IntelliJ IDEA编写的spark程序在远程spark集群上运行
准备工作
需要有三台主机,其中一台主机充当master,另外两台主机分别为slave01,slave02,并且要求三台主机处于同一个局域网下
通过命令:ifconfig
可以查看主机的IP地址,如下图所示
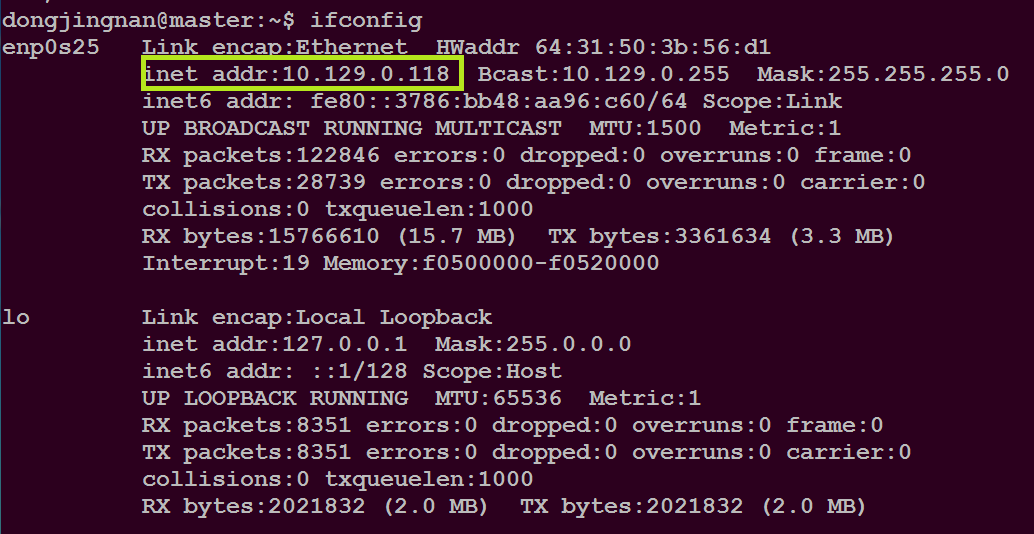
本集群的三台机器的IP地址如下
10.129.0.118 master
10.129.0.223 slave01
10.129.0.124 slave02
通过命令:ping IP地址
可以查看与另一台主机的连通性
如下所示
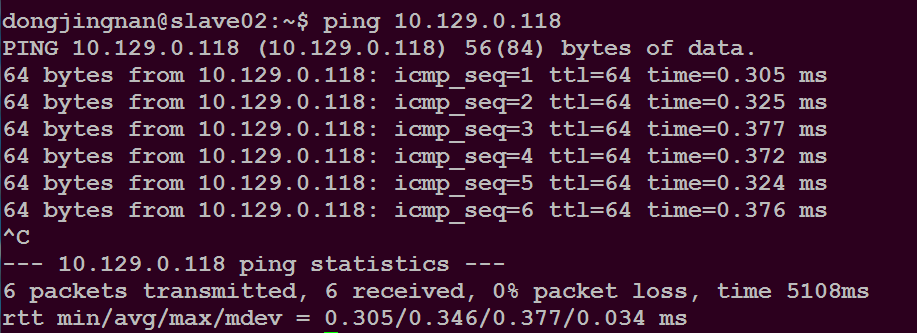
注意:在shell命令下通过CTRL+C 可以结束命令的执行
三台主机的用户名均为dongjingnan
修改三台主机的/etc/hosts

在文件开头添加如下内容
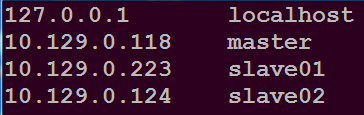
配置ssh无密码登录本机和集群
在master主机上执行如下命令



将master主机上的公钥发给slave01,slave02

在slave01和slave02上都执行如下命令


可以通过命令:ssh 主机名
登录指定主机,如下所示
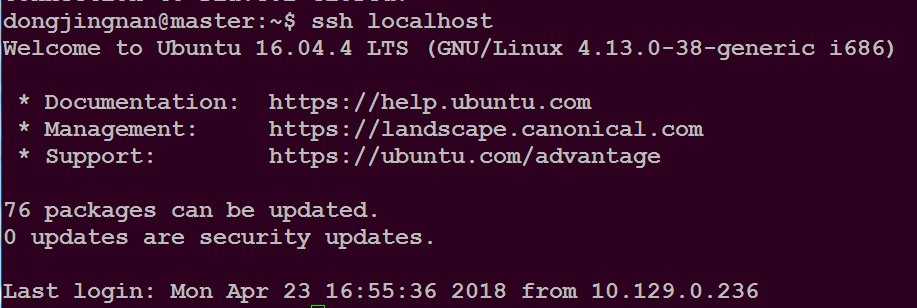
通过命令:exit //退出

JDK和hadoop的配置和安装

如果无法安装可以通过命令:sudo apt-get update //更新软件库
执行命令:sudo vim ~/.bashrc
在~/.bashrc中添加如下内容
export JAVA_HOME=/usr/lib/jvm/default-java
执行命令:source ~/.bashrc
使~/.bashrc文件修改生效
执行命令:java -version
查看jdk版本号,如下图所示

