Scrapy框架的架构原理解析
爬虫框架——Scrapy
如果你对爬虫的基础知识有了一定了解的话,那么是时候该了解一下爬虫框架了。那么为什么要使用爬虫框架?
- 学习框架的根本是学习一种编程思想,而不应该仅仅局限于是如何使用它。从了解到掌握一种框架,其实是对一种思想理解的过程。
- 框架也给我们的开发带来了极大的方便。许多条条框框都已经是写好了的,并不需要我们重复造轮子,我们只需要根据自己的需求定制自己要实现的功能就好了,大大减少了工作量。
- 参考并学习优秀的框架代码,提升编程代码能力
scrapy框架的介绍
比较流行的爬虫的框架有scrapy和pyspider,但是被大家所钟爱的我想非scrapy莫属了。scrapy是一个开源的高级爬虫框架,我们可以称它为"scrapy语言"。它使用python编写,用于爬取网页,提取结构性数据,并可将抓取得结构性数据较好的应用于数据分析和数据挖掘。scrapy有以下的一些特点:
scrapy基于事件的机制,利用twisted的设计实现了非阻塞的异步操作。这相比于传统的阻塞式请求,极大的提高了CPU的使用率,以及爬取效率。- 配置简单,可以简单地通过设置一行代码实现复杂功能。
- 可拓展,插件丰富,比如分布式scrapy + redis、爬虫可视化等插件。
- 解析方便易于使用,scrapy封装了xpath等解析器,提供了更方便,更高级的selector构造器,可以有效的处理破损的HTML代码和编码。
scrapy的架构

组件
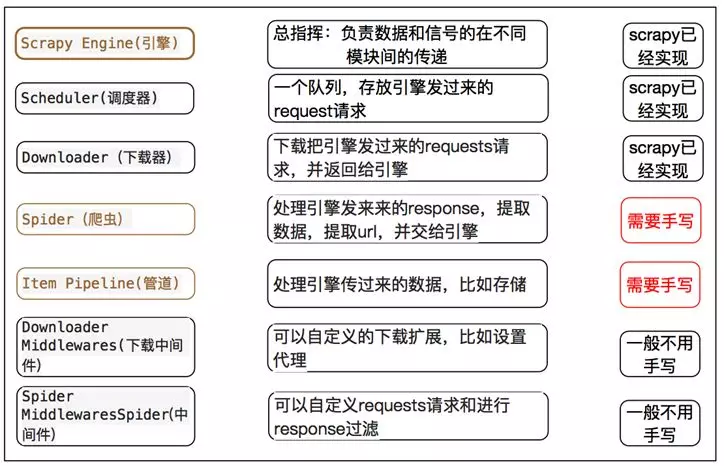
引擎(Engine)
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
爬虫(Spiders)
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
项目管道(Item Pipeline)
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
爬虫中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
数据流过程
- 引擎打开一个网站
(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。 - 引擎从
Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。 - 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求
(request)方向)转发给下载器(Downloader)。 - 一旦页面下载完毕,下载器生成一个该页面的
Response,并将其通过下载中间件(返回(response)方向)发送给引擎。 - 引擎从下载器中接收到
Response并通过Spider中间件(输入方向)发送给Spider处理。 Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。- 引擎将(Spider返回的)爬取到的Item给
Item Pipeline,将(Spider返回的)Request给调度器。 - (从第二步)重复直到调度器中没有更多地
request,引擎关闭该网站。
scrapy和requests+bs用哪个好?
这个根据自己方便来,requests + beautifulsoup当然可以了,requests + 任何解器式都行,都是非常好的合作。这样用的有点是我们可以灵活地写我们自己的代码,不必拘泥于固定模式。对于使用固定的框架有时候不一定用起来方便,比如scrapy对于反反爬处理并没有很完善,好多时候也要自己来解决。
但是对于一些中小型的爬虫任务来讲,scrapy确实是非常好的选择,它避免了我们来写一些重复的代码,并且有着出色的性能。我们自己写代码的时候,比如为了提高爬取效率,每次都自己码多线程或异步等代码,大大浪费了开发时间。这时候使用已经写好的框架是再好不过的选择了,我们只要简单的写写解析规则和pipeline就好了。那么具体哪些是需要我们做的呢?看看下面这个图就明白了。
Scrapy框架的架构原理解析的更多相关文章
- RocketMQ架构原理解析(四):消息生产端(Producer)
RocketMQ架构原理解析(一):整体架构 RocketMQ架构原理解析(二):消息存储(CommitLog) RocketMQ架构原理解析(三):消息索引(ConsumeQueue & I ...
