MapReduce之自定义分区器Partitioner
@
问题引出
要求将统计结果按照条件输出到不同文件中(分区)。
比如:将统计结果按照手机归属地不同省份输出到不同文件中(分区)
默认Partitioner分区
public class HashPartitioner<K,V> extends Partitioner<K,V>{
public int getPartition(K key,V value, int numReduceTasks){
return (key.hashCode() & Integer.MAX VALUE) & numReduceTasks;
}
}
- 默认分区是根据key的hashCode对ReduceTasks个数取模得到的。
- 用户没法控制哪个key存储到哪个分区。
自定义Partitioner步骤
- 自定义类继承
Partitioner,重写getPartition()方法
public class CustomPartitioner extends Partitioner<Text,FlowBea>{
@Override
public int getPartition(Text key,FlowBean value,int numPartitions){
//控制分区代码逻辑
……
return partition;
}
}
- 在Job驱动类中,设置自定义
Partitioner
job.setPartitionerClass(CustomPartitioner.class)
- 自定义Partition后,要根据自定义Partitioner的逻辑设置相应数量的
ReduceTask
job.setNumReduceTask(5);//假设需要分5个区
Partition分区案例实操
将统计结果按照手机归属地不同省份输出到不同文件中(分区)
输入数据:
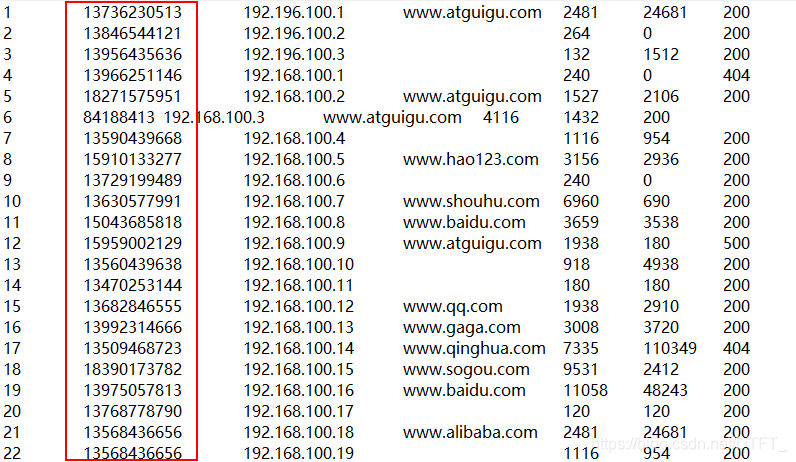
期望输出数据:
手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中。所以总共分为5个文件,也就是五个区。
相比于之前的自定义flowbean,这次自定义分区,只需要多编写一个分区器,以及在job驱动类中设置分区器,mapper和reducer类不改变
MyPartitioner.java
/*
* KEY, VALUE: Mapper输出的Key-value类型
*/
public class MyPartitioner extends Partitioner<Text, FlowBean>{
// 计算分区 numPartitions为总的分区数,reduceTask的数量
// 分区号必须为int型的值,且必须符合 0<= partitionNum < numPartitions
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
String suffix = key.toString().substring(0, 3);//前开后闭,取手机号前三位数
int partitionNum=0;//分区编号
switch (suffix) {
case "136":
partitionNum=numPartitions-1;//由于分区编号不能大于分区总数,所以用这种方法比较好
break;
case "137":
partitionNum=numPartitions-2;
break;
case "138":
partitionNum=numPartitions-3;
break;
case "139":
partitionNum=numPartitions-4;
break;
default:
break;
}
return partitionNum;
}
}
FlowBeanDriver.java
public class FlowBeanDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("e:/mrinput/flowbean");
Path outputPath=new Path("e:/mroutput/partitionflowbean");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(FlowBeanMapper.class);
job.setReducerClass(FlowBeanReducer.class);
// Job需要根据Mapper和Reducer输出的Key-value类型准备序列化器,通过序列化器对输出的key-value进行序列化和反序列化
// 如果Mapper和Reducer输出的Key-value类型一致,直接设置Job最终的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 设置ReduceTask的数量为5
job.setNumReduceTasks(5);
// 设置使用自定义的分区器
job.setPartitionerClass(MyPartitioner.class);
// ③运行Job
job.waitForCompletion(true);
}
}
FlowBeanMapper.java
/*
* 1. 统计手机号(String)的上行(long,int),下行(long,int),总流量(long,int)
*
* 手机号为key,Bean{上行(long,int),下行(long,int),总流量(long,int)}为value
*
*
*
*
*/