通过网站https://mirrors.cnnic.cn/apache/hadoop/common/
下载hadoop的最新稳定的版本
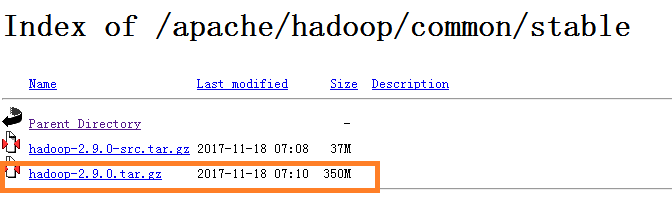
在用户主目录下执行命令$ sudo tar -zxvf ~/Downloads/hadoop-2.9.0.tar.gz -C /usr/local
在用户主目录下执行命令$ cd /usr/local/
在 /usr/local/ 目录下执行命令$ sudo mv ./hadoop-2.9.0 ./hadoop
在 /usr/local/ 目录下执行命令$ sudo chown -R dongjingnan ./hadoop //将dongjingnan替换成你的用户名
编辑 ~/.bahrc 文件,在里面添加如下内容
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存之后,执行命令: source ~/.bashrc
切换到目录/usr/local/hadoop/etc/hadoop 并查看该目录下的文件
执行命令$ sudo vim slaves
将里面的内容替换成
slave01
slave02
保存后,执行命令$ sudo vim core-site.xml
修改成如下内容
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
保存后,执行命令$ sudo vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
保存后,执行命令$ sudo cp mapred-site.xml.template mapred-site.xml
执行命令$ sudo vim mapred-site.xml
添加如下内容
<configuration>
<porperty>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
保存后,执行命令$ sudo vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanage.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
</configuration>
保存后,将master上的/usr/local/hadoop目录复制到各个节点上
在用户的主目录执行命令$ sudo tar -zcf ~/hadoop.master.tar.gz /usr/local/hadoop
在用户的主目录执行命令$ scp ~/hadoop.master.tar.gz slave01:/home/dongjingnan
在用户的主目录执行命令$ scp ~/hadoop.master.tar.gz slave02:/home/dongjingnan
执行命令$ ssh slave01
在slave01的主目录执行命令$ sudo tar -zxvf ~/hadoop.master.tar.gz /usr/local
在slave01的主目录执行命令$ sudo chown -R dongjingnan /usr/local/hadoop
执行命令$ exit
在master主目录执行命令$ ssh slave02
在slave02的主目录执行命令$ sudo tar -zxvf ~/hadoop.master.tar.gz /usr/local
在slave02的主目录执行命令$ sudo chown -R dongjingnan /usr/local/hadoop
执行命令$ exit
在master主目录执行如下命令$ sudo vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
添加一个属性
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
保存后,在master主目录下执行如下命令$ sudo vim yarn-site.xml
删除yarn.nodemanager.resource.memory-mb属性
保存后退出
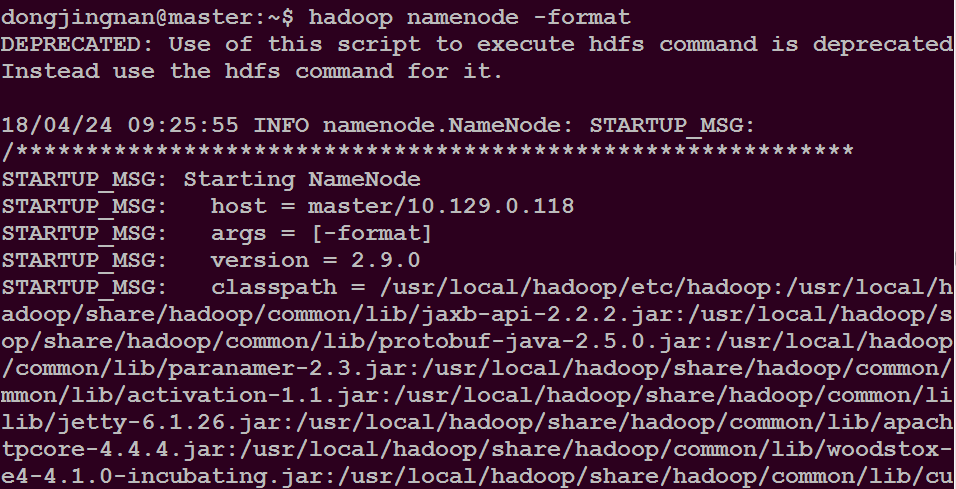
在master主目录下执行命令$ hadoop namenode -format
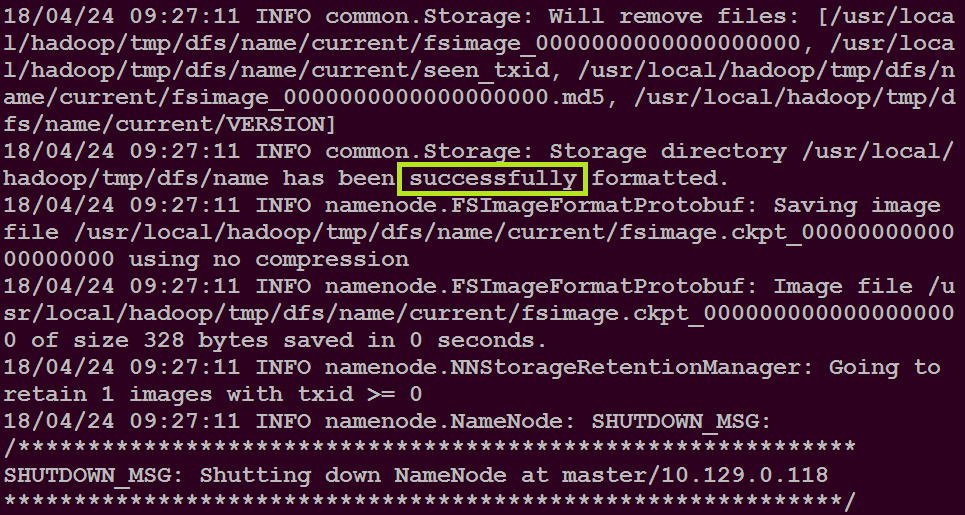
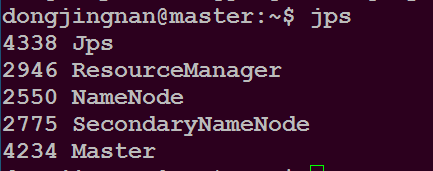
在master主目录下执行命令$ start-all.sh
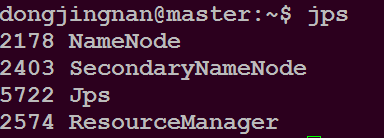
在master主目录下执行命令$ jps
可以看到如下进程
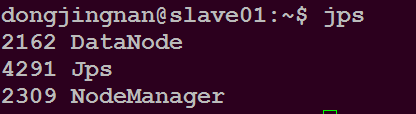
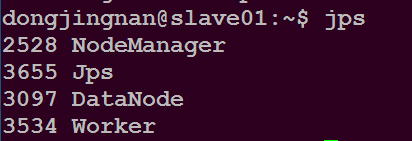
在slave01主目录下执行命令$ jps
可以看到如下进程
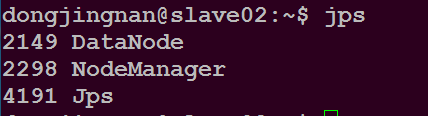
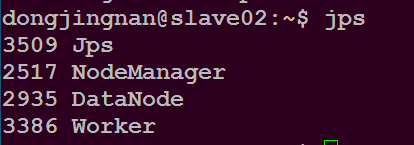
在slave02主目录下执行命令$ jps
可以看到如下进程
到此,hadoop集群安装完毕
hadoop集群启动时可能出现的问题
问题描述:slave01和slave02都没有出现DataNode进程
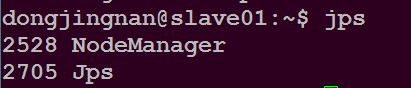
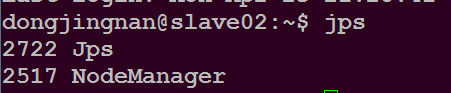
解决办法:每次启动集群前删除slave01和slave02节点上/usr/local/hadoop/tmp/dfs/目录下的data文件夹,然后新建一个data空的文件夹
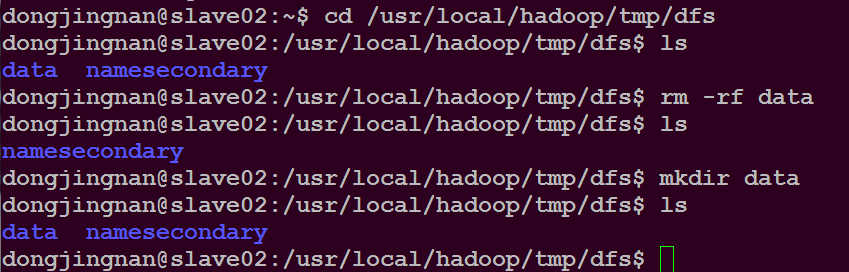
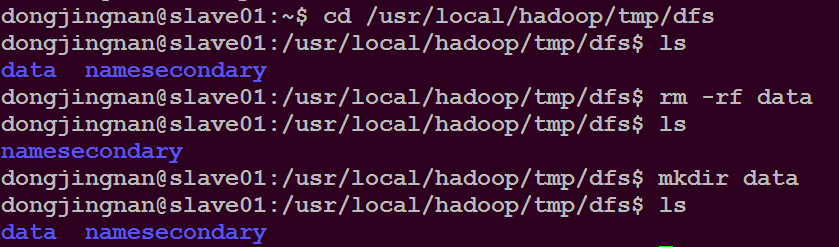
再重新格式化namenode节点,就可以解决了。
在master节点执行命令$ stop-all.sh
可以关闭hadoop集群
接下来进行spark集群的安装
在火狐浏览器输入网址http://spark.apache.org/downloads.html 可以下载spark软件包
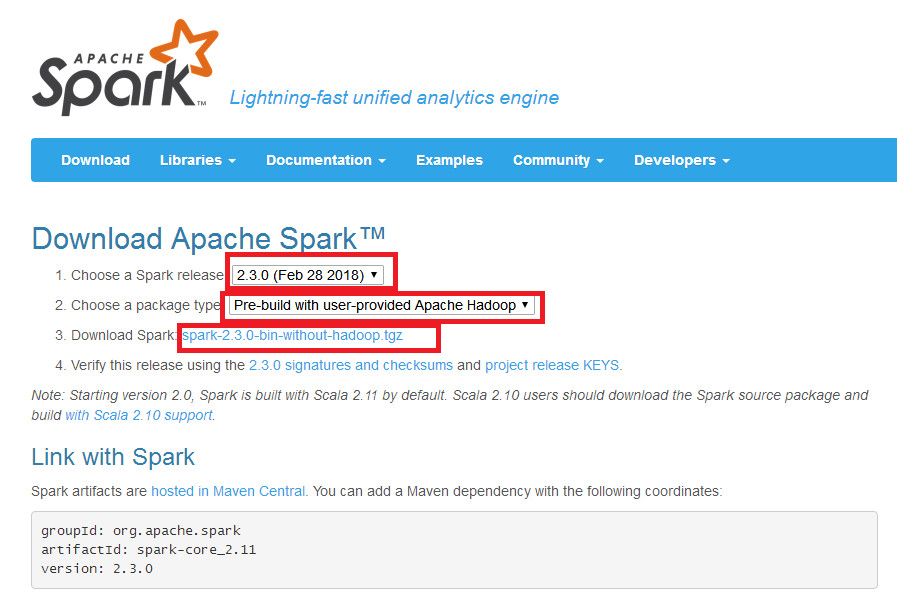
在master主目录下执行命令$ sudo tar -zxvf ~/Downloads/spark-2.3.0-bin-without-hadoop.tgz -C /usr/local
在master主目录下执行命令$ sudo mv /usr/local/spark-2.3.0-bin-without-hadoop /usr/local/spark
在master主目录下执行命令$ sudo chown -R dongjingnan /usr/local/spark
修改~/.bashrc文件
添加如下内容

执行命令$ source ~/.bashrc
执行命令$ cd /usr/local/spark/conf
执行命令$ cp slaves.template slaves
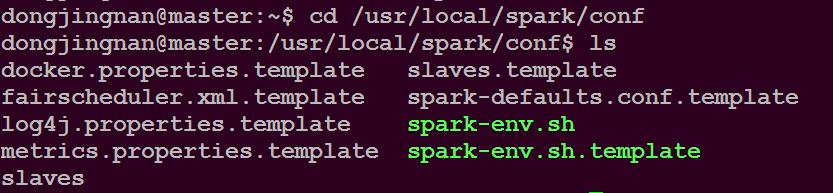
执行命令$ sudo vim slaves
添加如下内容
slave01
slave02
执行命令$ cp spark-env,.sh.template spark-env.sh
执行命令$ sudo vim spark-env.sh

添加如下内容

SPARK_MASTER_IP设置为你自己的master的IP地址
保存后,执行如下命令$
将/usr/local/目录下的spark文件夹打包后发送到slave01和slave02
如下所示


将slave01和slave02节点上的spark.master.tar.gz解压到/usr/local/目录下,并授权给slave01和slave02的用户名


启动hadoop集群
执行命令$ start-all.sh
启动spark集群
执行命令$ start-master.sh
执行命令$ start-slaves.sh
如下图所示

