Python爬虫之利用正则表达式爬取内涵吧
首先,我们来看一下,爬虫前基本的知识点概括
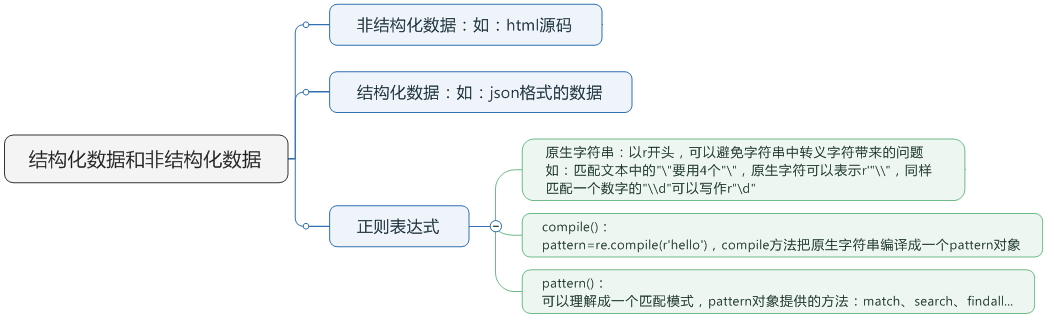
一. match()方法:
这个方法会从字符串的开头去匹配(也可以指定开始的位置),如果在开始没有找到,立即返回None,匹配到一个结果,就不再匹配。
我们可以指定开始的位置的索引是3,范围是3-10,那么python将从第4个字符'1'开始匹配,只匹配一个结果。
group()获得一个或多个分组的字符串,指定多个字符串时将以元组的形式返回,group(0)代表整个匹配的字串,不填写参数时,group()返回的是group(0)。
import re
pattern = re.compile(r'\d+') #匹配数字一次以上
m = pattern.match('one123two456')
print m
print m.group()
#None
#...AttributeError: 'NoneType' object has no attribute 'group'
pattern = re.compile(r'\d+') #匹配数字一次以上
m = pattern.match('one123two456'. 3, 10)
print m
print m.group()
#<_sre.SRE_Match object at 0x00000000026FAE68>
二. search()方法:
search方法与match比较类似,区别在于match()方法只检测是不是在字符串的开始位置匹配,search()会扫描整个字符串查找匹配,同样,search方法只匹配一次。
import re
pattern = re.compile(r'\d+')
m = pattern.search('one123two456')
print m.group()
三. findall()方法:
搜索字符串,以列表的形式返回全部能匹配的字串。
import re
pattern = re.compile(r'\d+')
m = pattern.findall('one123two456')
print m
#['123', '456']
四. sub()方法:
用来替换每一个匹配的字符串,并返回替换后的字符串。
import re
pattern = re.compile(r'\d+')
m = pattern.sub('abc', 'one123two456')
print m
#oneabctwo456
五. 实践:爬取内涵吧段子
#-*-coding:utf-8-*-
import requests
import re
class Spider:
def __init__(self):
self.page = 1
def getPage(self, page):
url = "http://www.neihan8.com/article/list_5_{}.html".format(page)
response = requests.get(url)
contents = response.content.decode('gbk') #查看网页源代码,内涵吧默认编码是charset=gb2312
return contents
def getContent(self):
contents = self.getPage(self.page)
pattern = re.compile('<h4>.*?<a href.*?html">(.*?)</a>.*?class="f18 mb20">(.*?)</div>', re.S)
results = pattern.findall(contents)
contents = []
for item in results:
title = re.sub('<b>|</b>', "", item[0])
content = re.sub(r'<p>|</p>|<br />|&\w+;|<img alt.*|<div style=.*>|<div>|<p style="text-align: center; ">', "", item[1])
content = re.sub(r'<div class="upload-txt.*baseline;">|<h1 class="title".*vertical-align: baseline;">|</h1>', "", content)
content = re.sub(r'<div class=.*onclick="showAnswer(this)">|</a><div class="answer">', "", content)
content = re.sub(r'<span style="color: rgb.*;">', "", content)
contents.append([title, content])
return contents
def save_Data(self):
file = open("duanzi.txt", "w+")
x = 1
y = 1
for self.page in range(0, 507):
contents = self.getContent()
print u"正在写入第%d页的数据..." %(self.page+1)
for item in contents:
file.write(str(x) + "." + item[0])
file.write("\n")
file.write(item[1])
file.write("=====================================================================================\n\n")
if item==contents[-1]:
file.write(u"********第" + str(y) + "页完********\n\n")
y += 1
x += 1
print u"所有页面已加载完"
def start(self):
self.save_Data()
spider = Spider()
spider.start()
基本上可以获取段子的标题和内容,但由于内涵吧的段子越到后面标签越复杂,所以给替换标签带来了很大的难度。
Python爬虫之利用正则表达式爬取内涵吧的更多相关文章
- python爬虫:利用正则表达式爬取豆瓣读书首页的book
1.问题描述: 爬取豆瓣读书首页的图书的名称.链接.作者.出版日期,并将爬取的数据存储到Excel表格Douban_I.xlsx中 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目 ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(一)——设置代理IP
自己写了一个爬虫爬取豆瓣小说,后来为了应对请求不到数据,增加了请求的头部信息headers,为了应对豆瓣服务器的反爬虫机制:防止请求频率过快而造成“403 forbidden”,乃至封禁本机ip的情况 ...
