数据可视化实例(十一): 矩阵图(matplotlib,pandas)
矩阵图
https://datawhalechina.github.io/pms50/#/chapter9/chapter9
导入所需要的库
import numpy as np # 导入numpy库
import pandas as pd # 导入pandas库
import matplotlib as mpl # 导入matplotlib库
import matplotlib.pyplot as plt
import seaborn as sns # 导入seaborn库
%matplotlib inline # 在jupyter notebook显示图像
设定图像各种属性
large = 22; med = 16; small = 12
params = {'axes.titlesize': large, # 设置子图上的标题字体
'legend.fontsize': med, # 设置图例的字体
'figure.figsize': (16, 10), # 设置图像的画布
'axes.labelsize': med, # 设置标签的字体
'xtick.labelsize': med, # 设置x轴上的标尺的字体
'ytick.labelsize': med, # 设置整个画布的标题字体
'figure.titlesize': large}
#plt.rcParams.update(params) # 更新默认属性
plt.style.use('seaborn-whitegrid') # 设定整体风格
sns.set_style("white") # 设定整体背景风格
程序代码
# step1:导入数据
df = sns.load_dataset('iris')
# step2: 绘制矩阵图
# 画布
plt.figure(figsize = (12, 10), # 画布尺寸_(12, 10)
dpi = 80) # 分辨率_80
# 矩阵图
sns.pairplot(df, # 使用的数据
kind = 'scatter', # 绘制图像的类型_scatter
hue = 'species', # 类别的列,让不同类别具有不谈的颜色
plot_kws = dict(s = 50, # 点的尺寸
edgecolor = 'white', # 边缘颜色
linewidth = 2.5)) # 线宽

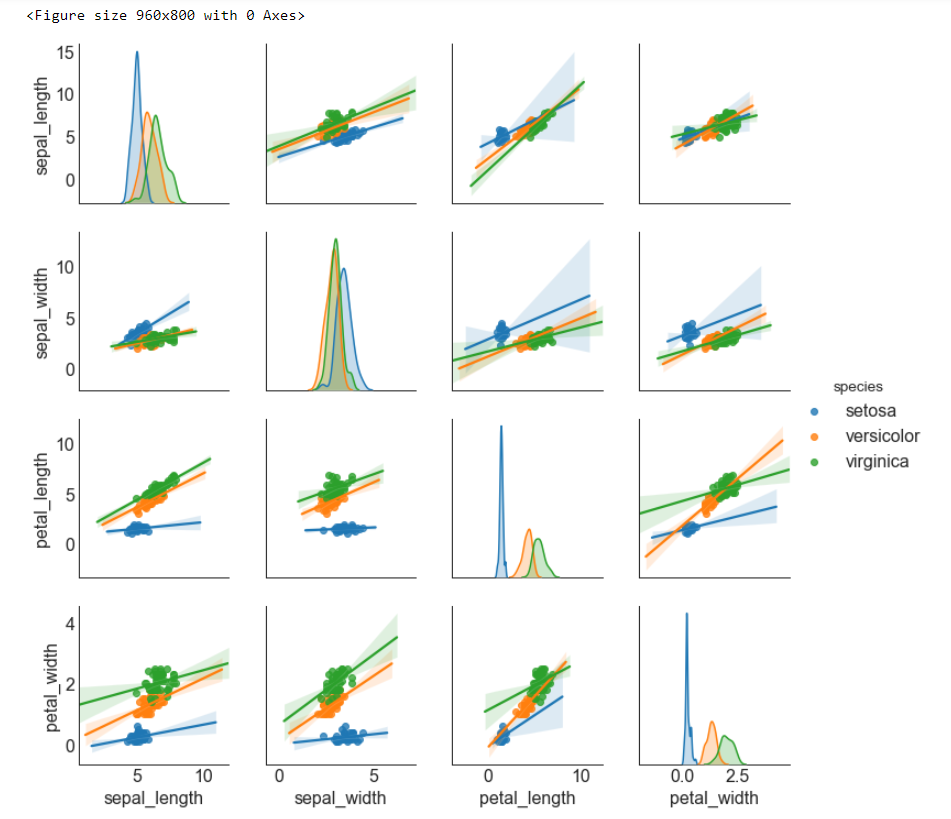
# step1:导入数据
df = sns.load_dataset('iris')
# step2: 绘制矩阵图
# 画布
plt.figure(figsize = (12, 10), # 画布尺寸_(12, 10)
dpi = 80) # 分辨率_80
# 矩阵图(带有拟合线的散点图)
sns.pairplot(df, # 使用的数据
kind = 'reg', # 绘制图像的类型_reg
hue = 'species') # 类别的列,让不同类别具有不谈的颜色
博文总结
seaborn.pairplot
seaborn.pairplot(data, hue=None, hue_order=None,
palette=None, vars=None, x_vars=None, y_vars=None, kind='scatter',
diag_kind='auto', markers=None, height=2.5, aspect=1,
dropna=True, plot_kws=None, diag_kws=None, grid_kws=None, size=None)
Plot pairwise relationships in a dataset.