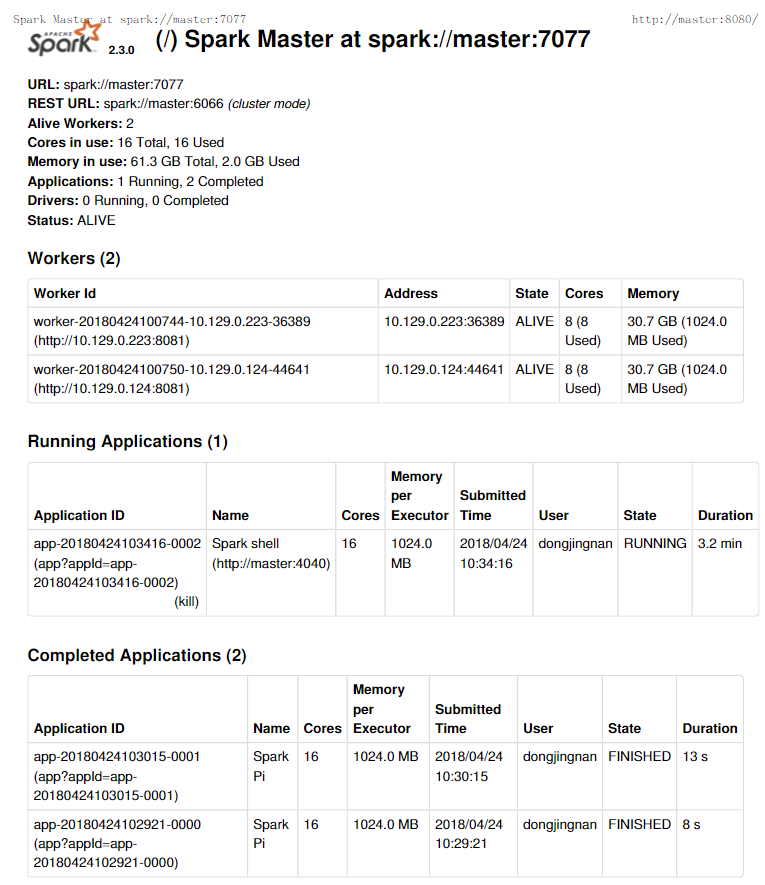
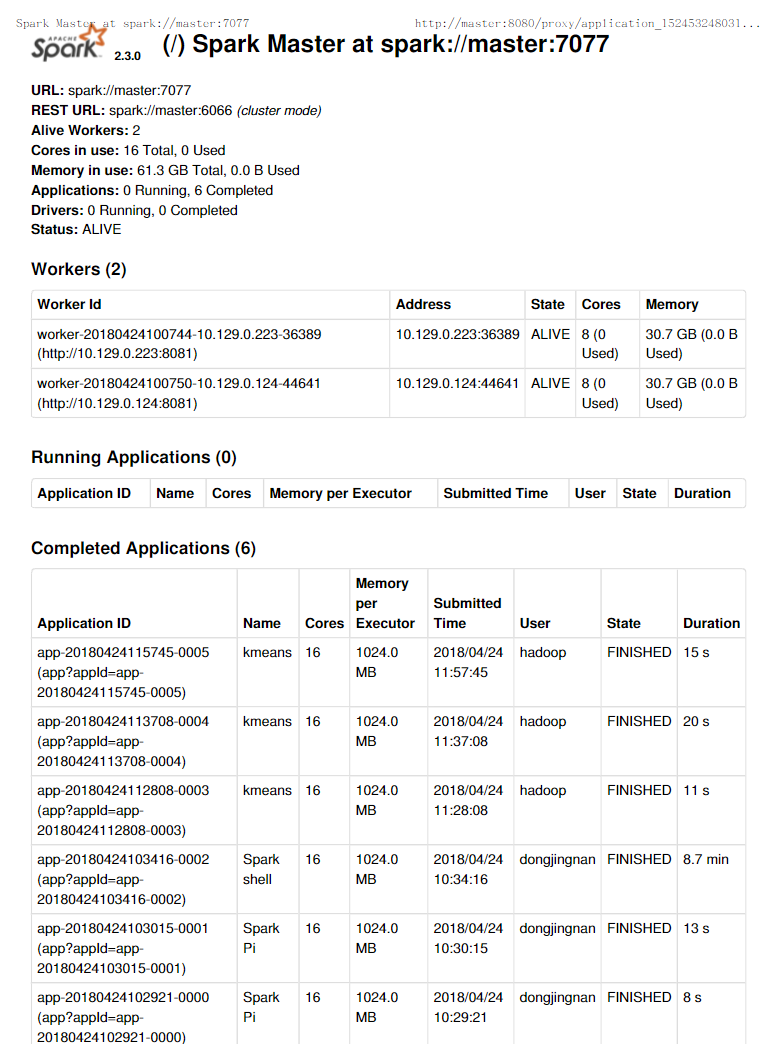
在master主机登录网址http://master:8080 可以看到如下内容
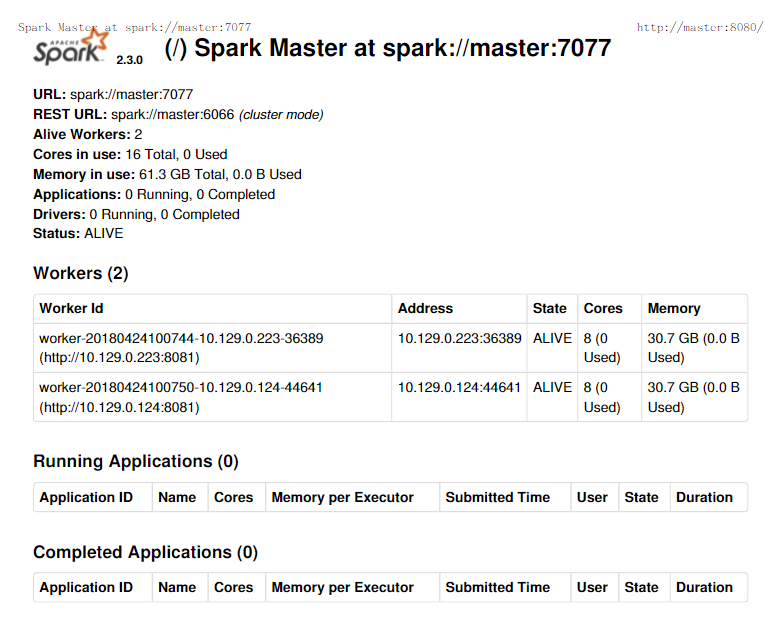
关闭spark集群
执行命令$ stop-slaves.sh
执行命令$ stop-master.sh
在集群中运行应用程序JAR包

