Python爬虫之利用BeautifulSoup爬取豆瓣小说(二)——回车分段打印小说信息
在上一篇文章中,我主要是设置了代理IP,虽然得到了相关的信息,但是打印出来的信息量有点多,要知道每打印一页,15个小说的信息全部会显示而过,有时因为屏幕太小,无法显示全所有的小说信息,那么,在这篇文章中,我主要想通过设置回车来控制每一条小说信息的输出,当我按下回车时,会显示下一条小说的信息,按“Q”时,会退出程序,同时,这个方法还会根据包含小说信息的页面数量来决定是否加载新的一页。
首先,我们导入一些模块,定义一个类,初始化方法,定义一些变量:
self.Novels里存放的是小说信息的变量,每一个元素是每一页的小说信息们
self.load决定程序是否继续运行的变量
#-*-coding:utf-8-*-
import urllib2
from bs4 import BeautifulSoup
class dbxs:
def __init__(self):
self.pageIndex = 0
self.Novels = []
self.load = False
然后,我们获得html页面的内容,在这里,我们为了能够得到信息,而不让豆瓣服务器查封我们的IP,我们设置了请求的头部信息headers和代理IP。
def getPage(self, pageIndex):
#设置代理IP
enable_proxy = True
proxy_handler = urllib2.ProxyHandler({'Http': '116.30.251.210:8118'})
null_proxy_handler = urllib2.ProxyHandler({})
if enable_proxy:
opener = urllib2.build_opener(proxy_handler)
else:
opener = urllib2.build_opener(null_proxy_handler)
urllib2.install_opener(opener)
#设置headers,模拟浏览器登录
try:
url = 'https://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/book' +'?start=' + str(pageIndex)
my_headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0)'}
request = urllib2.Request(url, headers = my_headers)
response = urllib2.urlopen(request)
return response.read()
19 except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
if hasattr(e, "reason"):
print e.reason
return None
我们获得的是html源码,源码里有包含我们想要的元素,但是为了方便抓取数据,利用BeautifulSoup解析文档,这里我们用的解析器是html.parser。
这里的pageNovels是一个列表,存放的是每一页的所有小说信息,当某一小说信息没有rate一项时,这一条小说信息没有rates。
def getPageItems(self, pageIndex):
pageCode = self.getPage(pageIndex)
soup = BeautifulSoup(pageCode, 'html.parser')
contents = soup.find_all('dd')
pageNovels = []
if contents:
for item in contents:
title = item.find(class_ = 'title').string
info = item.find(class_ = 'desc').string.strip()
rate = item.find(class_ = 'rating_nums') #这里不能加string,如果rate不存在,那么程序会报错:NoneType没有.string属性
if rate:
rates = rate.string
pageNovels.append([title, info, rates])
else:
pageNovels.append([title, info])
return pageNovels
else:
pageNovels.append('end')
return pageNovels
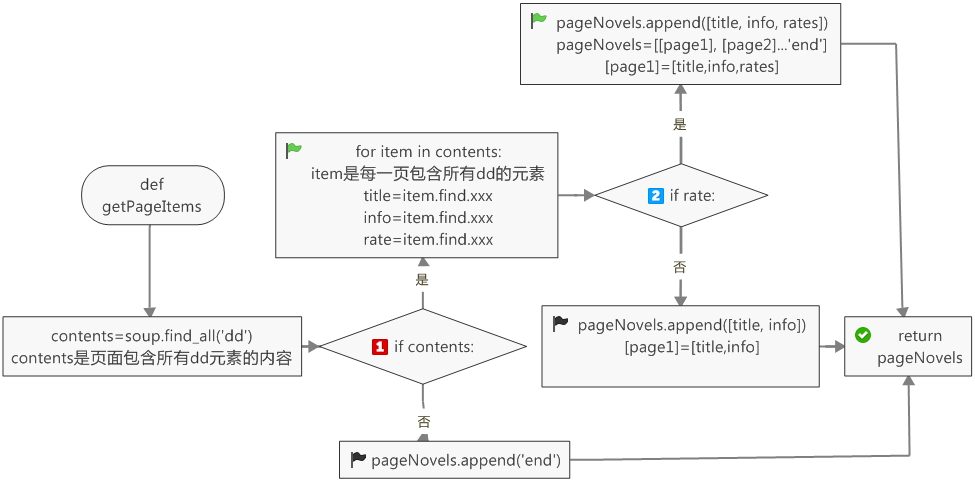
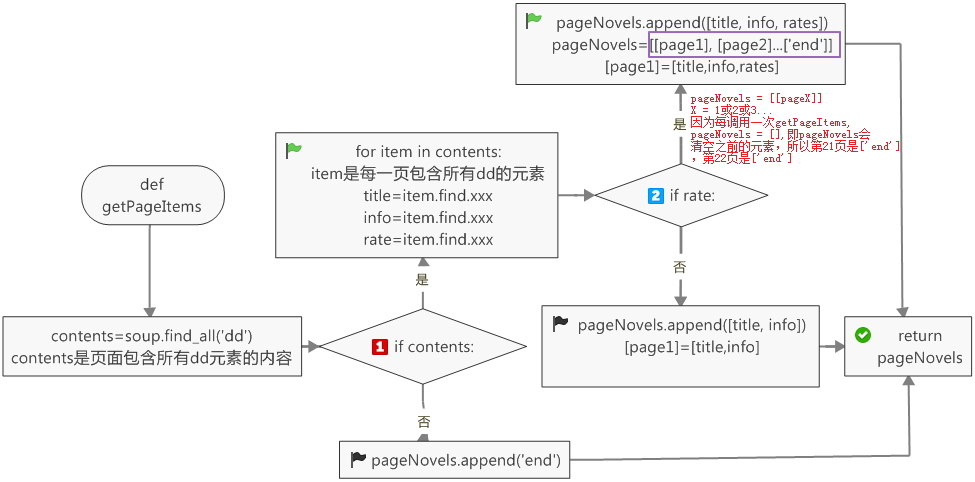
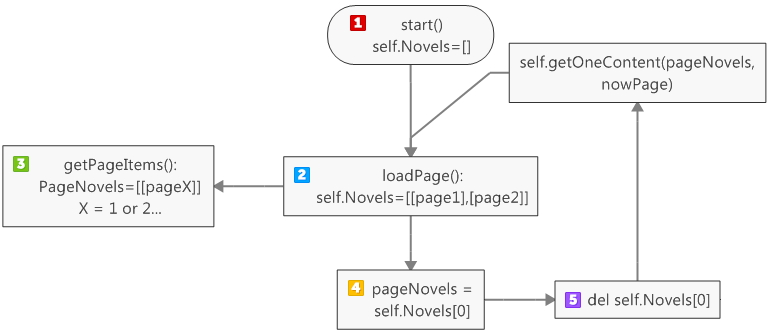
需要定义一个加载页,当self.Novels里的页数小于2,则程序加载下一页
def loadPage(self):
if self.load == True:
if len(self.Novels) < 2:
pageNovels = self.getPageItems(self.pageIndex)
if pageNovels:
self.Novels.append(pageNovels)
self.pageIndex += 15
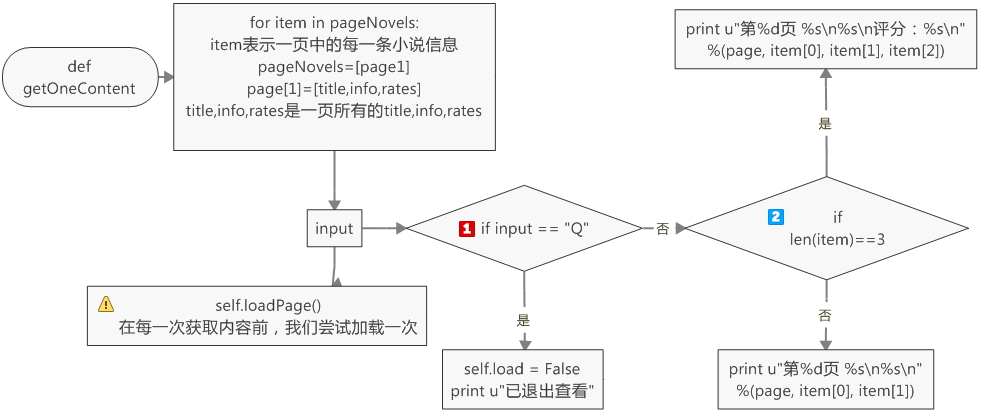
为了获得每一页的每一条小说信息,我们需要定义一个getOneContent的方法
def getOneContent(self, pageNovels, page):
for item in pageNovels:
input = raw_input()
self.loadPage()
if input == "Q":
self.load = False
print u"已退出查看"
return None
#if item[2]: #这里不能用if itme[2],当item[2]不存在时,会报错
if len(item) == 3:
print u"第%d页 %s\n%s\n评分:%s\n" %(page, item[0], item[1], item[2])
else:
print u"第%d页 %s\n%s\n" %(page, item[0], item[1])
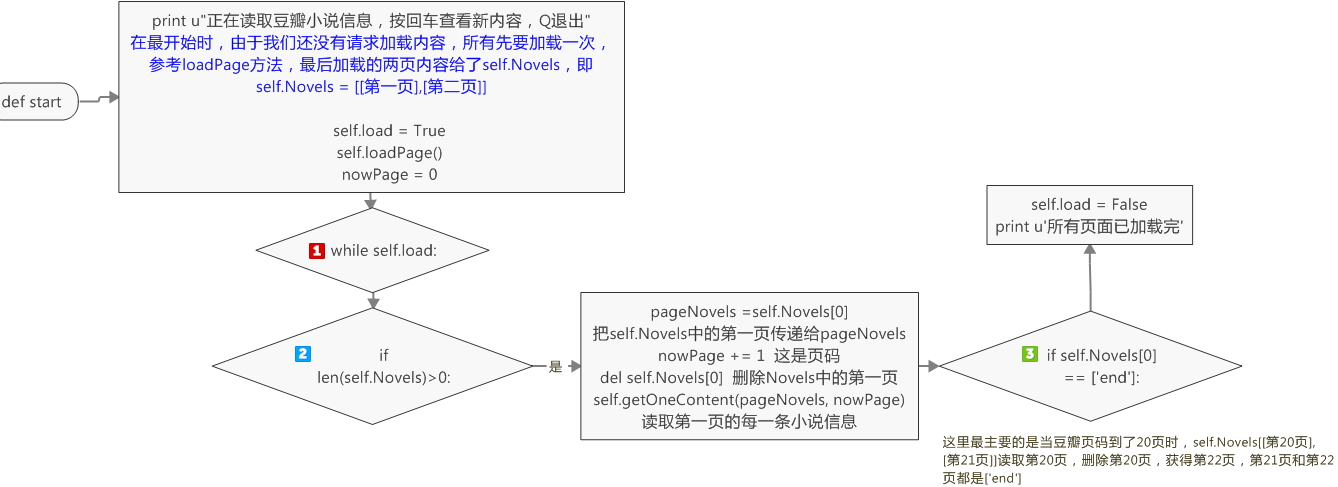
最后,我们得定义一个开始方法
def start(self):
print u"正在读取豆瓣小说信息,按回车查看新内容,Q退出"
self.load = True
self.loadPage()
nowPage = 0
while self.load:
if len(self.Novels) > 0:
pageNovels = self.Novels[0]
nowPage += 1
del self.Novels[0]
self.getOneContent(pageNovels, nowPage)
if self.Novels[0] == ['end']:
self.load = False
print u'所有页面已加载完'
整理一下,最后的总代码:
#-*-coding:utf-8-*-
import urllib2
from bs4 import BeautifulSoup
import time
import random
class dbxs:
def __init__(self):
self.pageIndex = 0
self.Novels = []
self.load = False
#获取html页面的内容
def getPage(self, pageIndex):
#设置代理ip
enable_proxy = True
proxy_handler = urllib2.ProxyHandler({'Http': '116.30.251.210:8118'})
null_proxy_handler = urllib2.ProxyHandler({})
if enable_proxy:
opener = urllib2.build_opener(proxy_handler)
else:
opener = urllib2.build_opener(null_proxy_handler)
urllib2.install_opener(opener)
try:
url = 'https://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/book' + "?start=" + str(pageIndex)
#设置请求头部信息,模拟浏览器的行为
my_headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0)'}
request = urllib2.Request(url, headers = my_headers)
response = urllib2.urlopen(request)
