scrapy-splash抓取动态数据例子九
一、介绍
本例子用scrapy-splash抓取众视网网站给定关键字抓取咨询信息。
给定关键字:个性化;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
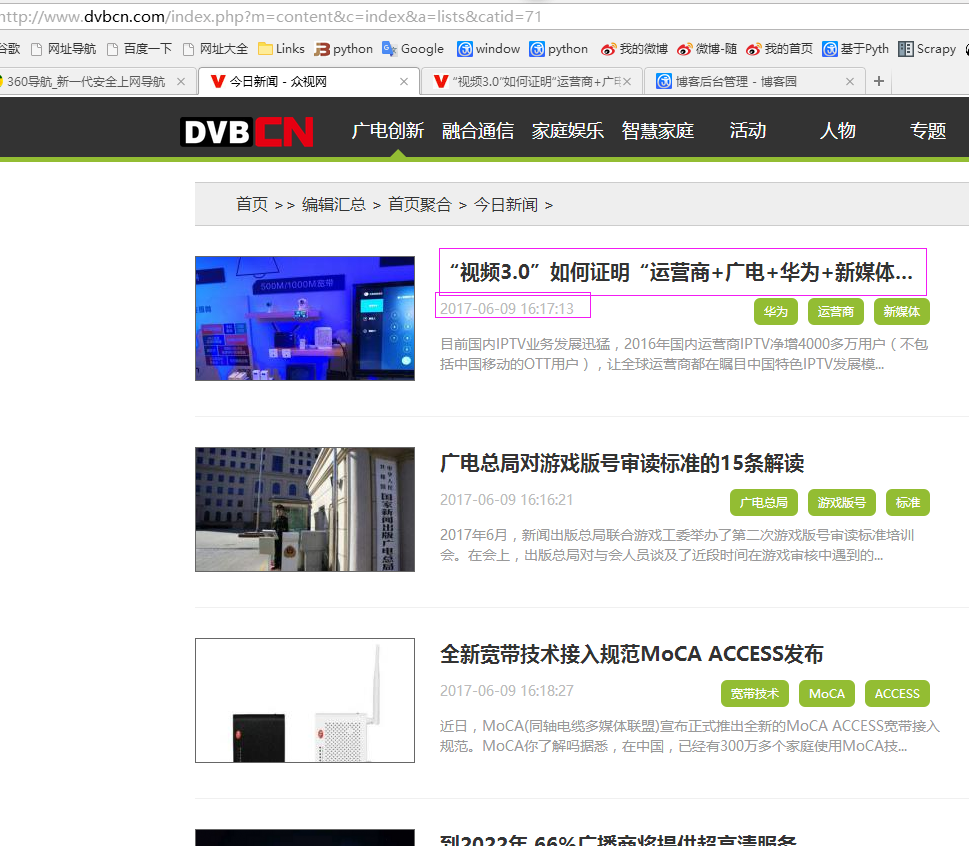


三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
抓取代码:sels = site.xpath('//div[@class="topic overfl"]')
2、抓取标题
抓取代码:title = sel.xpath('.//div[@class="info"]/h3/a/text()')[0].extract()
3、抓取链接
抓取代码:url = 'http://www.dvbcn.com' + str(sel.xpath('.//div[@class="info"]/h3/a/@href')[0].extract())
4、抓取日期
抓取代码:strdate = sel.xpath('.//span[@class="time"]/text()')[0].extract()
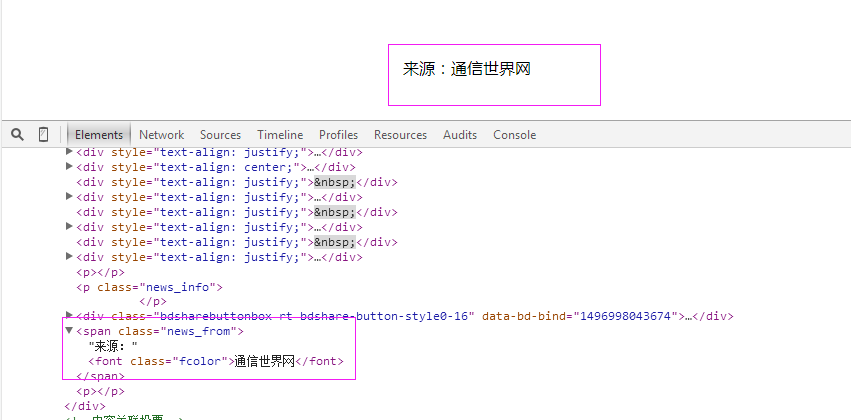
5、抓取来源
抓取代码:sources = site.xpath('//span[@class="news_from"]/font/text()')
四、完整代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy_splash import SplashRequest
from scrapy_splash import SplashMiddleware
from scrapy.http import Request, HtmlResponse
from scrapy.selector import Selector
from scrapy_splash import SplashRequest
from splash_test.items import SplashTestItem
import IniFile
import sys
import os
import re
import time reload(sys)
sys.setdefaultencoding('utf-8') # sys.stdout = open('output.txt', 'w') class dvbcnSpider(Spider):
name = 'dvbcn' configfile = os.path.join(os.getcwd(), 'splash_test\spiders\setting.conf') cf = IniFile.ConfigFile(configfile)
information_wordlist = cf.GetValue("section", "information_keywords").split(';')
websearch_urls = cf.GetValue("dvbcn", "websearchurl").split(';')
start_urls = []
for url in websearch_urls:
print url
start_urls.append(url) # request需要封装成SplashRequest
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url
, self.parse
, args={'wait': ''}
) def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText):
currentDate = time.strftime('%Y-%m-%d')
datePattern = re.compile(r'\d{4}-\d{1,2}-\d{1,2}')
strDate = re.findall(datePattern, strDateText)
if len(strDate) == 1:
if self.Comapre_to_days(currentDate,strDate[0])==0:
return True,currentDate
return False, ''
def parse(self, response): site = Selector(response)
sels = site.xpath('//div[@class="topic overfl"]')
for sel in sels:
strdate = sel.xpath('.//span[@class="time"]/text()')[0].extract()
flag, date = self.date_isValid(strdate)
if flag:
title = sel.xpath('.//div[@class="info"]/h3/a/text()')[0].extract()
url = 'http://www.dvbcn.com' + str(sel.xpath('.//div[@class="info"]/h3/a/@href')[0].extract()) for keyword in self.information_wordlist:
if title.find(keyword) > -1:
yield SplashRequest(url
, self.parse_item
, args={'wait': ''},
meta={'date': date, 'url': url,
'keyword': keyword, 'title': title}
) def parse_item(self, response):