在集群中运行spark-shell
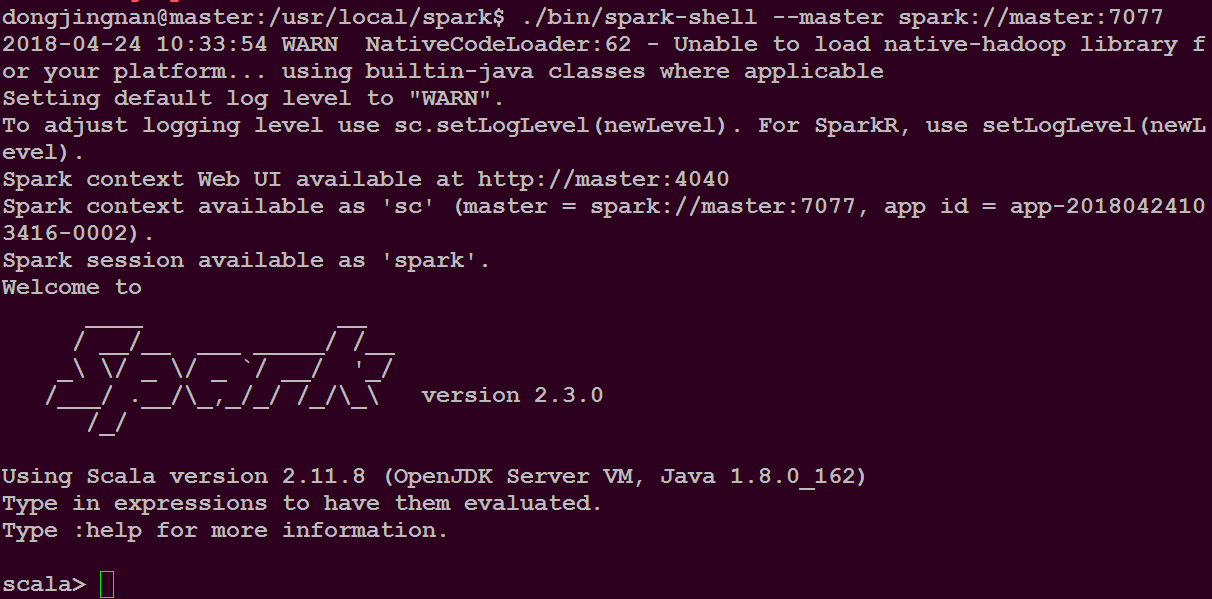
用户在master主机上的火狐浏览器登录网址http://master:8080/ 查看应用的运行情况
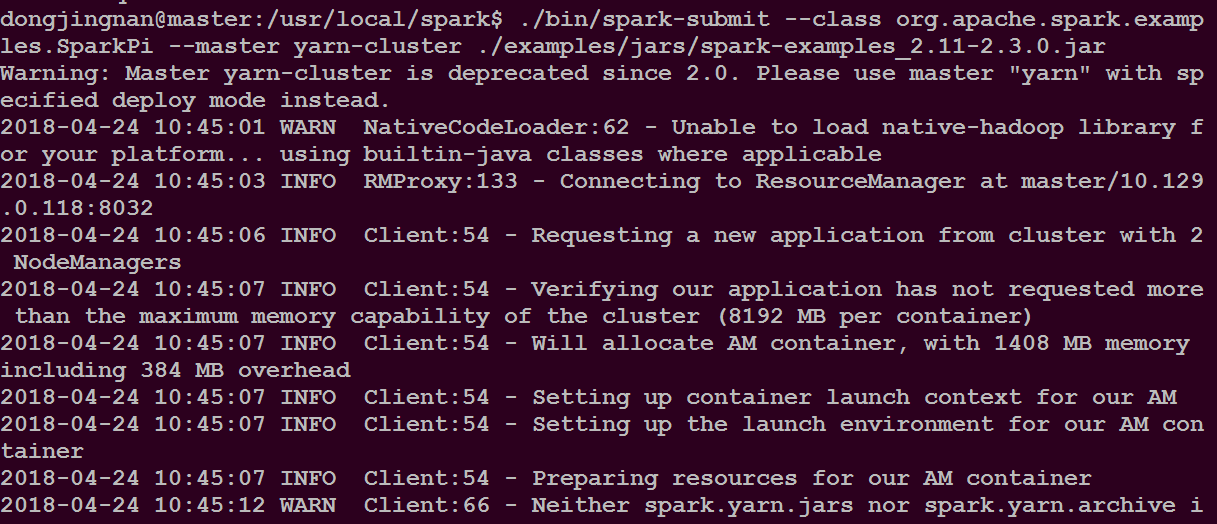
向hadoop yarn 集群管理器提交应用
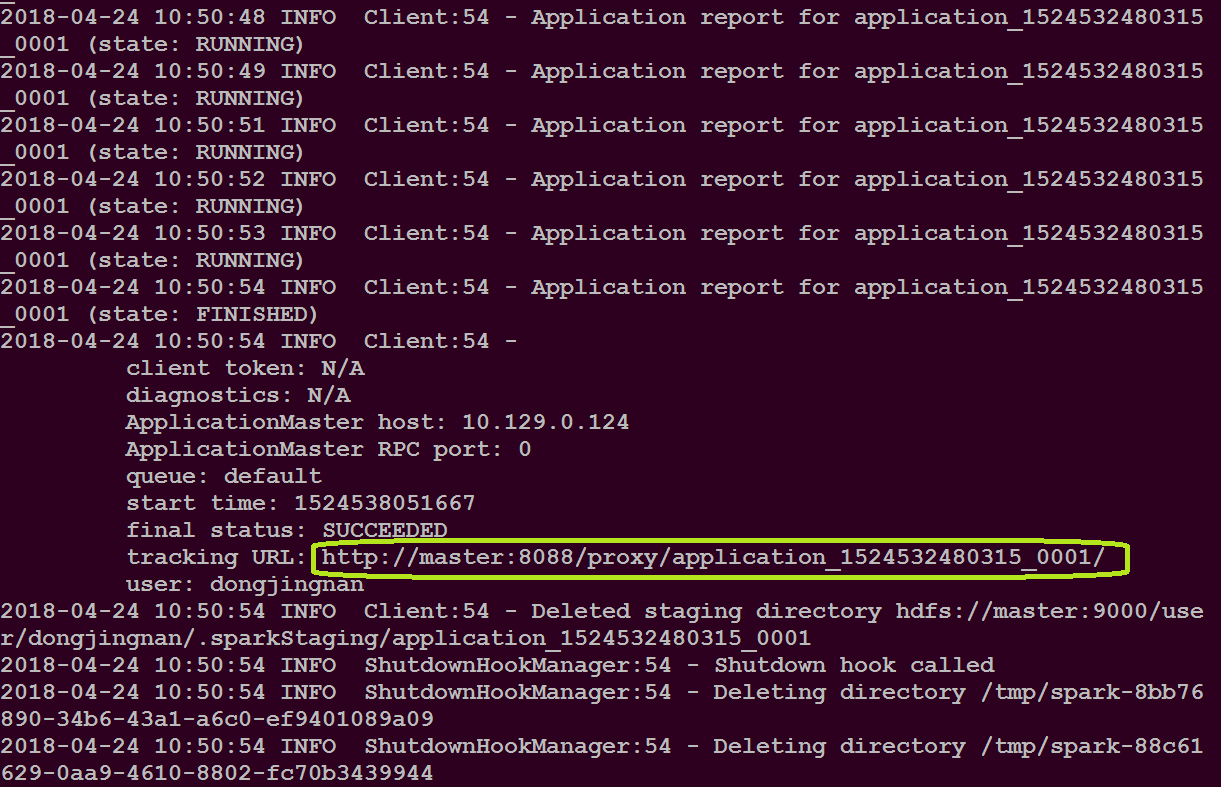
在master主机登录上图绿色圈住的网址,查看应用的运行情况

