spark 系列之一 RDD的使用
spark中常用的两种数据类型,一个是RDD,一个是DataFrame,本篇主要介绍RDD的一些应用场景见代码
本代码的应用场景是在spark本地调试(windows环境)
/**
* 创建 sparkSession对象
*/
val sparkSession = SparkSession.builder()
.appName("TextFile")
.master("local")
.getOrCreate()
word.txt 的文本内容如下
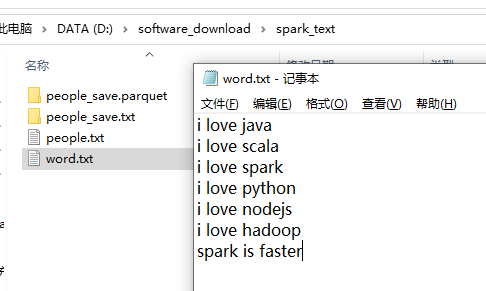
wordcount:三个算子搞定 flatMap 是把数据打平,map是对打平的数据每个计数一,reduceBykey是按照key进行分类汇总。
/**
* wordCount 程序,三个算子搞定
*/
val peopleRDD1 = sparkSession.sparkContext
.textFile("file:///D:/software_download/spark_text/word.txt")
.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.reduceByKey((a,b)=>a+b) peopleRDD1.foreach(println)
Result:
(scala,1)
(faster,1)
(is,1)
(spark,2)
(hadoop,1)
(love,6)
(i,6)
(python,1)
(nodejs,1)
(java,1)
按照key进行分组
/**
* 分组
*/
val peopleRDD2 = sparkSession.sparkContext
.textFile("file:///D:/software_download/spark_text/word.txt")
.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.groupByKey()
peopleRDD2.foreach(println)
Result:
(scala,CompactBuffer(1))
(spark,CompactBuffer(1, 1))
(is,CompactBuffer(1))
(faster,CompactBuffer(1))
(hadoop,CompactBuffer(1))
(love,CompactBuffer(1, 1, 1, 1, 1, 1))
(i,CompactBuffer(1, 1, 1, 1, 1, 1))
(python,CompactBuffer(1))
(nodejs,CompactBuffer(1))
(java,CompactBuffer(1))
遍历RDD的keys和values,RDD中存放的是一个个对象,这点跟DataFrame不同,RDD中的对象对外的表现是黑盒的,即你不知道RDD中具体的字段是什么。DataFrame则不同,你可以清晰的看到DataFrame中所存放对象的内部结构。
/**
* RDD keys与values的遍历
*/ peopleRDD1.keys.foreach(println)
peopleRDD1.values.foreach(println)
Result:
scala
faster
is
spark
hadoop
love
i
python
nodejs
java
1
1
1
2
1
6
6
1
1
1
RDD 的其它操作,
/**
* 只针对value的值进行操作,以下两种操作等效,都是对key值加1操作
*/
peopleRDD1.sortByKey().map(x=>(x._1,x._2+1)).foreach(println)
peopleRDD1.sortByKey().mapValues(x=>x+1).foreach(println)
//按照value值进行排序
peopleRDD1.sortBy(x=>x._2,ascending = true).foreach(println)
//按照key值进行排序
peopleRDD1.sortByKey(ascending = true).foreach(println)
/**
* RDD之间的join操作
*/
val pairRDD1 = sparkSession.sparkContext.parallelize(Array(("spark",1),("spark",2),("hadoop",3),("hadoop",5)))
val pairRDD2 = sparkSession.sparkContext.parallelize(Array(("spark","fast")))
val RDD1_join_RDD2 = pairRDD1.join(pairRDD2)
RDD1_join_RDD2.foreach(println)
思考题: 求该rdd,按照key进行分组后,value值得平均值,答案如下。
求:写代码
val rdd = sparkSession.sparkContext.parallelize(Array(("spark",2),("hadoop",6),("hadoop",4),("spark",6)))
Result:
(spark,4)
(hadoop,5)
spark 系列之一 RDD的使用的更多相关文章
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的缓存(八)
RDD的缓存 RDD的缓存和RDD的checkpoint的区别 缓存是在计算结束后,直接将计算结果通过用户定义的存储级别(存储级别定义了缓存存储的介质,现在支持内存.本地文件系统和Tachyon) ...