- RocketMQ架构原理解析(一):整体架构
RocketMQ架构原理解析(一):整体架构 RocketMQ架构原理解析(二):消息存储(CommitLog) RocketMQ架构原理解析(三):消息索引(ConsumeQueue & I ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Python之爬虫(十四) Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Tomcat 架构原理解析到架构设计借鉴
Tomcat 发展这么多年,已经比较成熟稳定.在如今『追新求快』的时代,Tomcat 作为 Java Web 开发必备的工具似乎变成了『熟悉的陌生人』,难道说如今就没有必要深入学习它了么?学习它我们又 ...
- Python爬虫-Scrapy框架的工作原理
Scrapy框架工作原理 Scrapy框架架构图 Scrapy框架主要由六大组件组成,分别为: 调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwa ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- Scrapy框架的执行流程解析
这里主要介绍七个大类Command->CrawlerProcess->Crawler->ExecutionEngine->sceduler另外还有两个类:Request和Htt ...
- RocketMQ架构原理解析(三):消息索引
一.概述 "索引"一种数据结构,帮助我们快速定位.查询数据 前文我们梳理了消息在Commit Log文件的存储过程,讨论了消息的落盘策略,然而仅仅通过Commit Log存储消息是 ...
随机推荐
- golang的树结构三种遍历方式
package main import "log" type node struct { Item string Left *node Right *node } type bst ...
- vue跳转页面问题记录
跳转到别的页面带参数 const space = this.pageHelperspace['search'] = this.searchconst query_params = Object.ass ...
- next()与nextLine()的区别
abc def ghij kl mno pqr st uvw xyz 你用next(),第一次取的是abc,第二次取的是def,第三次取的是ghij 你用nextLine(),第一次取的是abc de ...
- noip复习——逆元
逆元,即对给定\(a,p\ (a \perp p)\),求\(x\)使得\(ax \equiv 1 \ (\bmod p)\) 逆元可以看做\(a\)在模\(p\)意义下的\(a^{-1}\).因此, ...
- xss-labs 通关学习笔记
xss-labs 学习 By:Mirror王宇阳 time:2020/04/06 level1 我们进入到这个页面之后,快速关注到几个点,Xss注重的输入点,这里的输入点首先在URL栏中找到了name ...
- DP搬运工1 [来自yyy--mengbier的预设型dp]
DP搬运工1 题目描述 给你 \(n,K\) ,求有多少个 \(1\) 到 \(n\) 的排列,满足相邻两个数的 \(max\) 的和不超过 \(K\). 输入格式 一行两个整数 \(n,K\). 输 ...
- java程序CPU 100%调试
前置 PID为进程id,NID为线程ID 步骤一.找到最耗CPU的进程 top 然后键入P,按CPU占用率排序(M是按内存排序) 步骤二.找到进程中最耗CPU的线程 top -Hp PID 步骤三.将 ...
- golang container/list 使用
原文链接:http://cngolib.com/container-list.html(中文),https://golang.org/pkg/container/list/(英文) 示例: packa ...
- Kernel methods on spike train space for neuroscience: a tutorial
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 时序点过程:http://www.tensorinfinity.com/paper_154.html Abstract 在过去的十年中,人 ...
- 区块链入门到实战(29)之Solidity – 环境搭建
在线开发环境Remix(推荐) 学习Solidity推荐使用在线开发环境Remix,本教程的例子将使用Remix开发运行. 安装本地编译器 安装 nodejs / npm node官方网站下载node ...