spark 系列之一 RDD的使用
spark中常用的两种数据类型,一个是RDD,一个是DataFrame,本篇主要介绍RDD的一些应用场景见代码
本代码的应用场景是在spark本地调试(windows环境)
/**
* 创建 sparkSession对象
*/
val sparkSession = SparkSession.builder()
.appName("TextFile")
.master("local")
.getOrCreate()
word.txt 的文本内容如下
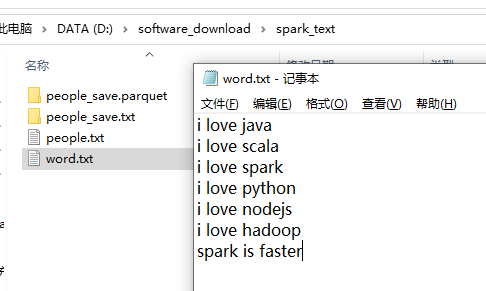
wordcount:三个算子搞定 flatMap 是把数据打平,map是对打平的数据每个计数一,reduceBykey是按照key进行分类汇总。
/**
* wordCount 程序,三个算子搞定
*/
val peopleRDD1 = sparkSession.sparkContext
.textFile("file:///D:/software_download/spark_text/word.txt")
.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.reduceByKey((a,b)=>a+b) peopleRDD1.foreach(println)
Result:
(scala,1)
(faster,1)
(is,1)
(spark,2)
(hadoop,1)
(love,6)
(i,6)
(python,1)
(nodejs,1)
(java,1)
按照key进行分组
/**
* 分组
*/
val peopleRDD2 = sparkSession.sparkContext
.textFile("file:///D:/software_download/spark_text/word.txt")
.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.groupByKey()
peopleRDD2.foreach(println)
Result:
(scala,CompactBuffer(1))
(spark,CompactBuffer(1, 1))
(is,CompactBuffer(1))
(faster,CompactBuffer(1))
(hadoop,CompactBuffer(1))
(love,CompactBuffer(1, 1, 1, 1, 1, 1))
(i,CompactBuffer(1, 1, 1, 1, 1, 1))
(python,CompactBuffer(1))
(nodejs,CompactBuffer(1))
(java,CompactBuffer(1))
遍历RDD的keys和values,RDD中存放的是一个个对象,这点跟DataFrame不同,RDD中的对象对外的表现是黑盒的,即你不知道RDD中具体的字段是什么。DataFrame则不同,你可以清晰的看到DataFrame中所存放对象的内部结构。
/**
* RDD keys与values的遍历
*/ peopleRDD1.keys.foreach(println)
peopleRDD1.values.foreach(println)
Result:
scala
faster
is
spark
hadoop
love
i
python
nodejs
java
1
1
1
2
1
6
6
1
1
1
RDD 的其它操作,
/**
* 只针对value的值进行操作,以下两种操作等效,都是对key值加1操作
*/
peopleRDD1.sortByKey().map(x=>(x._1,x._2+1)).foreach(println)
peopleRDD1.sortByKey().mapValues(x=>x+1).foreach(println)
//按照value值进行排序
peopleRDD1.sortBy(x=>x._2,ascending = true).foreach(println)
//按照key值进行排序
peopleRDD1.sortByKey(ascending = true).foreach(println)
/**
* RDD之间的join操作
*/
val pairRDD1 = sparkSession.sparkContext.parallelize(Array(("spark",1),("spark",2),("hadoop",3),("hadoop",5)))
val pairRDD2 = sparkSession.sparkContext.parallelize(Array(("spark","fast")))
val RDD1_join_RDD2 = pairRDD1.join(pairRDD2)
RDD1_join_RDD2.foreach(println)
思考题: 求该rdd,按照key进行分组后,value值得平均值,答案如下。
求:写代码
val rdd = sparkSession.sparkContext.parallelize(Array(("spark",2),("hadoop",6),("hadoop",4),("spark",6)))
Result:
(spark,4)
(hadoop,5)
spark 系列之一 RDD的使用的更多相关文章
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的缓存(八)
RDD的缓存 RDD的缓存和RDD的checkpoint的区别 缓存是在计算结束后,直接将计算结果通过用户定义的存储级别(存储级别定义了缓存存储的介质,现在支持内存.本地文件系统和Tachyon) ...
