Batch Normalization原理及其TensorFlow实现——为了减少深度神经网络中的internal covariate shift,论文中提出了Batch Normalization算法,首先是对”每一层“的输入做一个Batch Normalization 变换
批标准化(Bactch Normalization,BN)是为了克服神经网络加深导致难以训练而诞生的,随着神经网络深度加深,训练起来就会越来越困难,收敛速度回很慢,常常会导致梯度弥散问题(Vanishing Gradient Problem)。
统计机器学习中有一个经典的假设:Source Domain 和 Target Domain的数据分布是一致的。也就是说,训练数据和测试数据是满足相同分布的。这是通过训练数据获得的模型能够在测试集上获得好的效果的一个基本保障。
Convariate Shift是指训练集的样本数据和目标样本集分布不一致时,训练得到的模型无法很好的Generalization。它是分布不一致假设之下的一个分支问题,也就是指Sorce Domain和Target Domain的条件概率一致的,但是其边缘概率不同。的确,对于神经网络的各层输出,在经过了层内操作后,各层输出分布就会与对应的输入信号分布不同,而且差异会随着网络深度增大而加大了,但每一层所指向的Label仍然是不变的。
解决办法:一般是根据训练样本和目标样本的比例对训练样本做一个矫正。所以,通过引入Bactch Normalization来标准化某些层或者所有层的输入,从而固定每层输入信息的均值和方差。
方法:Bactch Normalization一般用在非线性映射(激活函数)之前,对x=Wu+b做标准化,是结果(输出信号各个维度)的均值为0,方差为1。让每一层的输入有一个稳定的分布会有利于网络的训练。
优点:Bactch Normalization通过标准化让激活函数分布在线性区间,结果就是加大了梯度,让模型更大胆的进行梯度下降,具有如下优点:
- 加大搜索的步长,加快收敛的速度;
- 更容易跳出局部最小值;
- 破坏原来的数据分布,一定程度上缓解了过拟合;
因此,在遇到神经网络收敛速度很慢或梯度爆炸(Gradient Explore)等无法训练的情况系啊,都可以尝试用Bactch Normalization来解决。
梯度爆炸:梯度非常大,链式求导后乘积就变得很大,使权重变得非常大,产生指数级爆炸。
Batch Normalization原理及其TensorFlow实现
Batch Normalization原理及其TensorFlow实现
本文参考文献
Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[J]. arXiv preprint arXiv:1502.03167, 2015.
被引次数:1658
目前主流的训练深度神经网络的算法是梯度下降算法,简而言之该过程就是通过将网络输出值与真实值之间的误差信号逐层传递至神经网络的每个节点,进而更新节点与节点之间的参数。
尽管在大数据时代,采取深度神经网络进行数据建模会变得非常优越,深度神经网络的调参过程一直是受人诟病的地方。论文中通常不会直接给出一组性能较好的参数是怎么得到的,而是直接给出模型的结果。这就使得深度神经网络的调参过程在没有经验的人看来是一个black box。
随着梯度下降算法的不断改进,已经有越来越多的算法尝试减少调参的工作量,比如减小学习率、选取合适的权重初始化函数、应用Dropout等等,而我们今天要介绍的Batch Normalization也是一个加速神经网络训练过程的算法,帮助减少调参的弯路。这个算法在2015年由Google提出,一提出便被广泛接纳采用,可以发现,现如今基本上所有的深度神经网络模型中都会加入Batch Normalization技巧。短短两年,这篇文章就已经被引用了1658次,实属2015年深度学习领域的顶级优质文章。
1. 为什么要提出Batch Normalization
首先论文中给出了一个名词covariate shift,文中指出,在深度神经网络里面,正是covariate shift导致了神经网络训练起来比较缓慢,而ReLU的发明也是为了减少covariate shift,较少covariate shift就可以提高神经网络的训练速度。
covariate shift简单来说就是当你训练好了一个函数,输入的分布变了,这个函数就无法处理了。举个例子,现在想建立一个可以用来预测癌症的分类器模型,首先我们从医院里患有癌症的老年人中抽取血液,但是仅有这些样本肯定不行,因为我们缺少健康的样本,于是我们去学校里找了一些年轻的学生志愿献血得到了健康样本的模型,这样我们就可以利用逻辑回归进行分类了是不是?训练好的模型真的就可以直接投放市场应用到病人身上了吗?
显然不是的,很大概率上这个模型会表现不好,原因就在于我们病人的样本和学生的样本分布根本不同,也就是说训练集样本的分布跟测试集样本的分布不同,即样本之间存在了covariate shift。
虽然我们本意是要学习P(癌症|血液)的概率分布,但是我们无法真正学习到这个分布,而在很大程度上我们学习的是P(癌症|血液,学生),也就是说我们这个模型是依赖于输入样本的分布的。
那么在深度神经网络中,所谓的internal covariate shift该如何理解呢?