By default, this function will create a grid of Axes such that each variable in data will by shared in the y-axis across a single row and in the x-axis across a single column.
The diagonal Axes are treated differently, drawing a plot to show the univariate distribution of the data for the variable in that column.
It is also possible to show a subset of variables or plot different variables on the rows and columns.
This is a high-level interface for PairGrid that is intended to make it easy to draw a few common styles. You should use PairGriddirectly if you need more flexibility.
参数:data:DataFrame
Tidy (long-form) dataframe where each column is a variable and each row is an observation.
hue:string (variable name), optional
Variable in
datato map plot aspects to different colors.
hue_order:list of strings
Order for the levels of the hue variable in the palette
palette:dict or seaborn color palette
Set of colors for mapping the
huevariable. If a dict, keys should be values in thehuevariable.
vars:list of variable names, optional
Variables within
datato use, otherwise use every column with a numeric datatype.
{x, y}_vars:lists of variable names, optional
Variables within
datato use separately for the rows and columns of the figure; i.e. to make a non-square plot.
kind:{‘scatter’, ‘reg’}, optional
Kind of plot for the non-identity relationships.
diag_kind:{‘auto’, ‘hist’, ‘kde’}, optional
Kind of plot for the diagonal subplots. The default depends on whether
"hue"is used or not.
markers:single matplotlib marker code or list, optional
Either the marker to use for all datapoints or a list of markers with a length the same as the number of levels in the hue variable so that differently colored points will also have different scatterplot markers.
height:scalar, optional
Height (in inches) of each facet.
aspect:scalar, optional
Aspect * height gives the width (in inches) of each facet.
dropna:boolean, optional
Drop missing values from the data before plotting.
{plot, diag, grid}_kws:dicts, optional
Dictionaries of keyword arguments.
返回值:grid:PairGrid
Returns the underlying
PairGridinstance for further tweaking.
seaborn.load_dataset
seaborn.load_dataset(name, cache=True, data_home=None, **kws)
从在线库中获取数据集(需要联网)。
参数:name:字符串
数据集的名字 (<cite>name</cite>.csv on https://github.com/mwaskom/seaborn-data)。 您可以通过
get_dataset_names()获取可用的数据集。
cache:boolean, 可选
如果为True,则在本地缓存数据并在后续调用中使用缓存。
data_home:string, 可选
用于存储缓存数据的目录。 默认情况下使用 ~/seaborn-data/
kws:dict, 可选
传递给 pandas.read_csv
数据可视化实例(十一): 矩阵图(matplotlib,pandas)的更多相关文章
- 【Matplotlib】数据可视化实例分析
数据可视化实例分析 作者:白宁超 2017年7月19日09:09:07 摘要:数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息.但是,这并不就意味着数据可视化就一定因为要实现其功能用途而令 ...
- 数据可视化实例(十四):面积图 (matplotlib,pandas)
偏差 (Deviation) 面积图 (Area Chart) 通过对轴和线之间的区域进行着色,面积图不仅强调峰和谷,而且还强调高点和低点的持续时间. 高点持续时间越长,线下面积越大. https:/ ...
- 数据可视化实例(三): 散点图(pandas,matplotlib,numpy)
关联 (Correlation) 关联图表用于可视化2个或更多变量之间的关系. 也就是说,一个变量如何相对于另一个变化. 散点图(Scatter plot) 散点图是用于研究两个变量之间关系的经典的和 ...
