HiBench成长笔记——(2) CentOS部署安装HiBench
安装Scala
使用spark-shell命令进入shell模式,查看spark版本和Scala版本:
下载Scala2.10.5
wget https://downloads.lightbend.com/scala/2.10.5/scala-2.10.5.tgz
解压
tar -xzvf scala-2.10.5.tgz
创建文件夹
mkdir -p /usr/local/scalacp -r scala-2.10.5 /usr/local/scala
配置环境
vim /etc/profile
添加内容
export SCALA_HOME=/usr/local/scala/scala- export PATH=$PATH:$JAVA_HOME/bin:$PHOENIX_PATH/bin:$M2_HOME/bin:$SCALA_HOME/bin
生效
source /etc/profile
验证安装成功

安装Maven
参考:https://www.cnblogs.com/ratels/p/10874379.html
只是默认使用Maven中央仓库,不用另外添加Maven中央仓库的镜像;中央仓库虽然慢,但是内容全;镜像虽然速度快,但是内容有欠缺。
安装HiBench
获取源码
wget https://codeload.github.com/Intel-bigdata/HiBench/zip/master
进入文件夹下,执行以下命令进行安装
(参考:https://github.com/Intel-bigdata/HiBench ; https://github.com/Intel-bigdata/HiBench/blob/master/docs/build-hibench.md)
mvn -Phadoopbench -Psparkbench -Dspark=1.6 -Dscala=2.10 clean package
报错:
Plugin org.apache.maven.plugins:maven-clean-plugin:2.5 or one of its dependencies could not be
The POM for org.apache.maven.plugins:maven-clean-plugin:jar:2.5 is invalid, transitive dependencies (if any) will not be available
解决方法(参考:https://blog.csdn.net/expect521/article/details/75663221):
(1)删除plugin目录下的文件夹,重新生成;
(2)设置Maven中央仓库为源;
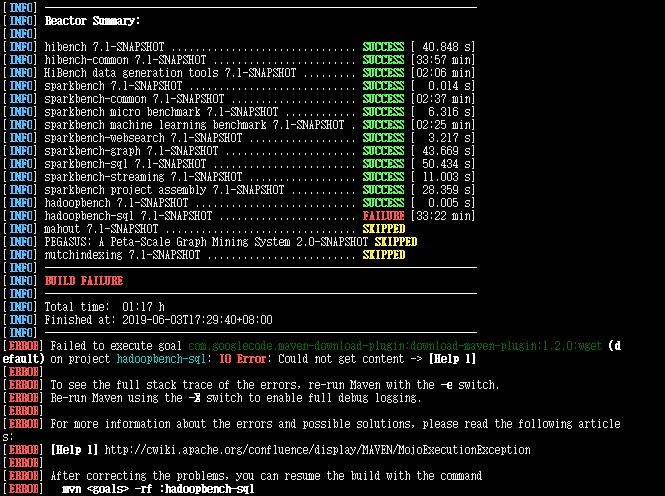
编译后返回如下信息:
[INFO] ------------------------------------------------------------------------ [INFO] Reactor Summary: [INFO] [INFO] hibench 7.1-SNAPSHOT ............................... SUCCESS [ 40.848 s] [INFO] hibench-common : min] [INFO] HiBench data generation tools : min] [INFO] sparkbench 7.1-SNAPSHOT ............................ SUCCESS [ 0.014 s] [INFO] sparkbench-common : min] [INFO] sparkbench micro benchmark 7.1-SNAPSHOT ............ SUCCESS [ 6.316 s] [INFO] sparkbench machine learning benchmark : min] [INFO] sparkbench-websearch 7.1-SNAPSHOT .................. SUCCESS [ 3.217 s] [INFO] sparkbench-graph 7.1-SNAPSHOT ...................... SUCCESS [ 43.669 s] [INFO] sparkbench-sql 7.1-SNAPSHOT ........................ SUCCESS [ 50.434 s] [INFO] sparkbench-streaming 7.1-SNAPSHOT .................. SUCCESS [ 11.003 s] [INFO] sparkbench project assembly 7.1-SNAPSHOT ........... SUCCESS [ 28.359 s] [INFO] hadoopbench 7.1-SNAPSHOT ........................... SUCCESS [ 0.005 s] [INFO] hadoopbench-sql : min] [INFO] mahout 7.1-SNAPSHOT ................................ SKIPPED [INFO] PEGASUS: A Peta-Scale Graph Mining System 2.0-SNAPSHOT SKIPPED [INFO] nutchindexing 7.1-SNAPSHOT ......................... SKIPPED [INFO] ------------------------------------------------------------------------ [INFO] BUILD FAILURE [INFO] ------------------------------------------------------------------------ [INFO] Total : h [INFO] Finished at: --03T17::+: [INFO] ------------------------------------------------------------------------ [ERROR] Failed to execute goal com.googlecode.maven-download-plugin:download-maven-plugin::] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help ] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException [ERROR] [ERROR] After correcting the problems, you can resume the build with the command [ERROR] mvn <goals> -rf :hadoopbench-sql
错误原因是:
[WARNING] Could not get content org.apache.maven.wagon.TransferFailedException: Connect to archive.apache.org: [archive.apache.org/163.172.17.199] failed: Connection timed out (Connection timed out) Caused by: java.net.ConnectException: Connection timed out (Connection timed out) [WARNING] Retrying ( more) Downloading: http://archive.apache.org/dist/hive/hive-0.14.0//apache-hive-0.14.0-bin.tar.gz java.net.SocketTimeoutException: Read timed out
本人手动去下载文件:http://archive.apache.org/dist/hive/hive-0.14.0//apache-hive-0.14.0-bin.tar.gz ,依然无法下载,说明是文件地址问题!
已经构建的模块暂时能够满足需求,先略过该问题。
创建并修改配置文件hadoop.conf
cp conf/hadoop.conf.template conf/hadoop.conf
然后修改配置文件: vim hadoop.conf
参考:https://github.com/Intel-bigdata/HiBench/blob/master/docs/run-hadoopbench.md ;https://www.cnblogs.com/PJQOOO/p/6899988.html ;https://blog.csdn.net/xiaoxiaojavacsdn/article/details/80235078
# Hadoop home hibench.hadoop.home /opt/cloudera/parcels/CDH--.cdh5./lib/hadoop # The path of hadoop executable hibench.hadoop.executable /opt/cloudera/parcels/CDH--.cdh5./bin/hadoop # Hadoop configraution directory hibench.hadoop.configure.dir /etc/hadoop/conf.cloudera.yarn # The root HDFS path to store HiBench data hibench.hdfs.master hdfs://node1:8020 #hdfs://localhost:8020 #hdfs://localhost:9000 # Hadoop release provider. Supported value: apache, cdh5, hdp hibench.hadoop.release cdh5
注意:
1.hibench.hadoop.home是你本机上hadoop的安装路径。
2.在配置hibench.hdfs.master的时候我傻傻地写了hdfs://localhost:8020,导致后来运行脚本一直不成功。
首先localhost是你的机器的IP,后面的端口号可能是8020也可能是9000,要根据本机的具体情况,在命令行输入vim /etc/hadoop/conf.cloudera.yarn/core-site.xml,可以观察到
<?xml version="1.0" encoding="UTF-8"?>
<!--Autogenerated by Cloudera Manager-->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
接下来就是在HiBench下运行脚本,比如:
bin/workloads/micro/wordcount/prepare/prepare.sh
在HDFS中创建好目录
su hdfs hadoop dfs -mkdir /HiBench/Wordcount hadoop dfs -mkdir /HiBench/Wordcount/Input
目录创建好以后执行脚本,报错:
rm: Permission denied: user=root, access=WRITE, inode="/HiBench/Wordcount":hdfs:supergroup:drwxr-xr-x
原因:
root对hdfs创建的文件目录没有访问权限!
