图像Resize方式对深度学习模型效果的影响
在基于卷积神经网络的应用过程中,图像Resize是必不可少的一个步骤。通常原始图像尺寸比较大,比如常见监控摄像机出来的是1080P高清或者720P准高清画面,而网络模型输入一般没有这么大,像Yolo系列目标检测的网络模型输入大小一般为608*608/512*512 等等。那么如何将大尺寸图像输入到网络模型呢?很容易想到的一个方法就是对原始图像进行Resize,将1920*1080的原始图像Resize到网络模型输入尺寸,比如608*608。在压缩图像的过程中,有以下两个问题需要重点讨论:
1、图像Resize前后,是否应该保持宽高比例一致?图像内容变形是否对模型效果有影响
2、图像Resize过程,应该选择什么样的插值方式?
对于第一个问题,其实两种方式均可,前提是要保证模型训练和模型推理时的操作方式一致。也就是说,如果在网络模型训练时,所有的训练素材都是直接拉伸到网路的输入尺寸(不保持宽高比例),那么模型推理时也应该如此,反之亦然。其中保持宽高比例的做法一般是用增加padding的方式,然后用固定颜色填充,保证图像画面中部的内容不变形。下图说明两种方式的差异:

图1 是否保持宽高比
其实对于网络模型来讲,图像是否变形其实不太重要。如果在训练的时候,模型认为一个变形的动物是猫,那么经过大量数据拟合后,在推理阶段,它同样会正确识别出变形的目标。当然根据相关资料显示,通常一般推荐使用直接拉伸的方式去做图像Resize,原因是增加padding填充后会对网络带来一定噪音,影响模型准确性,具体影响有多大我目前没有具体数据证明。这里需要指出的是,一些算法应用框架对细节封装得太好,对原始图像进行Resize的过程被隐藏起来,具体Resize的方式也不得而知。如果你发现模型集成后的准确性下降严重,这时候就需要检查一下框架对图像Resize的方式跟我们模型训练时是否一致。
对于第二个问题,图像Resize过程应该选择什么插值方式?如果对插值不太了解的朋友可以上网搜索一下。这里简单介绍一下图像插值的含义:我们在对图像进行上下采样时(缩放),有时候要在原有像素基础上删除一些像素值(缩小),有时候要在原有像素基础上增加一些像素值(放大),增加/删除像素的方式叫图像插值算法。对OpenCV比较熟悉的朋友可能知道它里面的Resize函数其实有一个‘插值模式’的参数,这个参数有一个默认值:INTER_LINER线性插值。它是一种插值方式,如果你在调用Resize函数时没有修改该参数值,那么该函数就以“线性插值”的方式进行图像缩放。除此之外,还有其他的一些插值方式,每种插值算法的区别请具体参考OpenCV文档。
图2 插值示意图
通过上面的介绍,图像在进行Resize操作时,本质上是改变数字图像矩阵大小和矩阵内容,Resize时采用不同的插值方式最终会得到不同的结果(这里说的结果是指微观上像素矩阵,可能肉眼查看画面差别不大)。那么在深度学习应用过程中,我们应该采用什么样的插值方式呢?经过实际测试验证,不管用哪种方式进行插值,模型训练阶段对图像Resize的插值方式跟模型推理阶段对图像Resize的插值方式最好能保持一致,前后两个阶段不同的插值方式确实会影响最终模型的效果。
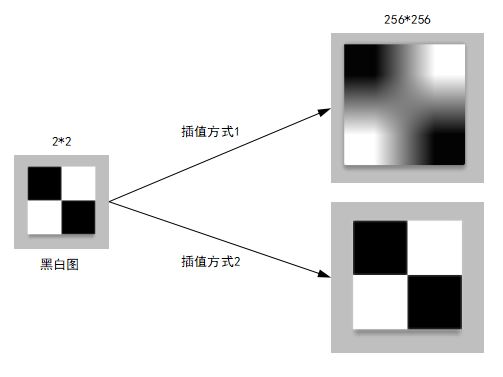
图3 不同插值结果
除了Resize插值方式应该保持一致之外,Resize的次数最好也能保持统一,如果在模型训练阶段,我们将原始图像素材从1000*800缩放到400*400,然后输入网络进行训练,那么我们在模型推理阶段,同样应该将原始图像以相同的插值方式一次性缩放到400*400,然后输入网络进行推理。之所以强调一次性缩放,因为有些算法应用框架在做图像预处理时隐藏了图像缩放的细节,有可能不止一次缩放操作,比如先将原图缩放到800*800,然后再进行二次缩放,最终变成400*400,虽然两次用到的插值方式都跟模型训练阶段保持一致,但是由于进行了两次操作,还是会影响最终推理效果。
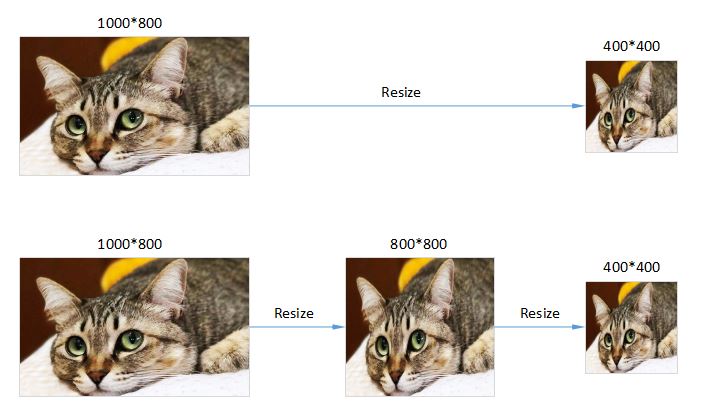
图4 缩放次数不一致
最后总结一下图像缩放方式对模型效果的影响:在模型训练和模型推理阶段,应保持相同的图像预处理方式,这样才能充分发挥模型的推理效果。原因很简单,模型训练的过程就是寻找数据集规律的过程,如果训练用到的和实际推理的数据规律不一样,必然会影响模型效果。当然,本文虽然讨论图像缩放的不同方式对模型效果有影响,但是由于深度学习是一个基于大量数据统计的过程,在有大量数据拟合的情况下,这种影响可能相对来讲并不大,如果你非常在意(或者实际观察发现影响非常大),那么本文讲到的问题可能对你有帮助。
图像Resize方式对深度学习模型效果的影响的更多相关文章
- Opencv调用深度学习模型
https://blog.csdn.net/lovelyaiq/article/details/79929393 https://blog.csdn.net/qq_29462849/article/d ...