- seaborn线性关系数据可视化:时间线图|热图|结构化图表可视化
一.线性关系数据可视化lmplot( ) 表示对所统计的数据做散点图,并拟合一个一元线性回归关系. lmplot(x, y, data, hue=None, col=None, row=None, p ...
- seaborn分布数据可视化:直方图|密度图|散点图
系统自带的数据表格(存放在github上https://github.com/mwaskom/seaborn-data),使用时通过sns.load_dataset('表名称')即可,结果为一个Dat ...
- 数据可视化实例(十四):带标记的发散型棒棒糖图 (matplotlib,pandas)
偏差 (Deviation) 带标记的发散型棒棒糖图 (Diverging Lollipop Chart with Markers) 带标记的棒棒糖图通过强调您想要引起注意的任何重要数据点并在图表中适 ...
- 数据可视化实例(十七):包点图 (matplotlib,pandas)
排序 (Ranking) 包点图 (Dot Plot) 包点图表传达了项目的排名顺序,并且由于它沿水平轴对齐,因此您可以更容易地看到点彼此之间的距离. https://datawhalechina.g ...
- 数据可视化实例(九): 边缘箱形图(matplotlib,pandas)
https://datawhalechina.github.io/pms50/#/chapter7/chapter7 边缘箱形图 (Marginal Boxplot) 边缘箱图与边缘直方图具有相似的用 ...
- 数据可视化实例(七): 计数图(matplotlib,pandas)
https://datawhalechina.github.io/pms50/#/chapter5/chapter5 计数图 (Counts Plot) 避免点重叠问题的另一个选择是增加点的大小,这取 ...
随机推荐
- 多线程实现tcp聊天服务器
多线程tcp server & client tcp服务端(多线程): from socket import * from threading import Thread def clien ...
- statsmodels中方差分析表结果解析
引言 通常我们在对多个变量进行统计分析的时候,结果的汇总和整理需要耗费大量的时间和精力,稍有不慎还有可能出现错误.因此在对多个变量统计分析的时候,使用自动化的脚本对结果进行整理和汇总就十分的方便了. ...
- 【loj - 3055】「HNOI2019」JOJO
目录 description solution accepted code details description JOJO 的奇幻冒险是一部非常火的漫画.漫画中的男主角经常喜欢连续喊很多的「欧拉」或 ...
- Communication【floyd判环+并查集】
Communication 题目链接(点击) 题目描述 The Ministry of Communication has an extremely wonderful message system, ...
- 痞子衡嵌入式:恩智浦i.MX RT1xxx系列MCU启动那些事(11.0)- FlexSPI NOR启动时间(RT1170)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是恩智浦i.MX RT1170 FlexSPI NOR启动时间. 痞子衡刚刚拿到i.MXRT1170 B0版本的芯片,迫不及待地在上面跑了 ...
- Java 设置PDF平铺图片背景(水印)
一.概述及环境准备 本文介绍使用免费版PDF库-Free Spire.PDF for Java加载图片来设置成PDF平铺图片背景的效果,也可以作为平铺图片水印来使用:编辑代码前,需要先导入jar文件, ...
- 命令中"|"的意义
管道命令,是指 | 的左边运行结果是|右边的输入条件或者范围.如:history | grep date指从history这条命令运行的结果中显示包含有 “date” 的命令 下面举一个例子: 这是运 ...
- VMware历史版本下载【1.0~3.0】
前提:此为走HTTP协议的FTP伺服器,而且有直到Vmware3.0[之后就没了]的版本 link:http://linux.mathematik.tu-darmstadt.de/pub/linux/ ...
- demo项目开发(Python+flask+mysql+redis只包含后端接口)
[demo项目开发需求] 用户信息管理,可以注册.登录.添加用户.删除用户 注册:任何用户可以注册,对用户提交的注册信息进行校验,返回对应的信息,其中: 用户名:必填,唯一 密码:必填,只能6-12位 ...
- java中值传递
最近学基础的时候,老师讲了值传递和引用传递,这个问题一直不太明白,上网查了很多资料,按照自己的理解整理了一遍,发现之前不太明白的地方基本上想明白了,如有不正确的地方,欢迎指正,谢谢. 首先要说明的是j ...