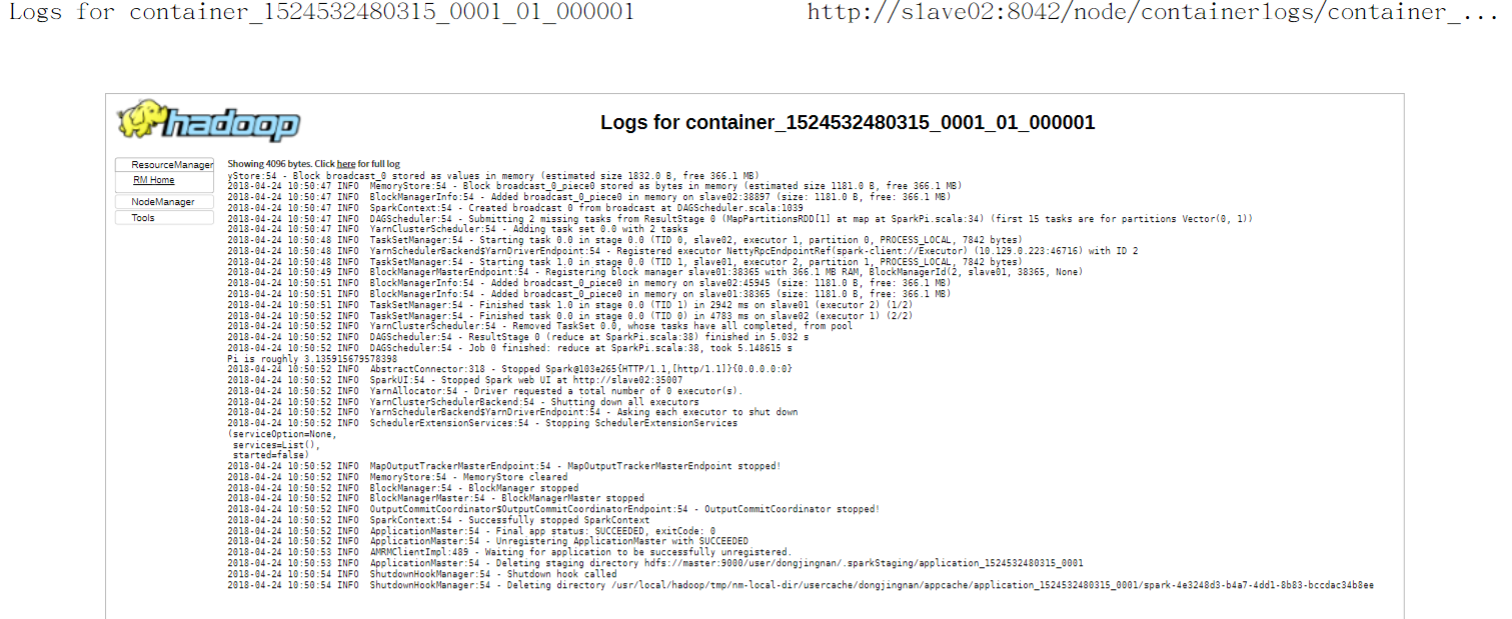
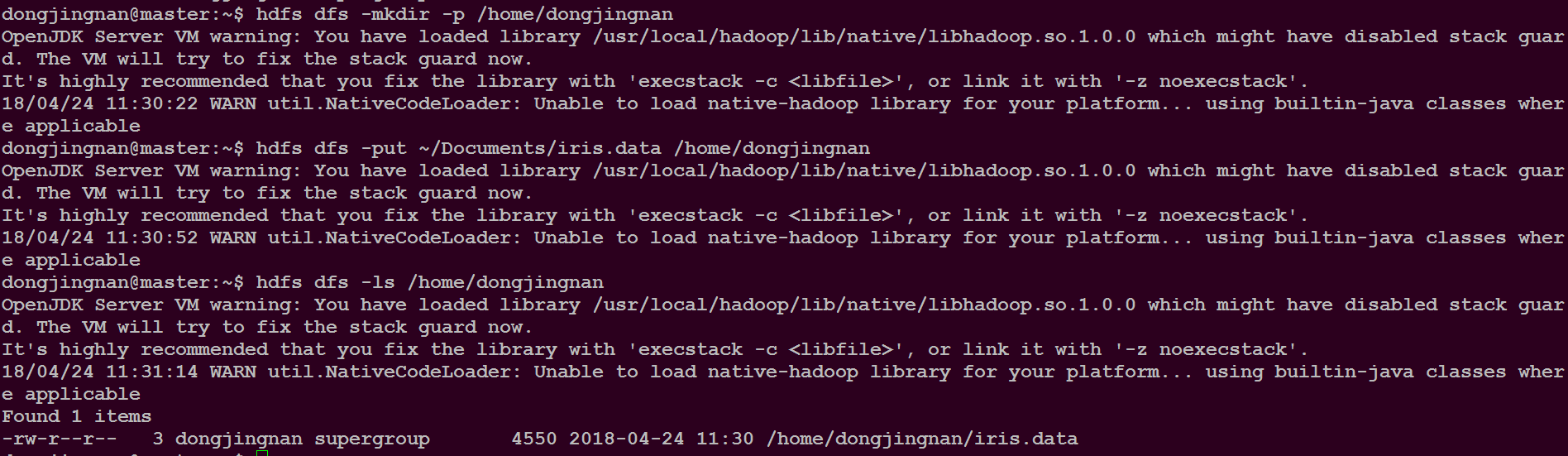
为了进行下面的程序,请把所需的文件上传到hdfs中,以备后面使用,另外每次关机之后,再重启后又要重新做一遍
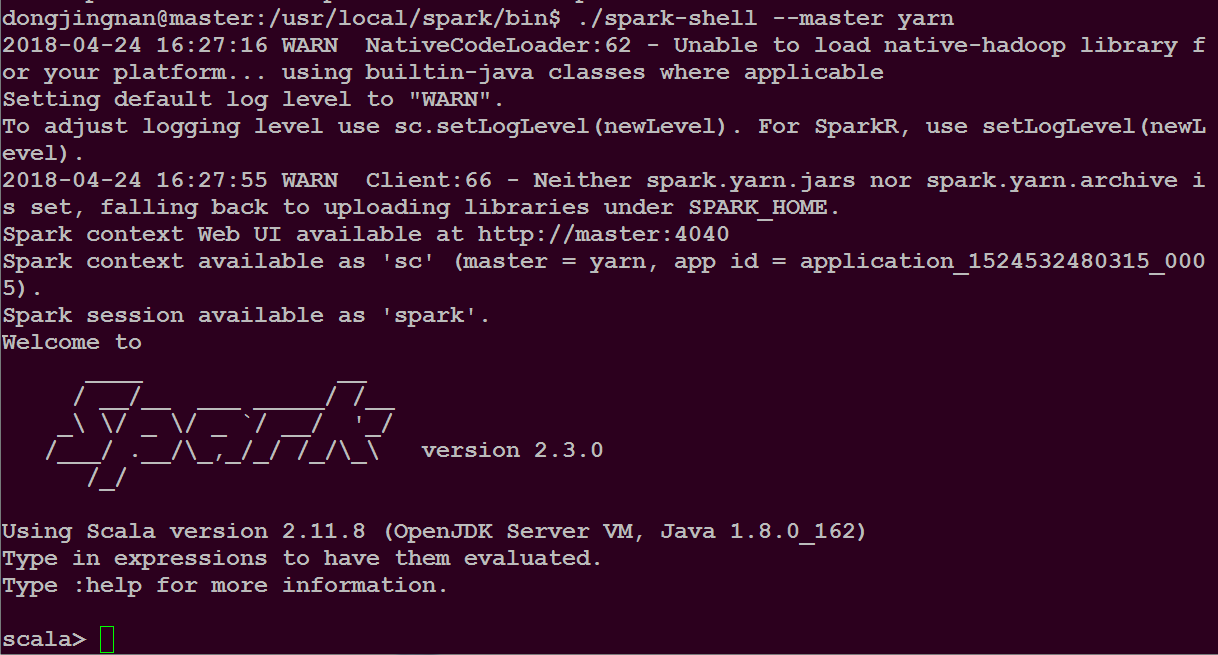
在集群中运行spark-shell
本实验所需的数据集可以在网址https://archive.ics.uci.edu/ml/machine-learning-databases/ 下载
实验所需的数据集是鸢尾花数据集
在网址https://www.jetbrains.com/idea/downloads/#section=windows 下载Intellij IDEA
选择使用的操作系统的环境,建议下载Ultimate版本,因为好像Community版本不能够将编写的程序打包成jar文件,下文要用到打包的jar文件
刚开始的时候不要设置SparkConf后的setmaster()内容
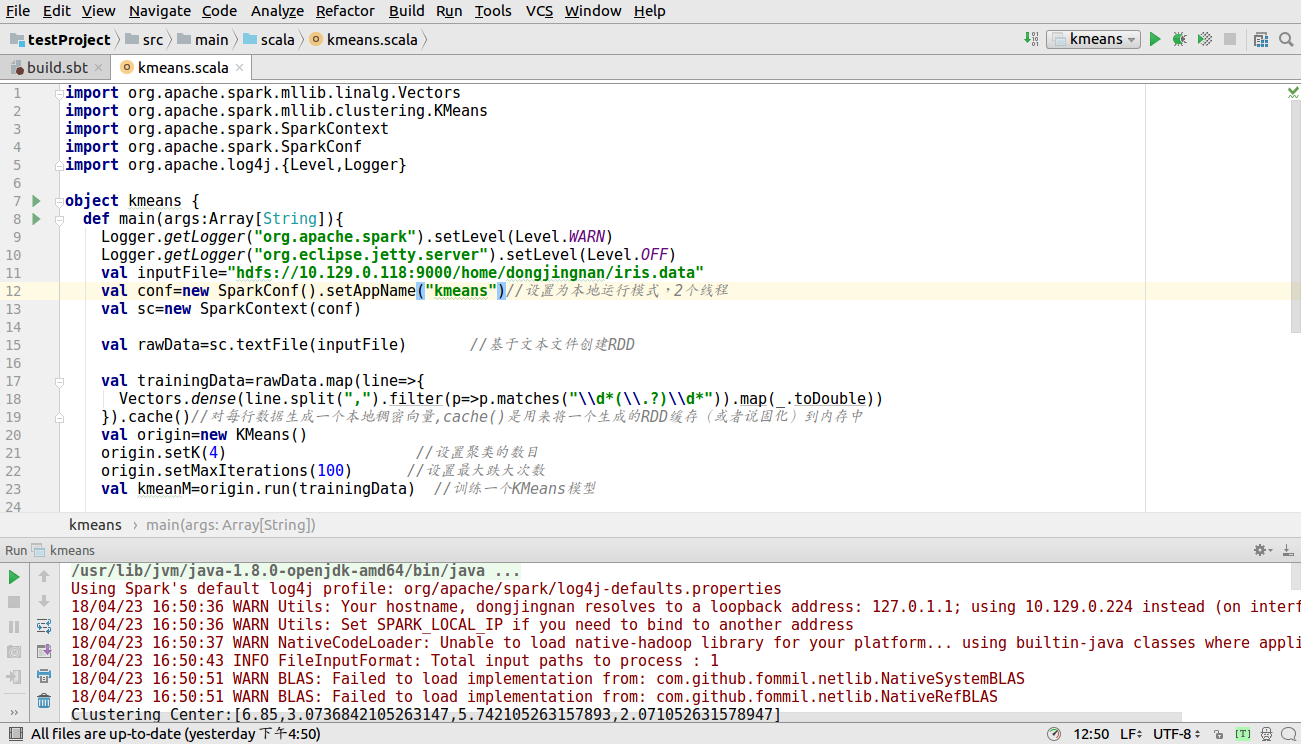
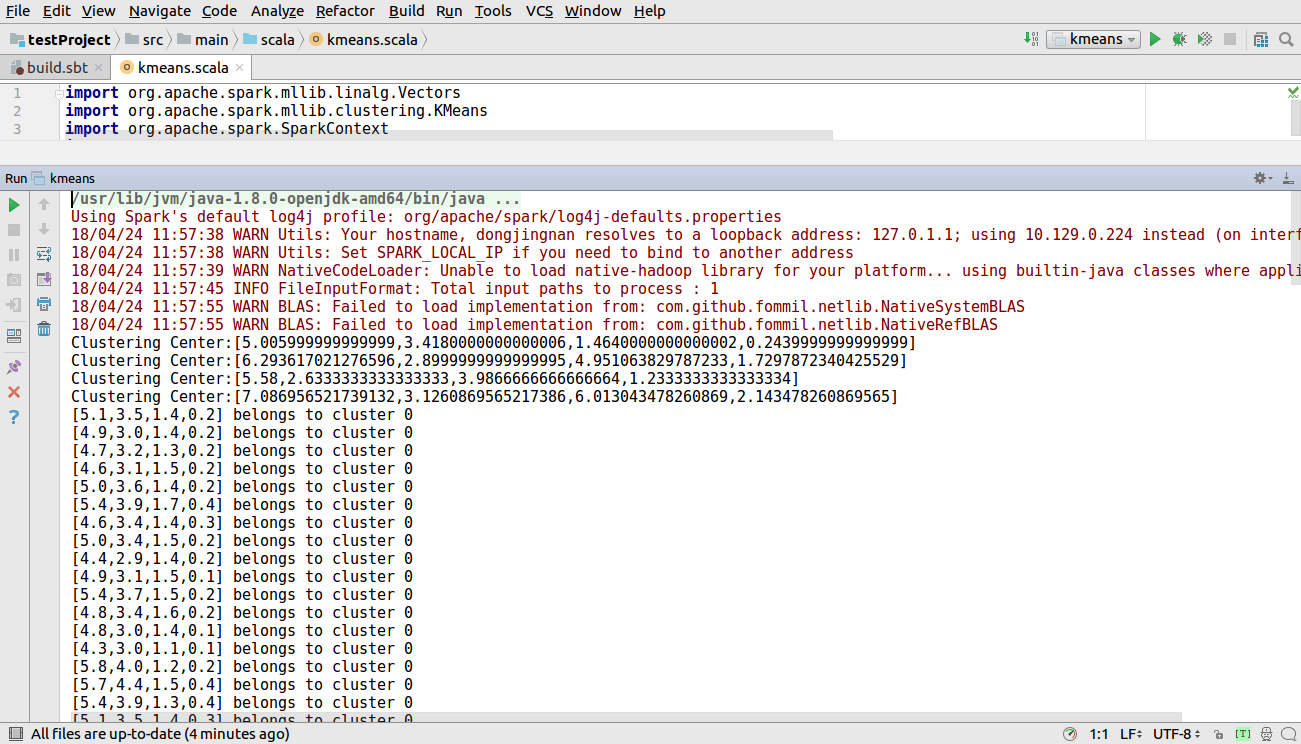
kmeans算法的实现代码如下图所示
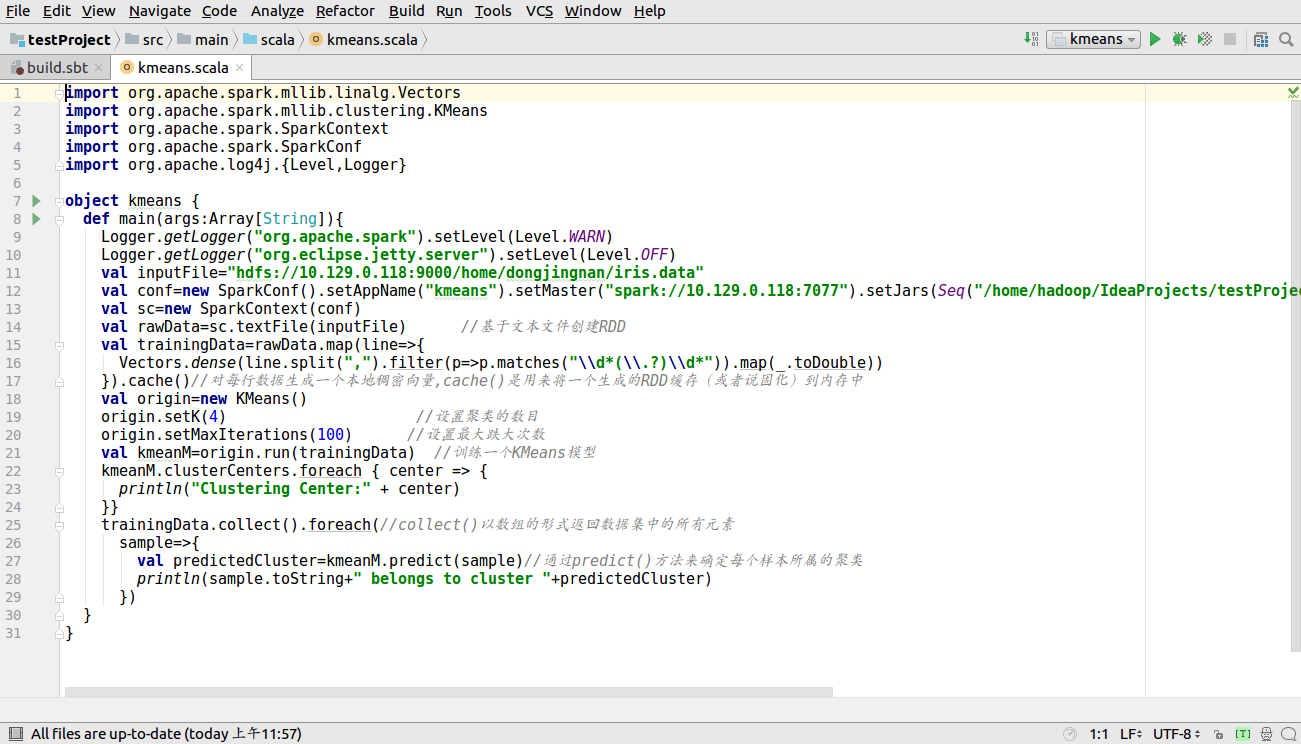
打包过程如下所示,点击file--Project Structure--单击+号
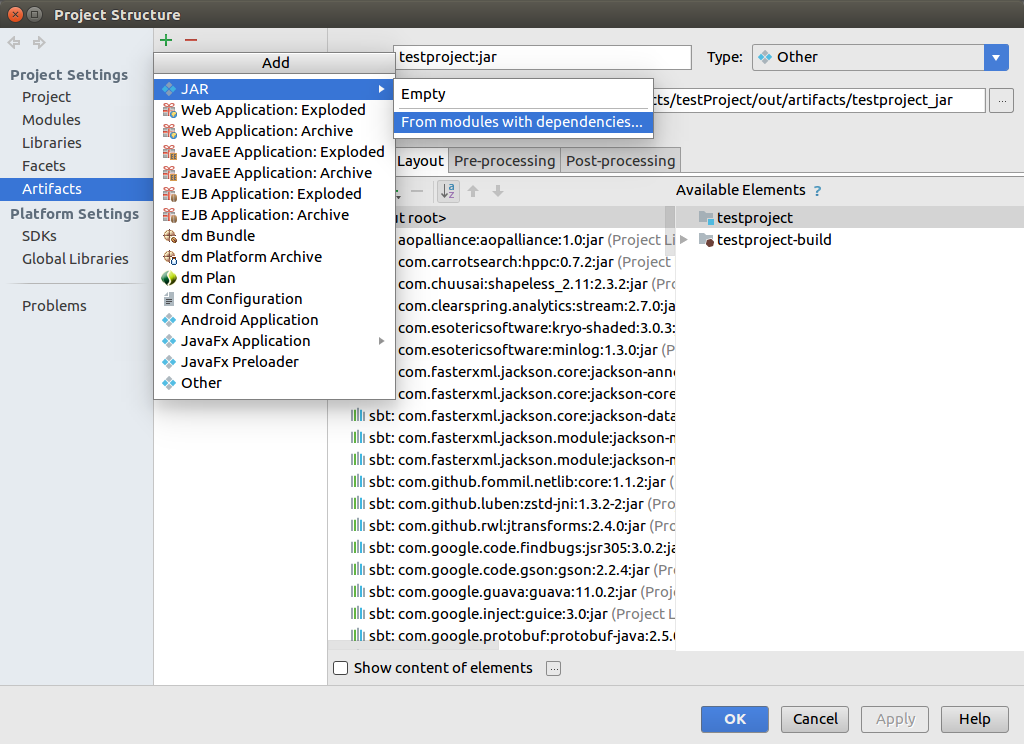
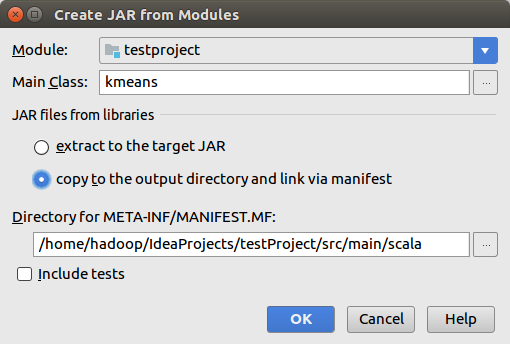
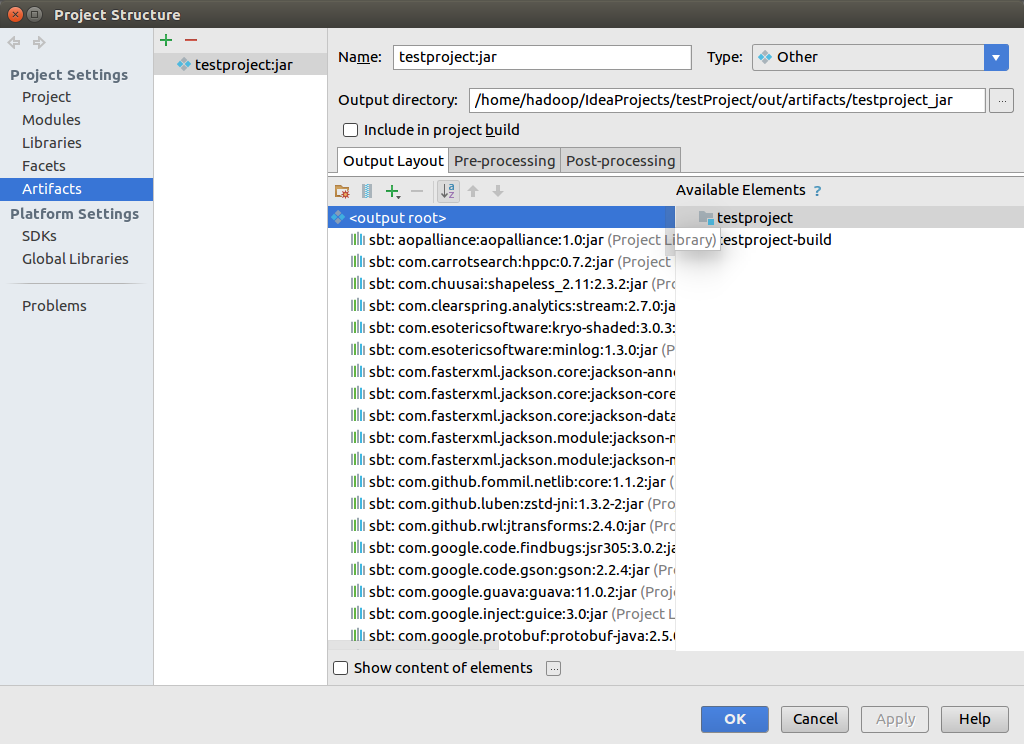
单击Build-Build Artifacts.. 之后在单击下图中的Build
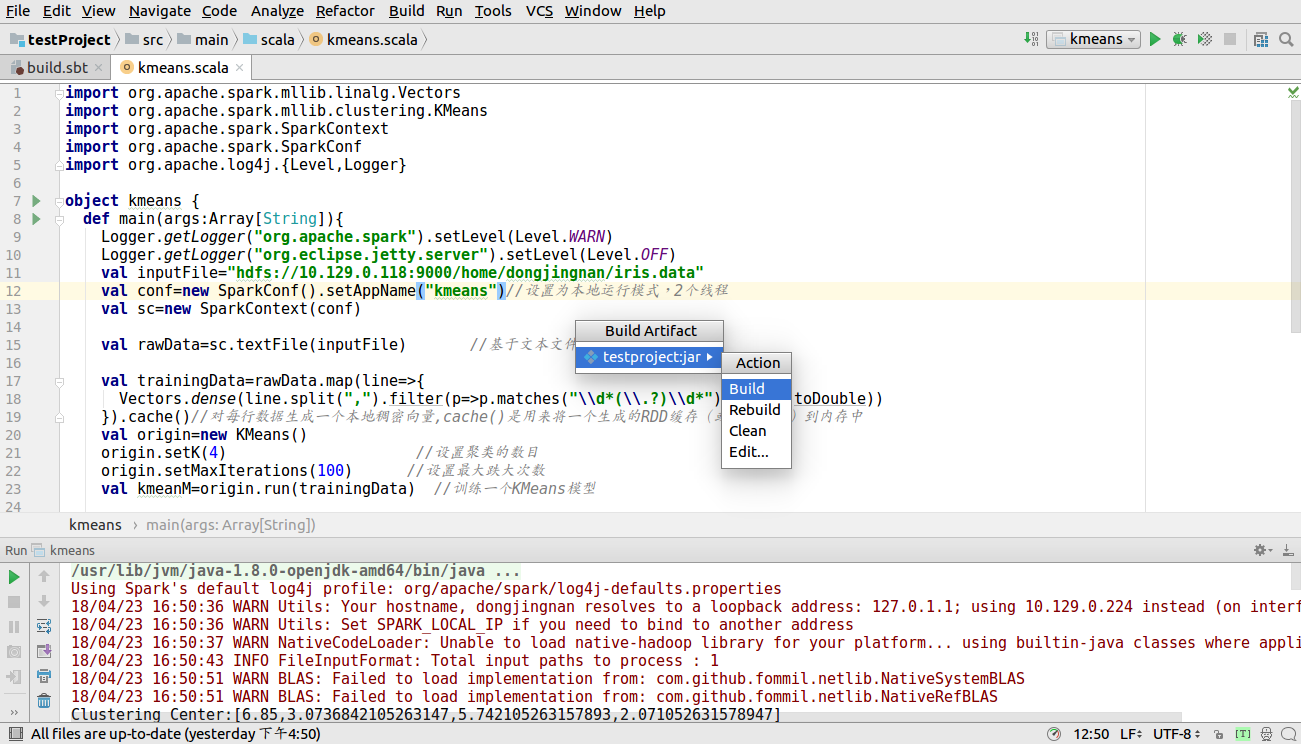
稍等会,可以看到下图中出现out 文件夹