- AI佳作解读系列(一)——深度学习模型训练痛点及解决方法
1 模型训练基本步骤 进入了AI领域,学习了手写字识别等几个demo后,就会发现深度学习模型训练是十分关键和有挑战性的.选定了网络结构后,深度学习训练过程基本大同小异,一般分为如下几个步骤 定义算法公 ...
- 『高性能模型』Roofline Model与深度学习模型的性能分析
转载自知乎:Roofline Model与深度学习模型的性能分析 在真实世界中,任何模型(例如 VGG / MobileNet 等)都必须依赖于具体的计算平台(例如CPU / GPU / ASIC 等 ...
- 利用 TFLearn 快速搭建经典深度学习模型
利用 TFLearn 快速搭建经典深度学习模型 使用 TensorFlow 一个最大的好处是可以用各种运算符(Ops)灵活构建计算图,同时可以支持自定义运算符(见本公众号早期文章<Tenso ...
- Roofline Model与深度学习模型的性能分析
原文链接: https://zhuanlan.zhihu.com/p/34204282 最近在不同的计算平台上验证几种经典深度学习模型的训练和预测性能时,经常遇到模型的实际测试性能表现和自己计算出的复 ...
- PyTorch如何构建深度学习模型?
简介 每过一段时间,就会有一个深度学习库被开发,这些深度学习库往往可以改变深度学习领域的景观.Pytorch就是这样一个库. 在过去的一段时间里,我研究了Pytorch,我惊叹于它的操作简易.Pyto ...
- Apple的Core ML3简介——为iPhone构建深度学习模型(附代码)
概述 Apple的Core ML 3是一个为开发人员和程序员设计的工具,帮助程序员进入人工智能生态 你可以使用Core ML 3为iPhone构建机器学习和深度学习模型 在本文中,我们将为iPhone ...
- 深度学习模型调优方法(Deep Learning学习记录)
深度学习模型的调优,首先需要对各方面进行评估,主要包括定义函数.模型在训练集和测试集拟合效果.交叉验证.激活函数和优化算法的选择等. 那如何对我们自己的模型进行判断呢?——通过模型训练跑代码,我们可以 ...
- TVM将深度学习模型编译为WebGL
使用TVM将深度学习模型编译为WebGL TVM带有全新的OpenGL / WebGL后端! OpenGL / WebGL后端 TVM已经瞄准了涵盖各种平台的大量后端:CPU,GPU,移动设备等.这次 ...
随机推荐
- Google & Chrome console & text adventure game
Google & Chrome console & text adventure game Google's text adventure game https://www.googl ...
- vue农历日历
<template> <div class="calendar-main"> <div class="choose_year"&g ...
- Flutter: 使用相机拍照
文档 camera import 'dart:io'; import 'package:camera/camera.dart'; import 'package:flutter/material.da ...
- iOS拍照定制之AVCapturePhotoOutput
问题 领导安排任务,写个拍照功能,界面跟系统拍照有点出入 拍完照片,底部显示已拍照片,有个拍照上限[在此不论] 点击已拍照片,可以预览.放大缩小查看 思路 系统拍照肯定不行了,只能定制,没提是否拍照禁 ...
- 【SpringMVC】 4.3 拦截器
SpringMVC学习记录 注意:以下内容是学习 北京动力节点 的SpringMVC视频后所记录的笔记.源码以及个人的理解等,记录下来仅供学习 第4章 SpringMVC 核心技术 4.3 拦截器 ...
- FTP服务器搭建以及上传下载的学习
首先需要搭建FTP服务步骤如下: 1.在win7上先开启ftp服务:这里点击确定后,可能会要等一会儿,完成后有时系统会提示重启 2.打开 计算机-->管理--> 在这里我们可以看见 ...
- 微信小程序:将yyyy-mm-dd格式的日期转换成yyyy-mm-dd hh:mm:ss格式的日期
代码如下: changeDate1(e) { console.log(e); var date = new Date(e.detail.value); console.log(date); const ...
- getter和setter以及defineProperty的用法
getter 和 setter 和 defineProperty getter:将对象属性绑定到查询该属性时将被调用的函数 说人话就是,当你调用一个getter属性时会调用定义好的get函数,这个函数 ...
- Vue前端项目的搭建流程
1. 安装Vue和Nodejs 2. 创建项目 vue create eduonline-web
- Kubernetes-7.Ingress
docker version:20.10.2 kubernetes version:1.20.1 本文概述Kubernetes Ingress基本原理和官方维护的Nginx-Ingress的基本安装使 ...