scrapy项目部署
什么是scrapyd
Scrapyd是部署和运行Scrapy.spider的应用程序。它使您能够使用JSON API部署(上传)您的项目并控制其spider。
特点:
- 可以避免爬虫源码被看到。
- 有版本控制。
- 可以远程启动、停止、删除
scrapyd官方文档:http://scrapyd.readthedocs.io/en/stable/overview.html
安装scrapyd
- 安装scrapyd
- 主要有两种安装方式:
- pip install scrapyd (安装的版本可能不是最新版本)
- 从 https://github.com/scrapy/scrapyd 中下载源码, 运行python setup.py install 命令进行安装。
2.安装 scrapyd-deploy
- 主要有两种安装方式:
- pip install scrapyd-client(安装的版本可能不是最新版本)
- 从 http://github.com/scrapy/scrapyd-client 中下源码, 运行python setup.py install 命令进行安装。
scrapyd的简单使用
1.运行scrapyd
运行命令:scrapyd

然后打开浏览器,输入ip加端口:127.0.0.1:6800(或localhost:6800)
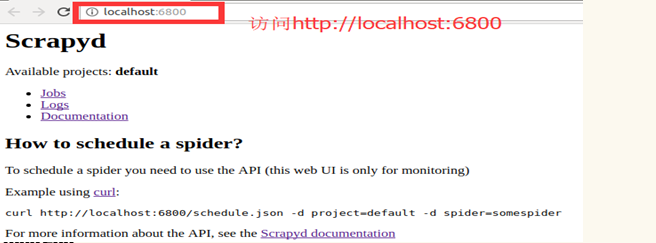
2.发布项目到scrapyd
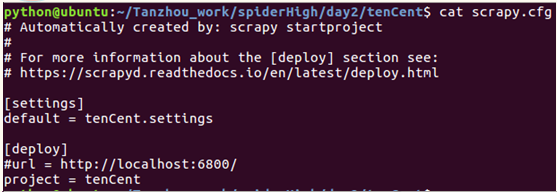
来到待发布项目的文件夹下,发布前需要修改一下配置文件,打开scrapy.cfg文件;
- 首先去掉url前面的注释符号,url是scrapyd服务器的网址
- 然后project=tenCent为项目名称,可以随意起名
- 修改[deploy]为[deploy:100],表示把爬虫发布到名为100的爬虫服务器上,一般在需要同时发布爬虫到多个目标服务器时使用
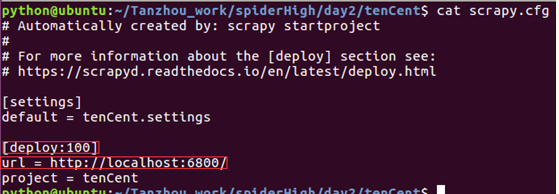
最后,打开一个新的终端,运行命令:
scrapyd-deploy <target> -p <project> --version <version>
参数解释:
Target:deploy后面的名称。可以为空
Project:自行定义名称,跟爬虫的工程名字无关。
Version:自定义版本号,不写的话默认为当前时间戳。

刷新浏览器页面:
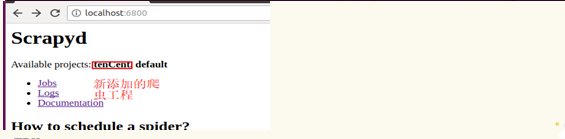
3.创建运行爬虫任务
使用命令:
curl http://localhost:6800/schedule.json -d project=myproject -d spider=spider_name
然后点击浏览器界面的Jobs
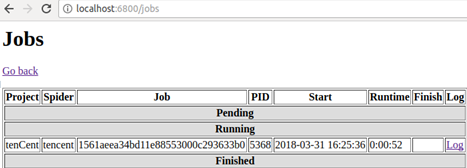
就可以得到该爬虫的相关运行信息。这里的schedule.json只是scrapyd里的一个API接口,scrapyd还提供其他API接口,具体如下。
scrapyd的控制API
所有的API都是通过http协议发送的请求,目前总共10个api
规则是:http://ip:port/api_command.json,有GET和POST两种请求
1) daemonstatus.json
检查服务状态
curl http://localhost:6800/daemonstatus.json
结果示例:

2) addversion.json
增加项目到服务器,如果项目已经存在,则增加一个新的版本
POST请求:
- project (string, required) –项目名
- version (string, required) –项目版本,不填写则是当前时间戳
- egg (file, required) –当前项目的egg文件
curl http://localhost:6800/addversion.json -F project=myproject -F version=r23 -F egg=@myproject.egg
结果示例:

3) schedule.json
启动一个爬虫项目
POST请求:
- project (string, required) –项目名
- spider (string, required) –爬虫名,spider类中指定的name
- setting (string, optional) –自定义爬虫settings
- jobid (string, optional) –jobid,之前启动过的spider,会有一个id
- _version (string, optional) –版本号,之前部署的时候的version,只能使用int数据类型,没指定,默认启动最新版本
- 其他额外的参数都会放入到spider的参数中
curl http://localhost:6800/schedule.json -d project=myproject -d spider=somespider
结果示例:

4) cancel.json
取消一个 spdier的运行
如果 spider是运行状态,则停止其运行
如果 spider是挂起状态,则删除spider
POST请求:
- project (string, required) –项目名
- job (string, required) -jobid
curl http://localhost:6800/cancel.json -d project=myproject -d job=6487ec79947edab326d6db28a2d86511e8247444
结果示例:

5) listprojects.json
获取当前已上传的项目的列表
GET请求:
curl http://localhost:6800/listprojects.json
结果示例:

6) listversions.json
获取指定项目的可用版本
GET请求:
- project (string, required) –项目名
curl http://localhost:6800/listversions.json?project=myproject
结果示例:

7) listspiders.json
获取指定版本的项目中的爬虫列表,如果没有指定版本,则是最新版本
GET请求:
- project (string, required) –项目名
- _version (string, optional) –版本号
$ curl http://localhost:6800/listspiders.json?project=myproject
结果示例:

8) listjobs.json
获取指定项目中所有挂起、运行和运行结束的job
GET请求
- project (string, option) - restrict results to project name
curl http://localhost:6800/listjobs.json?project=myproject | python -m json.tool
结果示例:
{
"status":"ok",
"pending":[
{
"project":"myproject","spider":"spider1",
"id":"78391cc0fcaf11e1b0090800272a6d06"
}
],
"running":[
{
"id":"422e608f9f28cef127b3d5ef93fe9399",
"project":"myproject","spider":"spider2",
"start_time":"2012-09-12 10:14:03.594664"
}
],
"finished":[
{
"id":"2f16646cfcaf11e1b0090800272a6d06",
"project":"myproject","spider":"spider3",
"start_time":"2012-09-12 10:14:03.594664",
"end_time":"2012-09-12 10:24:03.594664"
}
]
}
9) delversion.json
删除指定项目的指定版本
POST请求
- project (string, required) - the project name
- version (string, required) - the project version
curl http://localhost:6800/delversion.json -d project=myproject -d version=r99
结果示例:

10) delproject.json
删除指定项目,并且包括所有的版本
POST请求
- project (string, required) - the project name
curl http://localhost:6800/delproject.json -d project=myproject
结果示例:

BUG处理
1、 builtins.KeyError: 'project'
错误信息如下:
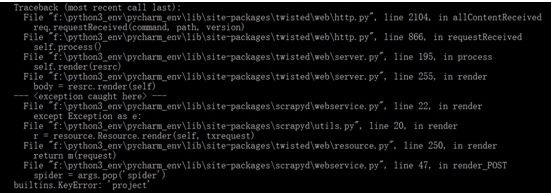
解决:
进行post提交时,需要将参数提交放入到 params或 data中,而不是json
如:requests.post(url, params=params)或requests.post(url, data=params)
2、 TypeError: __init__() missing 1 required positional argument: 'self'
修改 spider,增加:
def __init__(self, **kwargs):
super(DingdianSpider, self).__init__(self, **kwargs)
3、 redis.exceptions.ConnectionError: Error 10061 connecting to localhost:6379
有类似这样的错误,是由于项目中有连接其他服务,譬如这里是redis数据库,需要先启动对应的服务
scrapy项目部署的更多相关文章
- scrapy 项目通过scrapyd部署
年前的时候采用scrapy 爬取了某网站的数据,当时只是通过crawl 来运行了爬虫,现在还想通过持续的爬取数据所以需要把爬虫部署起来,查了下文档可以采用scrapyd来部署scrapy项目,scra ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 五十一 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:https://github.com/scrapy/scrapyd 建议安装 pip3 install s ...
- Python爬虫从入门到放弃(二十一)之 Scrapy分布式部署
按照上一篇文章中我们将代码放到远程主机是通过拷贝或者git的方式,但是如果考虑到我们又多台远程主机的情况,这种方式就比较麻烦,那有没有好用的方法呢?这里其实可以通过scrapyd,下面是这个scrap ...
- 创建第一个Scrapy项目
d:进入D盘 scrapy startproject tutorial建立一个新的Scrapy项目 工程的目录结构: tutorial/ scrapy.cfg # 部署配置文件 tutorial/ # ...
- 爬虫(十八):scrapy分布式部署
scrapy部署神器-scrapyd -->GitHub地址 -->官方文档 一:安装scrapyd 安装:pip3 install scrapyd 这里我在另外一台ubuntu lin ...
- Python之 爬虫(二十三)Scrapy分布式部署
按照上一篇文章中我们将代码放到远程主机是通过拷贝或者git的方式,但是如果考虑到我们又多台远程主机的情况,这种方式就比较麻烦,那有没有好用的方法呢?这里其实可以通过scrapyd,下面是这个scrap ...
- scrapyd+gerapy的项目部署
scrapyd+gerapy的项目部署: 简单学习,后续跟进完善 声明: 1)仅作为个人学习,如有冒犯,告知速删! 2)不想误导,如有错误,不吝指教! 环境配置: scrapyd下载: pip ins ...
- jsp项目部署
每新建一个项目都要发布到服务器,也就是项目部署,在tomcat中的 tomcat\Tomcat 6.0\webapps 路径下就会新建你的项目文件夹 webapps是tomcat的默认访问路径,很 ...
随机推荐
- fenby C语言 P29
野指针 malloc()分配内存: free()释放内存: p=(char*)malloc(100): #include <stdio.h>#include <stdlib.h> ...
- spring整合mybatisplus2.x详解
一丶Mp的配置文件 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="htt ...
- PHP 精典面试题(附答案)
1.输出Mozilla/4.0(compatible;MISIE5.01;Window NT 5.0)是,可能输出的语句是? A:$_SERVER['HTTP_USER_AGENT_TYPE']; B ...
- Android开发中常用的设计模式
首先需要说明的是,这篇博文灵感来自于 http://www.cnblogs.com/qianxudetianxia/archive/2011/07/29/2121547.html ,在这里,博主已经很 ...
- m99 然而并没有想出来标题!
这是放假回来的第一次考试,如同往常一样,我每逢放假回来第一次考试就会废掉,这次也不例外 这次不想粘成绩,因为实在是rp没了! 之前的几次都是别人在CE等等被lemon砍分,而我被lemon多测分. 但 ...
- access,trunk,hybrid端口分析
1.access 接收:当数据没有tag时打上pvidtag进入,若有则看是否与pvid相等,相等则接收,不想等则丢弃. 转发:看tag是否等于pvid,若等则去tag发送,否则不处理. 2.trun ...
- pxe批量部署脚本
#!/bin/bash #检查环境 setenforce 0 sed -i 's/=enforce/=disabled/g' /etc/selinux/config systemctl restart ...
- len、is、==、可变于不可变类型
a="asdfghjkl;'iuygb" b="小米" c=['a','b','c'] d= {'name':1,'age':24} # len统计字符或元素的 ...
- MySql: AUTO_INCREMENT
首先要在Column使用AUTO_INCREMENT (每张表只有一个列可以AUTO_INCREMENT): 以下示例取自MySql官网(http://dev.mysql.com/doc/refman ...
- MyBatis批量更新动态sql
<update id="updateDataKetState"> update ${tablespace}.IDEA_DATAKEY_STATE <trim pr ...