site = Selector(response)
it = SplashTestItem()
it['title'] = response.meta['title']
it['url'] = response.meta['url']
it['date'] = response.meta['date']
it['keyword'] = response.meta['keyword']
sources = site.xpath('//span[@class="news_from"]/font/text()')
if len(sources)>0:
it['source'] = sources[0].extract()
return it
scrapy-splash抓取动态数据例子九的更多相关文章
- scrapy-splash抓取动态数据例子一
目前,为了加速页面的加载速度,页面的很多部分都是用JS生成的,而对于用scrapy爬虫来说就是一个很大的问题,因为scrapy没有JS engine,所以爬取的都是静态页面,对于JS生成的动态页面都无 ...
- scrapy-splash抓取动态数据例子八
一.介绍 本例子用scrapy-splash抓取界面网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子七
一.介绍 本例子用scrapy-splash抓取36氪网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子六
一.介绍 本例子用scrapy-splash抓取中广互联网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子五
一.介绍 本例子用scrapy-splash抓取智能电视网网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站 ...
- scrapy-splash抓取动态数据例子四
一.介绍 本例子用scrapy-splash抓取微众圈网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子三
一.介绍 本例子用scrapy-splash抓取今日头条网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子二
一.介绍 本例子用scrapy-splash抓取一点资讯网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子十六
一.介绍 本例子用scrapy-splash爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电 ...
随机推荐
- go的websocket实现
websocket分为握手和数据传输阶段,即进行了HTTP握手 + 双工的TCP连接 RFC协议文档在:http://tools.ietf.org/html/rfc6455 握手阶段 握手阶段就是普通 ...
- CDN缓存(转载)
CDN缓存那些事(转载) 原文地址:http://bbs.qcloud.com/forum.php?mod=viewthread&tid=3775 注:原文全文复制,仅仅作为自己下次学习备份, ...
- Appium+python自动化28-name定位【转载】
本篇转自博客:上海-悠悠 前言 appium1.5以下老的版本是可以通过name定位的,新版本从1.5以后都不支持name定位了 一. name定位报错 1.最新版appium V1.7用name定位 ...
- magento 报错及解决方法
在后台安装主题包时安装出错,重新进入后台进不去,前台也进不去,提示“Service Temporarily Unavailable” 删除根目录下的maintenance.flag文件即可.
- Unity中Instantiate物体失效问题
才开始学Unity,开始总是这样用Instantiate函数: GameObject temp = (GameObject)Instantiate(bulletSource, transform.po ...
- centos6.5 python2.7.8 安装scrapy总是出错【解决】
pip install Scrapy 报错: UnicodeDecodeError: 'ascii' codec can't decode byte 0xb4 in position python s ...
- 使用 Hibernate 完成 HibernateUtils 类 (适用于单独使用Hibernate或Struts+Hibernate)
package com.istc.Utilities; import org.hibernate.Session; import org.hibernate.SessionFactory; impor ...
- MySQL 将某个字段值的记录排在最后,其余记录单独排序
1.按 status 值 2 5 3 的顺序排序,值相同则按修改时间排序 order by FIELD(status,2,5,3),a.ModifyTime desc 2.将 status = 3 的 ...
- matlab的table数据类型初步接触
由于数据分析,接触到cell的使用,字符串的使用以及ASCII的使用,但是发现在matlab中进行这样的操作相对繁琐,然后知道了table数据类型,是matlab新的数据类型,于2013版开始引入.据 ...
- python aiohttp sancio 框架性能测试
开头先啰嗦两句: 由于本人有开发一个博客的打算,所以近期开始选型python的web框架重头学习,选了两款非常火的 aio web框架 aiohttp 和 sancio 进行性能测试以及开发喜好的调研 ...