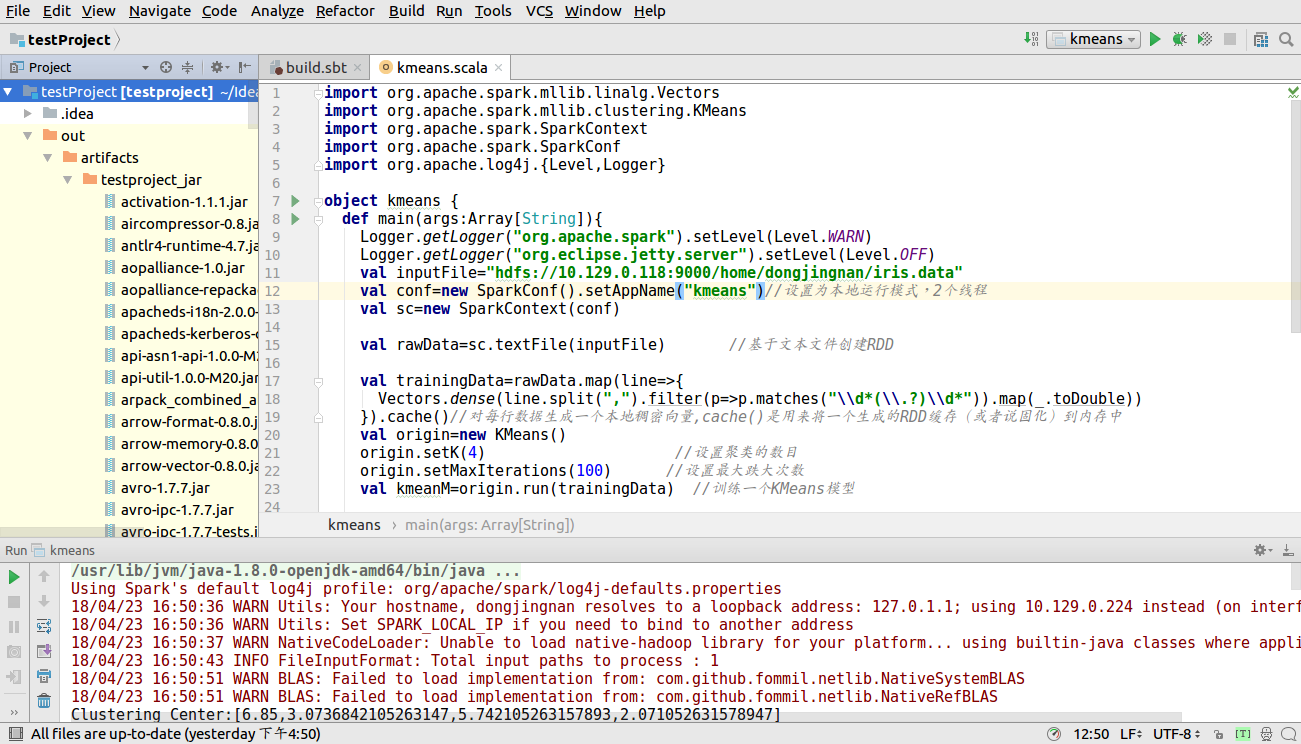
找到项目打包成的jar文件夹,如下图所示
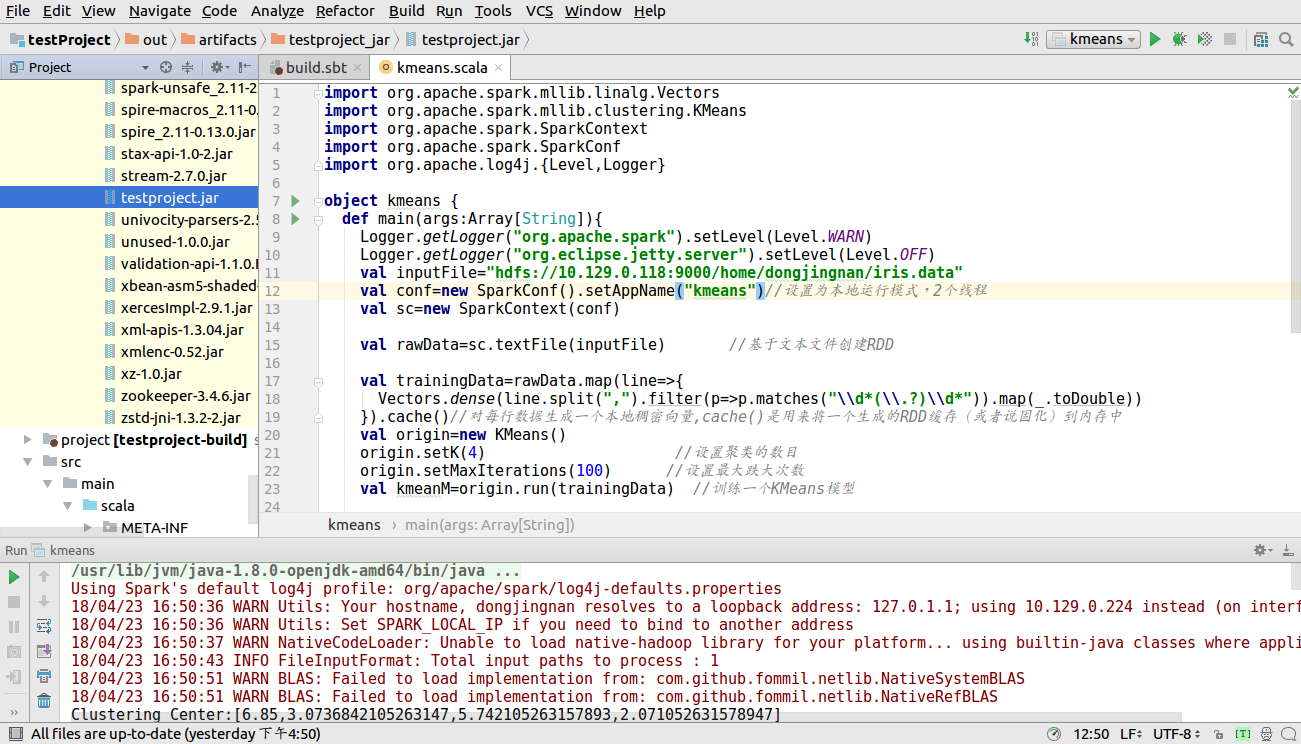
此时设置SparkConf后的setMaster()和setJar()
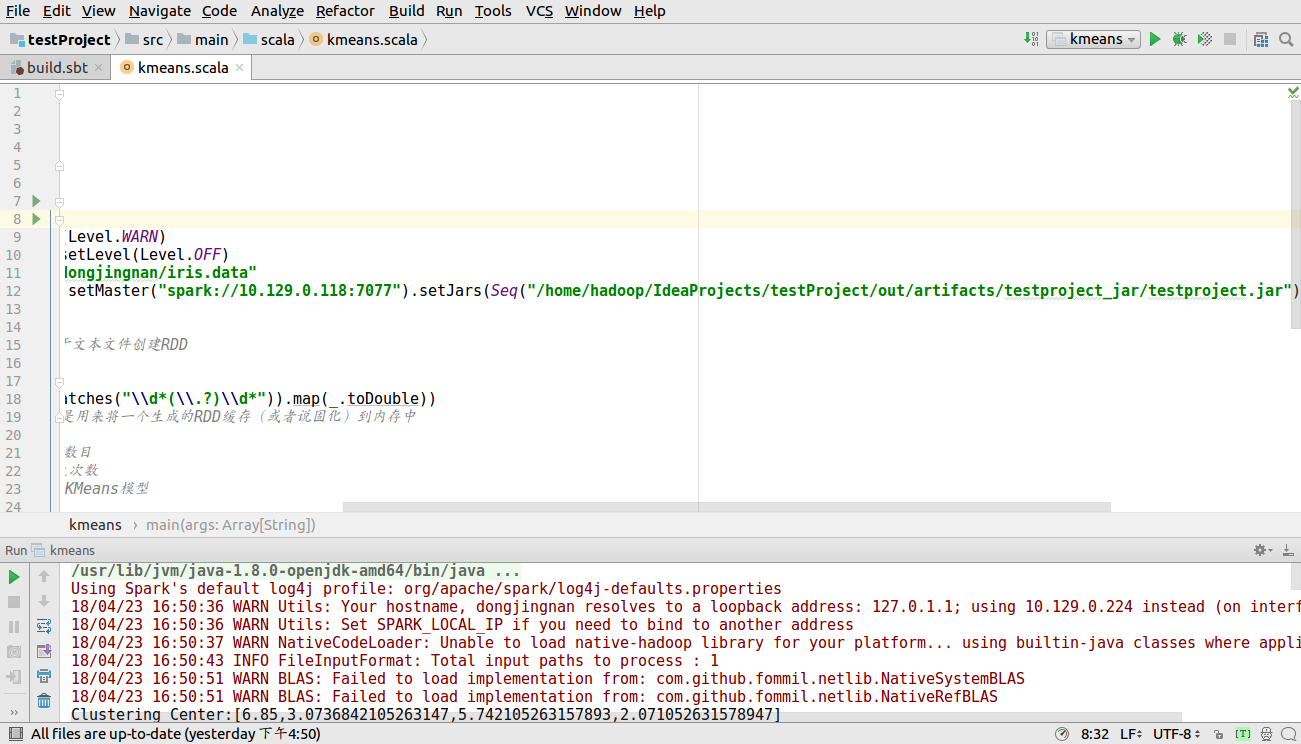
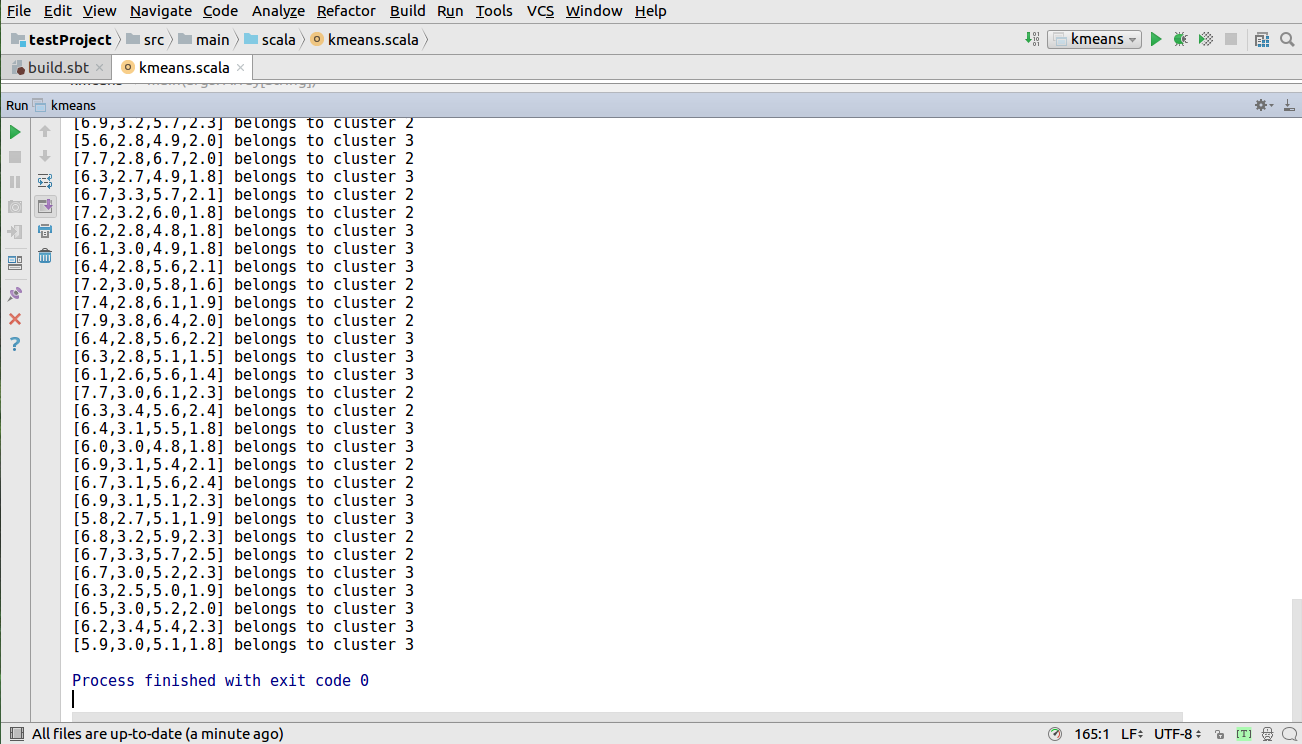
接下来运行程序单击Run-->Run kmeans 出现如下图所示
打开网址htttps://master:7077/查看应用运行情况
到此,整个项目运行完毕。
谢谢观看,不对之处,欢迎多多指正。
IntelliJ IDEA编写的spark程序在远程spark集群上运行的更多相关文章
- Spark优化之二:集群上运行jar程序,状态一直Accepted且不停止不报错
如果运行Spark集群时状态一直为Accepted且不停止不报错,比如像下面这样的情况: 15/06/14 11:33:33 INFO yarn.Client: Application report ...
- [Spark Core] 在 Spark 集群上运行程序
0. 说明 将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行. 1. 打包程序 1.0 前提 搭建好 Spark 集群,完成代码的编写. 1.1 修改代码 [添加内容,判断参数 ...
- 用python + hadoop streaming 编写分布式程序(二) -- 在集群上运行与监控
写在前面 相关随笔: Hadoop-1.0.4集群搭建笔记 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍,样例程序与本地调试 用python + hado ...
- 将java开发的wordcount程序提交到spark集群上运行