bash-4.2$ hadoop fs -ls / Found items drwxr-xr-x - hdfs supergroup -- : /HiBench drwxr-xr-x - hdfs supergroup -- : /benchmarks drwxr-xr-x - hbase hbase -- : /hbase drwxrwxrwt - hdfs supergroup -- : /tmp drwxr-xr-x - hdfs supergroup -- : /user
解决方法:
(1 可选)参考:https://blog.csdn.net/dingding_ting/article/details/84955325
hadoop dfsadmin -safemode leave
(2)参考:https://blog.csdn.net/xianjie0318/article/details/75453758
hdfs dfs -chown -R root /HiBench
权限修正:
bash-4.2$ hadoop fs -ls / Found items drwxr-xr-x - root supergroup -- : /HiBench drwxr-xr-x - hdfs supergroup -- : /benchmarks drwxr-xr-x - hbase hbase -- : /hbase drwxrwxrwt - hdfs supergroup -- : /tmp drwxr-xr-x - hdfs supergroup -- : /user
再次执行脚本,返回结果信息:
[root@node1 prepare]# ./prepare.sh patching args= Parsing conf: /home/cf/app/HiBench-master/conf/hadoop.conf Parsing conf: /home/cf/app/HiBench-master/conf/hibench.conf Parsing conf: /home/cf/app/HiBench-master/conf/workloads/micro/wordcount.conf probe -.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-client-jobclient--cdh5.14.2-tests.jar start HadoopPrepareWordcount bench hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -rm -r -skipTrash hdfs://node1:8020/HiBench/Wordcount/Input Deleted hdfs://node1:8020/HiBench/Wordcount/Input Submit MapReduce Job: /opt/cloudera/parcels/CDH--.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn jar /opt/cloudera/parcels/CDH--.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-examples--cdh5. -D mapreduce.randomtextwriter.bytespermap= -D mapreduce.job.maps= -D mapreduce.job.reduces= hdfs://node1:8020/HiBench/Wordcount/Input The job took seconds. finish HadoopPrepareWordcount bench

在 /home/cf/app/HiBench-master 目录下,执行脚本
bin/workloads/micro/wordcount/hadoop/run.sh
返回结果信息
[root@node1 hadoop]# ./run.sh
patching args=
Parsing conf: /home/cf/app/HiBench-master/conf/hadoop.conf
Parsing conf: /home/cf/app/HiBench-master/conf/hibench.conf
Parsing conf: /home/cf/app/HiBench-master/conf/workloads/micro/wordcount.conf
probe -.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-client-jobclient--cdh5.14.2-tests.jar
start HadoopWordcount bench
hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -rm -r -skipTrash hdfs://node1:8020/HiBench/Wordcount/Output
rm: `hdfs://node1:8020/HiBench/Wordcount/Output': No such file or directory
hdfs -.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn fs -du -s hdfs://node1:8020/HiBench/Wordcount/Input
Submit MapReduce Job: /opt/cloudera/parcels/CDH--.cdh5./bin/hadoop --config /etc/hadoop/conf.cloudera.yarn jar /opt/cloudera/parcels/CDH--.cdh5./lib/hadoop/../../jars/hadoop-mapreduce-examples--cdh5. -D mapreduce.job.reduces= -D mapreduce.inputformat.class=org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat -D mapreduce.outputformat.class=org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat -D mapreduce.job.inputformat.class=org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat -D mapreduce.job.outputformat.class=org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat hdfs://node1:8020/HiBench/Wordcount/Input hdfs://node1:8020/HiBench/Wordcount/Output
Bytes Written=
finish HadoopWordcount bench

执行结束以后可以查看分析结果
/report/hibench.report
Type Date Time Input_data_size Duration(s) Throughput(bytes/s) Throughput/node HadoopWordcount 2019-06-04 16:59:04 37055 20.226 1832 610
\report\wordcount路径下有两个文件夹,分别对应执行了脚本/prepare/prepare.sh和/hadoop/run.sh所产生的信息
\report\wordcount\prepare下有多个文件:monitor.log是原始日志,bench.log是Map-Reduce信息,monitor.html可视化了系统的性能信息,\conf\wordcount.conf本次任务的环境变量
\report\wordcount\hadoop下有多个文件:monitor.log是原始日志,bench.log是Map-Reduce信息,monitor.html可视化了系统的性能信息,\conf\wordcount.conf本次任务的环境变量
monitor.html中包含了Memory usage heatmap等统计图:
根据官方文档 https://github.com/Intel-bigdata/HiBench/blob/master/docs/run-hadoopbench.md ,还可以修改 hibench.scale.profile 调整测试的数据规模,修改 hibench.default.map.parallelism 和 hibench.default.shuffle.parallelism 调整并行化
HiBench成长笔记——(2) CentOS部署安装HiBench的更多相关文章
- HiBench成长笔记——(9) Centos安装Maven
Maven的下载地址是:http://maven.apache.org/download.cgi 安装Maven非常简单,只需要将下载的压缩文件解压就可以了. cd /home/cf/app wget ...