如果神经网络的层数很浅的话,其实这个问题不大,因为采取随机的mini-batch训练方法,mini-batch之间的样本分布差别不会太大。但是对于深度神经网络而言(比如微软提出152层的residual network),由于其参数是逐层启发性的结构,因此,internal covariate shift的问题就不应该忽视了。在深度神经网络中,由于第一层参数的改变,导致了传递给第二层的输入的分布也会发生改变,也就是说在更新参数的过程中,无形中发生了internal covariate shift。因此,这样网络就很难较好的范化,训练起来也就非常缓慢了。
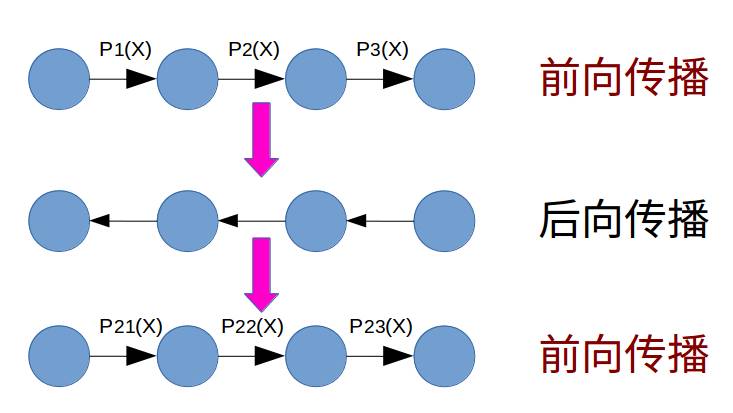
2. 什么是Batch Normalization
为了减少深度神经网络中的internal covariate shift,论文中提出了Batch Normalization算法,首先是对每一层的输入做一个Batch Normalization 变换,该变换的操作如下图所示。

直观上理解,就是首先对每层的输入进行常规的归一化,然后再在此基础上添加一个仿射变换,容许输入变换到原来的规模。这里需要说明两点:
第一,这里的常规归一化实际上就是改变了一个mini-batch中样本的分本,由原来的某个分布转化成均值为0方差为1的标准分布;
第二,仅转化了分布还不行,因为转化过后可能改变了输入的取值范围,因此需要赋予一定的放缩和平移能力,即将归一化后的输入通过一个仿射变换的子网络。这里仿射变换中的gamma和beta都是可以学习的参数,不难发现如果gamma取输入的标准差,beta取输入的均值,Batch Normalization变换就回到了恒等变换。
第三,这里的所有操作都是可微分的,也就使得了梯度后向传播算法在这里变得可行;
跳过文中的梯度的推导公式,我们直接来看整个Batch Normalization算法,如下图所示,首先是训练Batch Normalized网络,然后再将其应用于推理阶段。

关于上图,有必要说明一个困惑的地方。细心的读者一定会发现上图中的第10步中Var[x]不是直接等于方差的期望,而是在前面添加了分数m/(m-1),这是为什么呢?
原因就在于我们的初衷是希望网络的输出只依赖于输入,而不是依赖于mini-batch的划分,之所以划分成mini-batch来进行训练,是因为这样做考虑到了实际情况,如果采取完整的batch训练,那是不现实的。
基于此,算法1中的方差只是一个mini-batch样本方差,但是在算法2中的推理阶段,我们要使用的应该是样本全局的方差,而不是拿一个部分来预测,而实际上我们也不知道整个数据集的期望值是多少,所以就拿mini-batch的均值来代替期望值,这样简单粗暴的做法就会使得我们估计的样本过于集中,也就是说我们估计的方差要比真实方差小一点,因此mini-batch中的方差实际上是低估了整个数据集的方差,我们要得到无偏估计,所以这里要乘以m/(m-1)稍稍放大一下方差的值,至于为什么不放大到其他值,为什么分母不是m-2或m-3,可以查阅更严格的数学证明。
原理部分就介绍到这里了,论文中给出了结合了Batch Normalization的CNN网络用于图像分类的效果,感兴趣的读者可以去阅读一下,至于Batch Normalization在RNN中的应用效果以及相应改进,我们后期会继续推送。
接下来动手在TensorFlow中实现Batch Normalization,由于TensorFlow中提供了非常方便的Batch Normalization的API,因此这里我只简单演示一下Batch Normalization变换的写法:
importtensorflow astf
defbn_transform(x):batch_mean, batch_var = tf.nn.moments(x,[ 0]) z_hat = (x - batch_mean) / tf.sqrt(batch_var + epsilon) gamma = tf.Variable(tf.ones([ 100])) beta = tf.Variable(tf.zeros([ 100])) bn = gamma * z_hat + beta y = tf.nn.sigmoid(bn)
returny
在TensorFlow中,我们可以直接在层与层之间调用tf.layers.batch_normalization函数,该函数参数调用如下:
batch_normalization( inputs, axis=- 1, momentum= 0.99, epsilon= 0.001, center= True, scale= True, beta_initializer=tf.zeros_initializer(), gamma_initializer=tf.ones_initializer(), moving_mean_initializer=tf.zeros_initializer(), moving_variance_initializer=tf.ones_initializer(), beta_regularizer= None, gamma_regularizer= None, training= False, trainable= True, name= None, reuse= None)
在训练阶段我们只用设定training=True即可,在推理阶段,我们设置training=False即可,感兴趣的读者可以看看这个函数的内部实现源码。
Batch Normalization原理及其TensorFlow实现——为了减少深度神经网络中的internal covariate shift,论文中提出了Batch Normalization算法,首先是对”每一层“的输入做一个Batch Normalization 变换的更多相关文章
- 图像分类(二)GoogLenet Inception_v2:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Inception V2网络中的代表是加入了BN(Batch Normalization)层,并且使用 2个 3*3卷积替代 1个5*5卷积的改进版,如下图所示: 其特点如下: 学习VGG用2个 3* ...