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤. 第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /s ...
- 06、部署Spark程序到集群上运行
06.部署Spark程序到集群上运行 6.1 修改程序代码 修改文件加载路径 在spark集群上执行程序时,如果加载文件需要确保路径是所有节点能否访问到的路径,因此通常是hdfs路径地址.所以需要修改 ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- Eclipse提交代码到Spark集群上运行
Spark集群master节点: 192.168.168.200 Eclipse运行windows主机: 192.168.168.100 场景: 为了测试在Eclipse上开发的代码在Spa ...
- 在集群上运行Spark
Spark 可以在各种各样的集群管理器(Hadoop YARN.Apache Mesos,还有Spark 自带的独立集群管理器)上运行,所以Spark 应用既能够适应专用集群,又能用于共享的云计算环境 ...
随机推荐
- Java开篇
首先致敬Java之父:JAMES GOSLING 一.什么是JDK,JRE,JVM? 1.JDK(Java Development Kit) Java开发工具包. JDK = 开 ...
- Jenkins-在节点上执行copy命令,将节点机上的文件拷贝到映射的网络驱动盘中报错,访问被拒绝 找不到指定驱动器
问题如标题,根据网友提供的解决方法,完美解决: 在jenkins中执行这个命令时报错 说无法访问. 重新映射一次可解决这个问题,添加一条 net use 命令
- Q:java中的泛型数组
对于java,其是不支持直接创建泛型数组的.当采用如下的方式去创建一个泛型数组时,其会出现错误,编译无法通过的情况. package other.jdk1_5; /** * 该类用于演示泛型数组的创 ...