- Spark RDD概念学习系列之RDD的5大特点(五)
RDD的5大特点 1)有一个分片列表,就是能被切分,和Hadoop一样,能够切分的数据才能并行计算. 一组分片(partition),即数据集的基本组成单位,对于RDD来说,每个分片都会被一个计 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark系列-核心概念
Spark系列-初体验(数据准备篇) Spark系列-核心概念 一. Spark核心概念 Master,也就是架构图中的Cluster Manager.Spark的Master和Workder节点分别 ...
- Spark深入之RDD
目录 Part III. Low-Level APIs Resilient Distributed Datasets (RDDs) 1.介绍 2.RDD代码 3.KV RDD 4.RDD Join A ...
- Spark系列之二——一个高效的分布式计算系统
1.什么是Spark? Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有H ...
- Spark计算模型-RDD介绍
在Spark集群背后,有一个非常重要的分布式数据架构,即弹性分布式数据集(Resilient Distributed DataSet,RDD),它是逻辑集中的实体,在集群中的多台集群上进行数据分区.通 ...
- spark 中的RDD编程 -以下基于Java api
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
随机推荐
- linux设置共享文件夹 - samba
安装samba sudo apt-get install samba 配置 /etc/samba/smb.conf 的global模块添加security = user 最下加入 [share] pa ...
- python初次接触
1.python有什么用或者能做什么? 可以做网站(比如 YouTube.豆瓣),可以做图片处理,可以做科学计算,也可以爬虫,甚至于游戏,学好Python后不用担心没有用武之地,Google就大量的在 ...
- Qt中,将以png为格式的图片在按钮控件上显示
在Qt编程中,我们常常会遇见这样或那样的小问题,这里,我介绍一个将png为格式的图片在按钮控件上显示的小功能. resistanceBtn = new QPushButton(element); re ...
- 转:HTTP协议简介与在python中的使用详解
1. 使用谷歌/火狐浏览器分析 在Web应用中,服务器把网页传给浏览器,实际上就是把网页的HTML代码发送给浏览器,让浏览器显示出来.而浏览器和服务器之间的传输协议是HTTP,所以: HTML是一种用 ...
- XSS挑战赛(2)
进入第六关 简单判断过滤情况 <>script"'/ 查看源代码 可以看到第二个红框部分跟之前类似,闭合双引号尝试进行弹窗 "><script>ale ...
- Docker 基本概念(三)-生命周期详解(镜像、容器、仓库)
Docker三大组件:镜像.容器.仓库. 一.镜像 1 从仓库获取镜像 #一.从仓库获取镜像,帮助命令:docker pull -help 命令:docker pull [选项] [docker R ...
- ASP.NET Log4net数据库日志新增记录客户端ip
LOG4数据库记录器XML配置 1 <appender name="ADONetAppender" type="log4net.Appender.ADONetApp ...
- 小程序setData 修改数组附带索引解决办法
this.setData({'judge[current]':true}); 以此句进行修改值,会报错 Error: Only digits (0-9) can be put inside [] in ...
- 【题解】「UVA10116」Robot Motion
Simple Translation 让你模拟一个机器人行走的过程,如果机器人走入了一个循环,输出不是循环的长度和是循环的长度,如果最终走出来了,输出走的步数. Solution 直接模拟即可,本题难 ...
- 题解-CF429C Guess the Tree
题面 CF429C Guess the Tree 给一个长度为 \(n\) 的数组 \(a_i\),问是否有一棵树,每个节点要么是叶子要么至少有两个儿子,而且 \(i\) 号点的子树大小是 \(a_i ...