- HiBench成长笔记——(7) 阅读《The HiBench Benchmark Suite: Characterization of the MapReduce-Based Data Analysis》
<The HiBench Benchmark Suite: Characterization of the MapReduce-Based Data Analysis>内容精选 We th ...
- HiBench成长笔记——(4) HiBench测试Spark SQL
很多内容之前的博客已经提过,这里不再赘述,详细内容参照本系列前面的博客:https://www.cnblogs.com/ratels/p/10970905.html 和 https://www.cnb ...
- HiBench成长笔记——(3) HiBench测试Spark
很多内容之前的博客已经提过,这里不再赘述,详细内容参照本系列前面的博客:https://www.cnblogs.com/ratels/p/10970905.html 创建并修改配置文件conf/spa ...
- HiBench成长笔记——(5) HiBench-Spark-SQL-Scan源码分析
run.sh #!/bin/bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributo ...
- HiBench成长笔记——(1) HiBench概述
测试分类 HiBench共计19个测试方向,可大致分为6个测试类别:分别是micro,ml(机器学习),sql,graph,websearch和streaming. 2.1 micro Benchma ...
- HiBench成长笔记——(11) 分析源码run.sh
#!/bin/bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributor licen ...
- HiBench成长笔记——(10) 分析源码execute_with_log.py
#!/usr/bin/env python2 # Licensed to the Apache Software Foundation (ASF) under one or more # contri ...
- HiBench成长笔记——(9) 分析源码monitor.py
monitor.py 是主监控程序,将监控数据写入日志,并统计监控数据生成HTML统计展示页面: #!/usr/bin/env python2 # Licensed to the Apache Sof ...
随机推荐
- excel表格 函数功能
1.去重复 选中一个区域——>数据——>删除重复项 2.条件求和 按照条件筛选:筛选出一样的类目,将对应的值求和. =sumif(A$1:A$10,B2,C$1:C$10) A$1:A$1 ...
- MySQL 远程连接问题 (Linux Server)
Mysql Workbench 连接Ubuntu上的Mysql时报如下错误: 原因:查看 /etc/mysql/mysql.conf.d/mysqld.cnf # # Instead of skip ...
- Invalid or unexpected token:数据格式错误
一个查询页面突然出现如下这个错误: Uncaught SyntaxError: Invalid or unexpected token, 翻译成中文是: 捕获的查询无效或意外的标记. 既然代码逻辑没问 ...
- CSS Sprite精灵图如何缩放大小
transform:scale( x ): 语法为:transform: scale(x,y). 同时有scaleX, scaleY专门的x, y方向的控制. 例如:transform: scale( ...
- liux vim 命令
清除所有行 先 gg 再 dG
- hadoop3.1.1高可用集群web端口9870
- P1045麦森数
P1045麦森数 #include<iostream> #include <cmath> #include <cstring> const int maxn = 1 ...
- k种球若干,取n个球,输出所有取球方案 (模拟)
有K种颜色的小球(K<=10),每种小球有若干个,总数小于100个. 现在有一个小盒子,能放N个小球(N<=8),现在要从这些小球里挑出N个小球,放满盒子. 想知道有哪些挑选方式.注:每种 ...
- Java基础 -4.6
循环嵌套 乘法口诀表 public static void main(String[] args) { for(int x =1;x<10;x++) { for(int y=1;y<=x; ...
- Selenium+webdriver自动化登陆QQ邮箱并发送邮件
1.关于selenium Selenium的主要功能包括:(1)测试与浏览器的兼容性:测试应用程序能否兼容工作在不同浏览器和操作系统之上.(2)测试系统功能:录制用例自动生成测试脚本,用于回归功能测 ...