public class FlowBeanMapper extends Mapper<LongWritable, Text, Text, FlowBean>{
private Text out_key=new Text();
private FlowBean out_value=new FlowBean();
// (0,1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 200)
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
//封装手机号
out_key.set(words[1]);
// 封装上行
out_value.setUpFlow(Long.parseLong(words[words.length-3]));
// 封装下行
out_value.setDownFlow(Long.parseLong(words[words.length-2]));
context.write(out_key, out_value);
}
}
FlowBeanReducer.java
public class FlowBeanReducer extends Reducer<Text, FlowBean, Text, FlowBean>{
private FlowBean out_value=new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context)
throws IOException, InterruptedException {
long sumUpFlow=0;
long sumDownFlow=0;
for (FlowBean flowBean : values) {
sumUpFlow+=flowBean.getUpFlow();
sumDownFlow+=flowBean.getDownFlow();
}
out_value.setUpFlow(sumUpFlow);
out_value.setDownFlow(sumDownFlow);
out_value.setSumFlow(sumDownFlow+sumUpFlow);
context.write(key, out_value);
}
}
FlowBean.java
public class FlowBean implements Writable{
private long upFlow;
private long downFlow;
private long sumFlow;
public FlowBean() {
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
// 序列化 在写出属性时,如果为引用数据类型,属性不能为null
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
//反序列化 序列化和反序列化的顺序要一致
@Override
public void readFields(DataInput in) throws IOException {
upFlow=in.readLong();
downFlow=in.readLong();
sumFlow=in.readLong();
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
}
输出结果:
总共五个文件
一号区:

二号区:

三号区:

四号区:
其他号码为第五号区:

分区总结
- 如果
ReduceTask的数量 > getPartition的结果数,则会多产生几个空的输出文件part-r-000xx - 如果
Reduceask的数量 < getPartition的结果数,则有一部分分区数据无处安放,会Exception - 如果
ReduceTask的数量 = 1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件partr-00000
以刚才的案例分析:
例如:假设自定义分区数为5,则
- job.setlNlurmReduce Task(1);会正常运行,只不过会产生一个输出文件
- job.setlNlunReduce Task(2),会报错
- job.setNumReduceTasks(6);大于5,程序会正常运行,会产生空文件
MapReduce之自定义分区器Partitioner的更多相关文章
- spark自定义分区器实现
在spark中,框架默认使用的事hashPartitioner分区器进行对rdd分区,但是实际生产中,往往使用spark自带的分区器会产生数据倾斜等原因,这个时候就需要我们自定义分区,按照我们指定的字 ...
- kafka 自定义分区器
package cn.xiaojf.kafka.producer; import org.apache.kafka.clients.producer.Partitioner; import org.a ...
- 关于MapReduce中自定义分区类(四)
MapTask类 在MapTask类中找到run函数 if(useNewApi){ runNewMapper(job, splitMetaInfo, umbilical, reporter ...
- Parallel中分区器Partitioner的简单使用
Partitioner.Create(1,10,4).GetDynamicPartitions() 为长度为10的序列创建分区,每个分区至多4个元素,分区方法及结果:Partitioner.Creat ...