- Python爬虫学习之正则表达式爬取个人博客
实例需求:运用python语言爬取http://www.eastmountyxz.com/个人博客的基本信息,包括网页标题,网页所有图片的url,网页文章的url.标题以及摘要. 实例环境:pytho ...
- python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息
1.问题描述: 爬取链家深圳二手房的详细信息,并将爬取的数据存储到Excel表 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目标网址:https://sz.lianjia.com ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(二)——回车分段打印小说信息
在上一篇文章中,我主要是设置了代理IP,虽然得到了相关的信息,但是打印出来的信息量有点多,要知道每打印一页,15个小说的信息全部会显示而过,有时因为屏幕太小,无法显示全所有的小说信息,那么,在这篇文章 ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(三)——将小说信息写入文件
#-*-coding:utf-8-*- import urllib2 from bs4 import BeautifulSoup class dbxs: def __init__(self): sel ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
随机推荐
- Thinking In Myself
what is the I want to be? you know yourself? what is your dream? your interest? your passion? why y ...
- ABAP 创建测试文件
使用 CG3Y 下载,可以改成下载txt到本地. FORM CREATE_TESTFILE. ), L_OFF LIKE SY-TABIX, L_LEN LIKE SY-TABIX, L_SUM LI ...
- 1.3 使用电脑测试MC20的电话语音功能
需要准备的硬件 MC20开发板 1个 https://item.taobao.com/item.htm?id=562661881042 GSM/GPRS天线 1根 https://item.taoba ...
- python 文件格式为 txt 转换成 csv 格式
1 txt 文件的读取 open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=Tr ...
- 玩转git版本控制软件
一.git的基本介绍 1.什么是git? git是个开源的分布式版本控制软件,用以有效.高速的处理从很小到非常大的项目版本管理.说白了就是个版本控制软件 2.git的使用方法 git软件是通过命令来实 ...
- 剑指offer 面试51题
面试51题: 题目:数组中的逆序对 题目描述 在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对.输入一个数组,求出这个数组中的逆序对的总数P.并将P对1000000007 ...
- Android:日常学习笔记(8)———探究UI开发(2)
Android:日常学习笔记(8)———探究UI开发(2) 对话框 说明: 对话框是提示用户作出决定或输入额外信息的小窗口. 对话框不会填充屏幕,通常用于需要用户采取行动才能继续执行的模式事件. 提示 ...
- Django~1
一 什么是web框架? 框架,即framework,特指为解决一个开放性问题而设计的具有一定约束性的支撑结构,使用框架可以帮你快速开发特定的系统,简单地说,就是你用别人搭建好的舞台来做表演. 对于所有 ...
- facebook开源了他们的分布式大数据DB
https://github.com/facebook/presto facebook 3天前开源了他们的 分布式大数据DB Distributed SQL query engine for big ...
- MSDN使用
比如我想查一下fopen这个函数怎么用,在索引里搜索一下fopen,很容易找到了. 但是如果我想横向扩展一下,查看一些与fopen相关的函数,应该怎么找呢? 很简单,点击定位: 你就能把fopen定位 ...