- Cause: com.microsoft.sqlserver.jdbc.SQLServerException: 不支持“variant”数据类型。
mybatis执行sqlserver的sql报错 com.microsoft.sqlserver.jdbc.SQLServerException: 不支持“variant”数据类型. at com.m ...
- ajax+json+ashx实现一个页面多个tab的分页
1:项目功能需求:我的荣誉.审核中的荣誉.审核通过的荣誉在一个页面分别作列表展示.每个tab都需要分页,对实现的功能做个简单总结. 2:前台页面:引用的DBPage.js和pageCss.css实现分 ...
- 为什么推荐用ui-router替代ngRoute
初学angularjs,第一个实例是官网的phoneCat,里面路由用的是ngRoute,后来看到别的用ui-router,觉得好奇,ui-route是什么呢?百度一些,得到如下解释: ui-rout ...
- mybatis大框架
MyBatis 开源的数据持久化层框架 实体类与SQL语句之间建立映射关系 一:MyBatis前身是IBatis,本是Apache的一个开源的项目, 基于SQL语法,简单易学 ,是耦合度降低,方便 ...
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
- Linux案例01:eth0网卡异常
一.现象描述 今天在调试两台物理机,做完配置重启主机后,发现一台服务器网络无法ssh连接,通过ILO进去ifconfig发现eth0配置的IP地址等信息丢失,手动重启后,可以ssh连接,但过一段时间, ...
- Java学习---IO操作
基础知识 1.文件操作 Java语言统一将每个文件都视为一个顺序字节流.每个文件或者结束于一个文件结束标志,或者根据系统维护管理数据中所纪录的具体字节数来终止.当一个文件打开时,一个对象就被创建,同时 ...