FLUME NG的基本架构
Flume简介
Flume 是一个cloudera提供的 高可用高可靠,分布式的海量日志收集聚合传输系统。原名是 Flume OG (original generation),但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94.0 中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation,改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume)。
FLUME NG
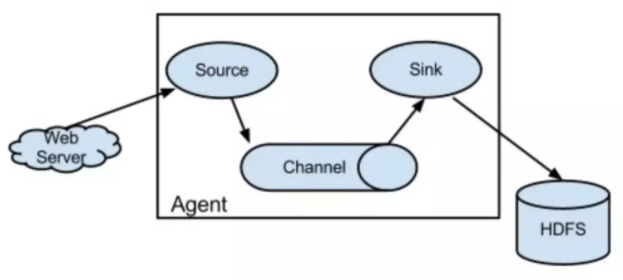
1、NG 只有一种角色的节点:代理节点(agent)。
2、agent 节点的组成也发生了变化。Flume NG 的 agent 由 source、sink、Channel 组成。
flume ng 节点组成图:
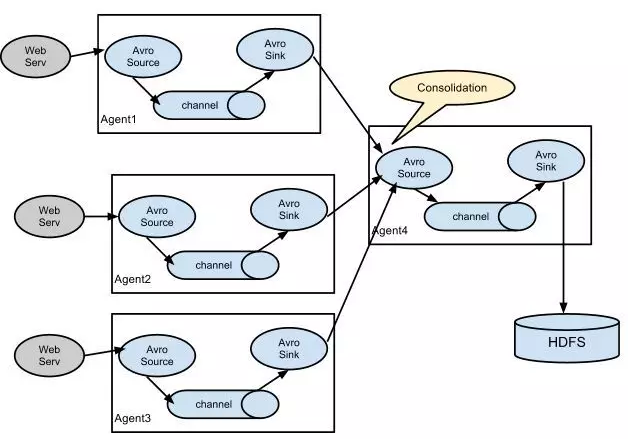
多 Agent 并联下的架构图:
Flume 的特性
flume 支持在日志系统中定制各类数据发送方,用于收集数据;同时支持对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
flume 的数据流由事件(Event)贯穿始终。事件是 Flume 的基本数据单位,它携带日志数据并且携带有头信息,这些 Event 由 Agent 外部的 Source 生成,当 Source 捕获事件后会进行特定的格式化,然后 Source 会把事件推入(单个或多个) Channel 中。可以把 Channel 看作是一个缓冲区,它将保存事件直到 Sink 处理完该事件。
Sink 负责持久化日志或者把事件推向另一个 Source。
Flume 具备高可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:
1、end-to-end:收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。
2、Store on failure:这也是scribe采用的策略,当数据接收方crash崩溃时,将数据写到本地,待恢复后,继续发送。
3、Best effort:数据发送到接收方后,不会进行确认。
Flume 架构组成和核心概念
# client: 生产数据的地方,运行在一个独立的线程。
# event: 生产的数据,可以是日志记录、 avro 对象等,如果是文本文件通常是一行记录。
# agent: flume 核心组件,flume 以 Agent 为最小的独立运行单位。一个 agent 就是一个 jvm, agent 又是由 source, channel, sink 等构建而成。
agent 由 source, channel, sink 等构建而成:
3.1 Source:从 Client 收集数据,传递给 Channel
不同的 source,可以接受不同的数据格式,比如监视外部源–目录池(spooling directory)数据源,可以监控指定文件夹中的新文件变化,如果目录中有文件产生,就会立刻读取其内容。source 组件可以处理各种格式的日志数据,eg:avro Sources、thrift Sources、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义。
Avro Source:支持Avro协议(实际上是Avro RPC),内置支持|
Thrift Source:支持Thrift协议,内置支持
Exec Source:基于Unix的command在标准输出上生产数据
JMS Source:从JMS系统(消息、主题)中读取数据
Spooling Directory Source:监控指定目录内数据变更
Twitter 1% firehose Source:通过API持续下载Twitter数据,试验性质
Netcat Source:监控某个端口,将流经端口的每一个文本行数据作为Event输入
Sequence Generator Source:序列生成器数据源,生产序列数据
Syslog Sources:读取syslog数据,产生Event,支持UDP和TCP两种协议
HTTP Source:基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式
Legacy Sources:兼容老的Flume OG中Source(0.9.x版本)
详细参考官网:http://flume.apache.org/FlumeUserGuide.html#flume-sources
3.2、Channel:连接 sources 和 sinks
有点像一个队列,是一个存储池,接收 source 的输出,直到有 sink 消费掉 channel 中的数据,channel 中的数据直到进入下一个 channel 或者进入 sink 才会被删除,当 sink 写入失败后,可以自动重启,不会造成数据丢失。临时存放的数据可以存放在memory Channel、jdbc Channel、file Channel、自定义。
Memory Channel:Event数据存储在内存中
JDBC Channel:Event数据存储在持久化存储中,当前Flume Channel内置支持Derby
File Channel:Event数据存储在磁盘文件中
Spillable Memory Channel:Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件
Pseudo Transaction Channel:测试用途
Custom Channel:自定义Channel实现
详细参考官网:http://flume.apache.org/FlumeUserGuide.html#flume-channels
3.3、Sink:从Channel收集数据,运行在一个独立线程
用于把数据发送到目的地的组件目的地包括 hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义。
详参考官网:http://flume.apache.org/FlumeUserGuide.html#flume-sinks
flume可以支持
1、多级 flume的 agent,(即多个 flume 可以连成串,上一个 flume 可以把数据写到下一个 flume 上)
2、支持扇入(fan-in):source 可以接受多个输入
3、扇出(fan-out):sink 可以输出到多个目的地
3.4、其他几个组件
Interceptor:作用于Source,按照预设的顺序在必要地方装饰和过滤events。
Channel Selector:允许Source基于预设的标准,从所有Channel中,选择一个或多个Channel
Sink Processor:多个Sink可以构成一个Sink Group。Sink Processor可以通过组中所有Sink实现负载均衡;也可以在一个Sink失败时转移到另一个。
FLUME NG的基本架构的更多相关文章
- 【转】Flume(NG)架构设计要点及配置实践
Flume(NG)架构设计要点及配置实践 Flume NG是一个分布式.可靠.可用的系统,它能够将不同数据源的海量日志数据进行高效收集.聚合.移动,最后存储到一个中心化数据存储系统中.由原来的Fl ...