return response.read()
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
if hasattr(e, "reason"):
print e.reason
return None
def getPageItems(self, pageIndex):
pageCode = self.getPage(pageIndex)
soup = BeautifulSoup(pageCode, 'html.parser')
contents = soup.find_all('dd')
pageNovels = []
if contents:
for item in contents:
title = item.find(class_ = 'title').string
info = item.find(class_ = 'desc').string.strip()
rate = item.find(class_ = 'rating_nums') #这里不能加string,如果rate不存在,那么程序会报错:NoneType没有.string属性
if rate:
rates = rate.string
pageNovels.append([title, info, rates])
else:
pageNovels.append([title, info])
return pageNovels
else:
pageNovels.append('end')
return pageNovels
def loadPage(self):
if self.load == True:
if len(self.Novels) < 2:
pageNovels = self.getPageItems(self.pageIndex)
if pageNovels:
self.Novels.append(pageNovels)
self.pageIndex += 15
#打印每一个小说的信息
def getOneContent(self, pageNovels, page):
for item in pageNovels:
input = raw_input()
self.loadPage()
if input == "Q":
self.load = False
print u"已退出查看"
return None
#if item[2]: #这里不能用if itme[2],当item[2]不存在时,会报错
if len(item) == 3:
print u"第%d页 %s\n%s\n评分:%s\n" %(page, item[0], item[1], item[2])
else:
print u"第%d页 %s\n%s\n" %(page, item[0], item[1])
#创建一个开始方法
def start(self):
print u"正在读取豆瓣小说信息,按回车查看新内容,Q退出"
self.load = True
self.loadPage()
nowPage = 0
while self.load:
if len(self.Novels) > 0:
pageNovels = self.Novels[0]
nowPage += 1
del self.Novels[0]
self.getOneContent(pageNovels, nowPage)
if self.Novels[0] == ['end']:
self.load = False
print u'所有页面已加载完'
DBXS = dbxs()
DBXS.start()
有必要解释一下self.Novels和PageNovels
Python爬虫之利用BeautifulSoup爬取豆瓣小说(二)——回车分段打印小说信息的更多相关文章
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(一)——设置代理IP
自己写了一个爬虫爬取豆瓣小说,后来为了应对请求不到数据,增加了请求的头部信息headers,为了应对豆瓣服务器的反爬虫机制:防止请求频率过快而造成“403 forbidden”,乃至封禁本机ip的情况 ...
- python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息
