270.json?_v_=yes&offset=0&startTime={}".format(now_time)
print("正在下载第{}条评论".format(num))
response = requests.get(url).json()
# 每页的最后一条评论的时间,每次请求后给全局的now_time重新赋值,下次请求时用的时间就是上次响应数据中的最后一条数据的时间
now_time = response["cmts"][-1]["startTime"]
for movie_info in response["cmts"]:
cityName = movie_info["cityName"]
content = movie_info["content"]
user_id = movie_info["id"]
nickName = movie_info["nickName"]
movieId = movie_info["movieId"]
gender = movie_info.get("gender")
if not gender:
gender = "暂无" comment_info = {"cityName":cityName,"nickName":nickName,"user_id":user_id,"movieId":movieId,"gender":gender,"content":content}
# 因为我们创建了唯一索引,所以我们在插入数据时如果有重复的会报错,这里做了异常处理
try:
MDB.Movie_comment.insert_one(comment_info)
except Exception as e:
print(e)
print("所有评论下载完成")
数据下载地址:https://files.cnblogs.com/files/songzhixue/%E7%8C%AB%E7%9C%BC%E7%94%B5%E5%BD%B13w%E6%9D%A1%E8%AF%84%E8%AE%BA%E6%95%B0%E6%8D%AE.rar
共计3w评论下载完成后导入mongodb数据库
时间转换地址:http://tool.chinaz.com/Tools/unixtime.aspx
爬虫之获取猫眼电影10W评论的更多相关文章
- 爬虫实战【4】Python获取猫眼电影最受期待榜的50部电影
前面几天介绍的都是博客园的内容,今天我们切换一下,了解一下大家都感兴趣的信息,比如最近有啥电影是万众期待的? 猫眼电影是了解这些信息的好地方,在猫眼电影中有5个榜单,其中最受期待榜就是我们今天要爬取的 ...
- 利用多进程获取猫眼电影top100
猫眼电影top100 是数据是在加载网页时直接就已经加载了的,所以可以通过requests.get()方法去获取这个url的数据,能过对得到的数据进行分析从而获得top100的数据, 把获取的数据存入 ...
- Python3编写网络爬虫04-爬取猫眼电影排行实例
利用requests库和正则表达式 抓取猫眼电影TOP100 (requests比urllib使用更方便,由于没有学习HTML系统解析库 选用re) 1.目标 抓取电影名称 时间 评分 图片等 url ...
- kettle 利用 HTTP Client 获取猫眼电影API近期上映相关信息,并解析json
前言 Kettle 除了常规的数据处理之外,还可以模拟发送HTTP client/post ,REST client. 实验背景 这周二老师布置了一项实验: 建立一个转换,实现一个猫眼API热映电影的 ...
- python3爬虫爬取猫眼电影TOP100(含详细爬取思路)
待爬取的网页地址为https://maoyan.com/board/4,本次以requests.BeautifulSoup css selector为路线进行爬取,最终目的是把影片排名.图片.名称.演 ...
- <scrapy爬虫>爬取猫眼电影top100详细信息
1.创建scrapy项目 dos窗口输入: scrapy startproject maoyan cd maoyan 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # -*- ...
- requests + 正则表达式 获取 ‘猫眼电影top100’。
使用 进程池Pool 提高爬取数据的速度. 1 # !/usr/bin/python 2 # -*- coding:utf-8 -*- 3 import requests 4 from request ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- Requests+正则表达式 爬取猫眼电影
代码: import re import json from multiprocessing import Pool import requests from requests.exceptions ...
随机推荐
- iOS - App上架流程(复习+已用xcode8)
一.前言: 今天又要上架一款APP,顺便来复习一下APP上架流程 下面就来详细讲解一下具体流程步骤. 二.准备: 一个已付费的开发者账号(账号类型分为个人(Individual).公司(Company ...
- js数组转对象
var obj = {}; var arr = [1,2,3,4,5]; for (var x in arr){ obj[x] = x; } 2.ES6的Object.assign: Object.a ...
- MacOS X GateKeeper Bypass
MacOS X GateKeeper Bypass OVERVIEW On MacOS X version <= 10.14.5 (at time of writing) is it possi ...
- flutter常见编译运行等奇怪问题的汇总汇(l转)
1. flutter ios 卡死在闪屏页:解决办法: 1) flutter doctor 2) flutter clean 3) flutter build ios --release 4) Arc ...
- LInux设置tomcat端口为80
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" ...
- vbox 网络配置
vagrant主机与虚拟机通讯网络有两种模式: config.vm.network "private_network", ip: "192.168.33.10" ...
- ubuntu18.04 安装idea
首先从官网下载idea:IntelliJ IDEA (在安装IDEA前应先安装jdk环境) 得到ideaIU-2019.2.4.tar.gz 将安装包移动到/usr/local,这样可以让所有用 ...
- 深入浅出Git(偏向理论)
目录 一.理论概述 1. 什么是Git 版本控制系统分类 2. GitLab和GitHub是什么 3.Git功能 二.结合具体命令了解其工作 1.环境 2.部署 Git仓库的使用 简单命令解释 Git ...
- linux-修改树莓派分辨率
直接在树莓派下编辑 使用命令行来编辑配置文件 sudo nano /boot/config.txt 并在config.txt文件的最后加上以下代码即可 max_usb_current=1 hdmi_g ...
- Linux 磁盘、分区、文件系统、挂载
磁盘 Linux所有设备都被抽象成为一个文件,保存在/dev目录下. 设备名称一般为hd[a-z]或sd[a-z].如果电脑中有多硬盘,则设备名依次为sda.adb.sdc...以此类推 IDE设备的 ...