- Batch normalization:accelerating deep network training by reducing internal covariate shift的笔记
说实话,这篇paper看了很久,,到现在对里面的一些东西还不是很好的理解. 下面是我的理解,当同行看到的话,留言交流交流啊!!!!! 这篇文章的中心点:围绕着如何降低 internal covari ...
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
1. 摘要 训练深层的神经网络非常困难,因为在训练的过程中,随着前面层数参数的改变,每层输入的分布也会随之改变.这需要我们设置较小的学习率并且谨慎地对参数进行初始化,因此训练过程比较缓慢. 作者将这种 ...
- Deep Learning 27:Batch normalization理解——读论文“Batch normalization: Accelerating deep network training by reducing internal covariate shift ”——ICML 2015
这篇经典论文,甚至可以说是2015年最牛的一篇论文,早就有很多人解读,不需要自己着摸,但是看了论文原文Batch normalization: Accelerating deep network tr ...
- 论文笔记:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
ICML, 2015 S. Ioffe and C. Szegedy 解决什么问题(What) 分布不一致导致训练慢:每一层的分布会受到前层的影响,当前层分布发生变化时,后层网络需要去适应这个分布,训 ...
- Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift(BN)
internal covariate shift(ics):训练深度神经网络是复杂的,因为在训练过程中,每层的输入分布会随着之前层的参数变化而发生变化.所以训练需要更小的学习速度和careful参数初 ...
- TensorFlow实现与优化深度神经网络
TensorFlow实现与优化深度神经网络 转载请注明作者:梦里风林Github工程地址:https://github.com/ahangchen/GDLnotes欢迎star,有问题可以到Issue ...
- TensorFlow 深度学习笔记 TensorFlow实现与优化深度神经网络
转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎star,有问题可以到Issue区讨论 官方教程地址 视频/字幕下载 全 ...
- Batch Normalization原理
Batch Normalization导读 博客转载自:https://blog.csdn.net/malefactor/article/details/51476961 作者: 张俊林 为什么深度神 ...
随机推荐
- MySQL Cluster 具体配置文件(config.ini)
########################################################################### ## MySQL CLuster 配置文件 ## ...
- STM32F103 AFIO时钟疑问
在stm32F103系列中:AFIO是重映射辅助时钟,如果仅仅是使用第二功能(如uart,spi,),不需要打开,使用第二功能打开GPIO和第二功能时钟.我反复测试是这样的 AFIO时钟由RCC_AP ...
- 从一到面试题了解js异步机制:setTimeout 和 Pronmise
1.毫无疑问setTimeout是最晚输出的 2.请无视undefined,这是浏览器的返回值. 3.new Promise中并不是异步,而.then()后才是异步.
- npm 国内淘宝镜像cnpm、设置淘宝源
1.下载和使用cnpm 某些插件很奇怪,需要用国内的镜像下载才可以 #安装淘宝镜像npm install cnpm -g --registry=https://registry.npm.taobao. ...
- sourcetree和Git的使用教程
1.简单的用Git管理项目. 2.怎样既要开发又要处理发布出去的版本bug情况. SourceTree是一个免费的Git图形化管理工具,mac下也可以安装. 下载地址:https://www.sour ...
- Unity刚体穿透问题测试以及解决
测试环境很简单,一面墙,红色方块不停向前 然后,由于刚体是FixedUpdate执行的,把FixedUpdate执行间隔调慢一些方便Debug: OK,下面还原一次经典的穿透问题: 测试脚本: voi ...
- 【Android】11.3 屏幕旋转和场景变换过程中GridView的呈现
分类:C#.Android.VS2015: 创建日期:2016-02-21 一.简介 实际上,对于布局文件中的View来说,大多数情况下,Android都会自动保存这些状态,并不需要我们都去处理它.这 ...
- 利用Java剖析工具JProfiler查找内存泄漏的方法
本文主要介绍如何如何利用在使用JProfiler时意识到内存泄漏以及查找内存泄漏的几种方法. 工具/原料 JProfiler 方法/步骤 JProfiler的内存视图会话提供了内存使用情况的动 ...
- VC++ 进度条的使用
进度条控件封装在CProcessCtrl类中 1.SetRange和SetRange32方法来设置进度条显示范围. 语法格式: void SetRange(short nLower, short nU ...
- 【Maven】maven打包生成可执行jar文件
http://blog.csdn.net/u013177446/article/details/53944424 ******************************************* ...