- Spark源码分析之分区器的作用
最近因为手抖,在Spark中给自己挖了一个数据倾斜的坑.为了解决这个问题,顺便研究了下Spark分区器的原理,趁着周末加班总结一下~ 先说说数据倾斜 数据倾斜是指Spark中的RDD在计算的时候,每个 ...
- 玩转Kafka的生产者——分区器与多线程
上篇文章学习kafka的基本安装和基础概念,本文主要是学习kafka的常用API.其中包括生产者和消费者, 多线程生产者,多线程消费者,自定义分区等,当然还包括一些避坑指南. 首发于个人网站:链接地址 ...
- kafka producer partitions分区器(七)
消息在经过拦截器.序列化后,就需要确定它发往哪个分区,如果在ProducerRecord中指定了partition字段,那么就不再需要partitioner分区器进行分区了,如果没有指定,那么会根据k ...
- RDD(六)——分区器
RDD的分区器 Spark目前支持Hash分区和Range分区,用户也可以自定义分区,Hash分区为当前的默认分区,Spark中分区器直接决定了RDD中分区的个数.RDD中每条数据经过Shuffle过 ...
- Spark分区器浅析
分区器作用:决定该数据在哪个分区 概览: 仅仅只有pairRDD才可能持有分区器,普通RDD的分区器为None 在分区器为None时RDD分区一般继承至父RDD分区 初始RDD分区数: 由集合创建,R ...
随机推荐
- 利用synchronized解析死锁的一种形成方式
代码 import ... public class Test{ private static Object o1=new Object(); private static Object o2=new ...
- 第七模块 :微服务监控告警Prometheus架构和实践
119.监控模式分类~1.mp4 logging:日志监控,Logging 的特点是,它描述一些离散的(不连续的)事件. 例如:应用通过一个滚动的文件输出 Debug 或 Error 信息,并通过日志 ...
- 虚拟机VMware克隆之后网络不可用的解决办法
现在有两台虚拟机,113是111的克隆,要让113能够使用,需要做下面的修改 5.解决办法5.1.修改克隆后机器(B机器)70-persistent-net.rules文件内容 对克隆后机器(B机器) ...
- Python三大器之生成器
Python三大器之生成器 生成器初识 什么是生成器 生成器本身属于迭代器.继承了迭代器的特性,惰性求值,占用内存空间极小. 为什么要有生成器 我们想使用迭代器本身惰性求值的特点创建出一个可以容纳百万 ...
- HDU 5969 最大的位或【贪心】
题目 B君和G君聊天的时候想到了如下的问题. 给定自然数l和r ,选取2个整数x,y满足l <= x <= y <= r ,使得x|y最大. 其中|表示按位或,即C. C++. Ja ...
- P5774 [JSOI2016]病毒感染
题目描述 JOSI 的边陲小镇爆发了严重的 Jebola 病毒疫情,大批群众感染生命垂危.计算机科学家 JYY 采用最新的算法紧急研制出了 Jebola 疫苗,并火速前往灾区救治患者. 一共有 NN ...
- 你真的了解CSS继承吗?看完必跪
也许你瞧不起以前的 css ,但是你不该再轻视眼下的 css .近年来 css 的变量系统已逐步得到各大浏览器厂商支持,自定义选择器等强势袭来,嵌套系统/模块系统也在路上…为了更好的掌握 css 这门 ...
- Lists.newArrayList() 和 new ArrayList()的区别?
什么是创建List字符串的最好构造方法?是Lists.newArrayList()还是new ArrayList()? 还是个人喜好? Lists和Maps是两个工具类, Lists.newArray ...
- 调整数组顺序使奇数位于偶数前面(剑指offer-13)
方法1:新建两个数组,一个数组用来放奇数,一个数组用来放偶数,最后再把它们合并起来. 1 import java.util.*; 2 public class Solution { 3 public ...
- MyBatis源码分析(一)
MyBatis故事: 官方网站:http://www.mybatis.org 官方文档:http://www.mybatis.org/mybatis-3/ GitHub:https://github. ...