- Flume NG基本架构与Flume NG核心概念
导读 Flume NG是一个分布式.可靠.可用的系统,它能够将不同数据源的海量日志数据进行高效收集.聚合.移动,最后存储到一个中心化数据存储系统中. 由原来的Flume OG到现在的Flume NG, ...
- 高可用Hadoop平台-Flume NG实战图解篇
1.概述 今天补充一篇关于Flume的博客,前面在讲解高可用的Hadoop平台的时候遗漏了这篇,本篇博客为大家讲述以下内容: Flume NG简述 单点Flume NG搭建.运行 高可用Flume N ...
- Flume应用场景及架构原理
Flume概念 Flume是一个分布式.可靠.和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力. ...
- Flume NG简介及配置
Flume下载地址:http://apache.fayea.com/flume/ 常用的分布式日志收集系统: Apache Flume. Facebook Scribe. Apache Chukwa ...
- Flume NG 简介及配置实战
Flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用.Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 clo ...
- 【Flume NG用户指南】(1)设置
作者:周邦涛(Timen) Email:zhoubangtao@gmail.com 转载请注明出处: http://blog.csdn.net/zhoubangtao/article/details ...
- flume用场景及架构原理
Flume是什么 1.flume可以将采集到的数据存储到HDFS上,也可以放在Hbase上. 2.flume就是一个中间插件,他的作用就是屏蔽数据源和数据存储系统的差异.可以在不同的数据源采集数据,因 ...
- 分布式实时日志系统(二) 环境搭建之 flume 集群搭建/flume ng资料
最近公司业务数据量越来越大,以前的基于消息队列的日志系统越来越难以满足目前的业务量,表现为消息积压,日志延迟,日志存储日期过短,所以,我们开始着手要重新设计这块,业界已经有了比较成熟的流程,即基于流式 ...
随机推荐
- 轻松玩转windows之redis实战
Redis是一个常用的键值对数据库.本篇分享一下如何轻松在睿江云上实现基于windows的redis开发环境. 1. 登录睿江云 点击右上角登录框 进入登录页面,输入账号密码登录 进入控制台, ...
- CodeForces - 5C(思维+括号匹配)
题意 https://vjudge.net/problem/CodeForces-5C 给出一个括号序列,求出最长合法子串和它的数量. 合法的定义:这个序列中左右括号匹配. 思路 这个题和普通的括号匹 ...
- PHP 是如何做垃圾回收的
PHP 是如何做垃圾回收的 包含 php 5 与 php7 的变量实现和垃圾回收的对比 变量的实现 PHP 的变量是弱类型的,可以表示整数.浮点数.字符串等类型.PHP 的变量是使用结构体 zval ...
- 剑指offer笔记面试题5----替换空格
题目:请实现一个函数,把字符串中的每个空格替换成"20%".例如,输入"We are happy."则输出"We%20are%20happy.&quo ...
- Axure制作dialog效果的动作步骤
1.在Axure中添加一个弹框按钮 2.将动态面版拖动到界面中 3.双击动态面版,双击state 4.拖入一块图片占位符进来 5.设置图片 6.回到上一个界面设置动态面版的大小,使其 ...
- Effect:Mobile ocd
Satisfy the following two Keep your phone at all times Check your phone even if there's no news Alwa ...
- Java8特性Lambda表达式
Lambda 表达式 简介: Lambda 表达式,也可称为闭包,它是推动 Java 8 发布的最重要新特性. Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中). (parame ...
- centos7.6 jumpserver 堡垒机 重启启动顺序
cd /sdata/usr/local python3. -m venv py3 source /sdata/usr/local/py3/bin/activate cd /sdata/usr/loca ...
- 【cf961G】G. Partitions(组合意义+第二类斯特林数)
传送门 题意: 给出\(n\)个元素,每个元素有价值\(w_i\).现在要对这\(n\)个元素进行划分,共划分为\(k\)组.每一组的价值为\(|S|\sum_{i=0}^{|S|}w_i\). 最后 ...
- ReactNative: 使用导航栏组件-NavigatorIOS组件和Navigator组件
一.简言 在软件开发中,不论是Web还是App,它们的应用程序都是由很多的功能视图组成的.对于这些组合的视图,如何实现页面间平滑地过渡,应用都有统一的一套跳转机制,这个功能就是路由或者叫导航.应用程序 ...