1.问题描述: 爬取链家深圳二手房的详细信息,并将爬取的数据存储到Excel表 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目标网址:https://sz.lianjia.com ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(三)——将小说信息写入文件
#-*-coding:utf-8-*- import urllib2 from bs4 import BeautifulSoup class dbxs: def __init__(self): sel ...
- python爬虫:利用正则表达式爬取豆瓣读书首页的book
1.问题描述: 爬取豆瓣读书首页的图书的名称.链接.作者.出版日期,并将爬取的数据存储到Excel表格Douban_I.xlsx中 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目 ...
- Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢.本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快. 本次爬取的豆瓣书籍排行榜的首页地 ...
- Python爬虫之利用正则表达式爬取内涵吧
首先,我们来看一下,爬虫前基本的知识点概括 一. match()方法: 这个方法会从字符串的开头去匹配(也可以指定开始的位置),如果在开始没有找到,立即返回None,匹配到一个结果,就不再匹配. 我们 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
随机推荐
- VCL控件组件大都应该重载TWinControl的虚函数WndProc来进行处理窗口消息的工作
TWinControl的构造函数中会调用MakeObjectInstance并且传递MainWndProc作为窗口消息处理函数,而MainWndProc则会调用虚函数WndProc来处理窗口消息.留个 ...
- echarts系列之动态加载数据
1.echarts学习前言 最近接触到echarts,发现数据可视化真的是魅力无穷啊,各种变幻的曲线交错,以及‘曼妙’的动画效果真是让人如痴如醉! 下面就来一起欣赏她的美... “ ECharts是中 ...
- MySQL中myisam和innodb的主键索引有什么区别?
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址.下图是MyISAM索引的原理图: 这里设表一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索 ...
- rpm命令相关命令运用实例
1) 挂载光盘文件到/media目录 2) 进去/media目录下的Packages目录 3) 查看系统已安装的所有rpm包 4) 查看系统是否安装dhcp软件包 5,安装dhcp软件包 6) 查看d ...
- Java 线程控制(输出奇偶数)
两个线程,一个输出1,3,5,7......99:另一个输出2,4,6,8......100. 1.线程同步 public class ST2 { int i = 0; public static v ...
- jquery on 确认删除
$(document).on('click', '.delbtn', function() { if (confirm("确定要删除吗?")) { ...
- 20170524 委外采购的物料BOM
目标:找委外采购订单BOM, 我的方法:1.直接在电脑中搜索关键字:2.到系统中找数据查询3.委外采购订单系统如何操作? 数据怎么做, 实施: 结果:MDBAEKET, "采购订单项目计划行 ...
- 20170401 错了两天的-XML解析
你不找到的话,错误就在那里.你找到了错误才会成为财富! Strans XML 解析3要素:1.源xml 格式正常, eg. '<?xml version="1.0" enco ...
- 剑指offer 面试41题
面试41题: 题目:数据流中的中位数 题:如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值.如果从数据流中读出偶数个数值,那么中位数就是所有数值 ...
- mysql分组查询
有一张学生选课表 Table: Subject_Selection Subject Semester Attendee --------------------------------- ITB001 ...