- Spark RDD概念学习系列之RDD的5大特点(五)
RDD的5大特点 1)有一个分片列表,就是能被切分,和Hadoop一样,能够切分的数据才能并行计算. 一组分片(partition),即数据集的基本组成单位,对于RDD来说,每个分片都会被一个计 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark系列-核心概念
Spark系列-初体验(数据准备篇) Spark系列-核心概念 一. Spark核心概念 Master,也就是架构图中的Cluster Manager.Spark的Master和Workder节点分别 ...
- Spark深入之RDD
目录 Part III. Low-Level APIs Resilient Distributed Datasets (RDDs) 1.介绍 2.RDD代码 3.KV RDD 4.RDD Join A ...
- Spark系列之二——一个高效的分布式计算系统
1.什么是Spark? Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有H ...
- Spark计算模型-RDD介绍
在Spark集群背后,有一个非常重要的分布式数据架构,即弹性分布式数据集(Resilient Distributed DataSet,RDD),它是逻辑集中的实体,在集群中的多台集群上进行数据分区.通 ...
- spark 中的RDD编程 -以下基于Java api
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
随机推荐
- Java基础教程——命令行运行Java代码
视屏讲解:https://www.bilibili.com/video/av48196406/?p=4 命令行运行Java代码 (1)使用记事本新建文本文件[Test.java]. 注意,默认状态下W ...
- 蚂蚁上市员工人均一套大 House,阿里程序员身价和这匹配吗?
作者 | 硬核云顶宫 责编 | 伍杏玲 出品 | CSDN(ID:CSDNnews) 上周,蚂蚁集团迎来IPO,其发行价格将达到68.8元,总市值将突破2万亿元.市场对蚂蚁的成长性有着充分的信心,为了 ...
- react高阶组件的一些运用
今天学习了react高阶组件,刚接触react学习起来还是比较困难,和大家分享一下今天学习的知识吧,另外缺少的地方欢迎补充哈哈 高阶组件(Higher Order Components,简称:HOC) ...
- 我与PHP和git不得不说的故事(梦开始的地方,从入门到放弃记录第一章)
·关于下载 阿瑶瑶跟wampsever官网搏斗了一下午,其实我觉得教材可能在PUA我.谷歌说它给的网址安全证书过期,然后下载以断网收场.(阿瑶的第一战,以失败告终) [经过我玲姐指点,下载路径变为迅雷 ...
- Rest Framework:序列化组件
Django内置的serializers(把对象序列化成json字符串 from django.core import serializers def test(request): book_list ...
- 什么是SSL双向认证,与单向认证证书有什么区别?
SSL/TLS证书是用于用户浏览器和网站服务器之间的数据传输加密,实现互联网传输安全保护,大多数情况下指的是服务器证书.服务器证书是用于向浏览器客户端验证服务器,这种是属于单向认证的SSL证书.但是, ...
- springsecurity+springsocial资料收集
https://blog.csdn.net/tryandfight/article/details/80524573 https://niocoder.com/2018/01/09/Spring-Se ...
- PyQt(Python+Qt)学习随笔:QSpinBox数字设定部件简介
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 在输入部件中,数字调整框QSpinBox是个很实用 ...
- 威联通(NAS)搭建个人音乐中心
我为什么要自己搭建音乐服务 曾记得早些年,音乐是可以随便在线听,随便下载的,没有付费这么一说的(背后是音乐平台提供的版权支持).我们听音乐也就可以很随意,但是这几年,音乐的版权开始管理的严禁,音乐没地 ...
- 「IOI2017」接线 的另类做法
看到这题,我的第一反应是:这就是一个费用流模型?用模拟费用流的方法? 这应该是可以的,但是我忘记了怎么模拟费用流了IOI不可能考模拟费用流.于是我就想了另外一个方法. 首先我们考虑模拟费用流的模型如下 ...