人工智能大语言模型起源篇,低秩微调(LoRA)

上一篇: 《规模法则(Scaling Law)与参数效率的提高》
序言:您在找工作时会不会经常听到LoRA微调,这项技术的来源就是这里了。
(12)Hu、Shen、Wallis、Allen-Zhu、Li、L Wang、S Wang 和 Chen 于2021年发表的《LoRA: Low-Rank Adaptation of Large Language Models》,https://arxiv.org/abs/2106.09685
现代的大型语言模型在大数据集上进行预训练后,展现了突现能力,并且在多种任务中表现优异,包括语言翻译、总结、编程和问答。然而,如果我们希望提升变换器在特定领域数据和专业任务上的能力,微调变换器是非常值得的。
低秩适配(LoRA)是微调大型语言模型的一种非常有影响力的方法,它具有参数高效的特点。虽然还有其他一些参数高效的微调方法(见下文的综述),但LoRA特别值得一提,因为它既优雅又非常通用,可以应用于其他类型的模型。
虽然预训练模型的权重在预训练任务上是全秩的,但LoRA的作者指出,当预训练的大型语言模型适配到新任务时,它们具有低“内在维度”。因此,LoRA的核心思想是将权重变化(ΔW)分解成低秩表示,这样可以更高效地使用参数。

LoRA 的示例及其性能来自 https://arxiv.org/abs/2106.09685。
(13)Lialin、Deshpande 和 Rumshisky 于2022年发表的《Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning》,https://arxiv.org/abs/2303.15647
现代的大型语言模型在大数据集上进行预训练后,展现了突现能力,并且在多种任务中表现优异,包括语言翻译、总结、编程和问答。然而,如果我们希望提升变换器在特定领域数据和专业任务上的能力,微调变换器是非常值得的。本文综述了40多篇关于参数高效微调方法的论文(包括前缀调优、适配器、低秩适配等流行技术),旨在使微调过程(变得)更加高效,尤其是在计算上。
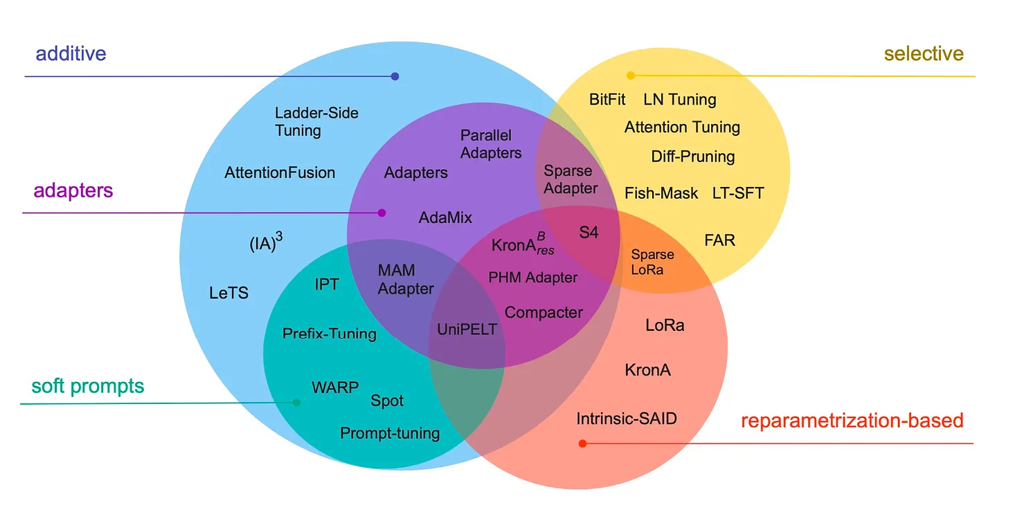
来源:https://arxiv.org/abs/2303.15647
人工智能大语言模型起源篇,低秩微调(LoRA)的更多相关文章
- 本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPT
OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿.130亿.330亿 ...
- DyLoRA:使用动态无搜索低秩适应的预训练模型的参数有效微调
又一个针对LoRA的改进方法: DyLoRA: Parameter-Efficient Tuning of Pretrained Models using Dynamic Search-Free Lo ...
- 使用 LoRA 和 Hugging Face 高效训练大语言模型
在本文中,我们将展示如何使用 大语言模型低秩适配 (Low-Rank Adaptation of Large Language Models,LoRA) 技术在单 GPU 上微调 110 亿参数的 F ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
- 人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载
人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载 ImageNet挑战赛中超越人类的计算机视觉系统微软亚洲研究院视觉计算组基于深度卷积神经网络(CNN)的计 ...
- zz【清华NLP】图神经网络GNN论文分门别类,16大应用200+篇论文最新推荐
[清华NLP]图神经网络GNN论文分门别类,16大应用200+篇论文最新推荐 图神经网络研究成为当前深度学习领域的热点.最近,清华大学NLP课题组Jie Zhou, Ganqu Cui, Zhengy ...
- 大数据工具篇之Hive与MySQL整合完整教程
大数据工具篇之Hive与MySQL整合完整教程 一.引言 Hive元数据存储可以放到RDBMS数据库中,本文以Hive与MySQL数据库的整合为目标,详细说明Hive与MySQL的整合方法. 二.安装 ...
- 大数据工具篇之Hive与HBase整合完整教程
大数据工具篇之Hive与HBase整合完整教程 一.引言 最近的一次培训,用户特意提到Hadoop环境下HDFS中存储的文件如何才能导入到HBase,关于这部分基于HBase Java API的写入方 ...
- 吴恩达机器学习笔记59-向量化:低秩矩阵分解与均值归一化(Vectorization: Low Rank Matrix Factorization & Mean Normalization)
一.向量化:低秩矩阵分解 之前我们介绍了协同过滤算法,本节介绍该算法的向量化实现,以及说说有关该算法可以做的其他事情. 举例:1.当给出一件产品时,你能否找到与之相关的其它产品.2.一位用户最近看上一 ...
- 【RS】Local Low-Rank Matrix Approximation - LLORMA :局部低秩矩阵近似
[论文标题]Local Low-Rank Matrix Approximation (icml_2013 ) [论文作者]Joonseok Lee,Seungyeon Kim,Guy Lebanon ...
随机推荐
- 深入理解ConcurrentHashMap
HashMap为什么线程不安全 put的不安全 由于多线程对HashMap进行put操作,调用了HashMap的putVal(),具体原因: 假设两个线程A.B都在进行put操作,并且hash函数计算 ...
- 手搓大模型Task03:手搓一个最小的 Agent 系统
前言 训练一个大模型是一件高投入低回报的事情,况且训练的事情是由大的巨头公司来做的事情:通常我们是在已有的大模型基础之上做微调或Agent等:大模型的能力是毋庸置疑的,但大模型在一些实时的问题上, ...
- 【赵渝强老师】Oracle数据库的内存结构
首先,我们通过一张图片来了解一下Oracle数据库的内存结构,如下: 每个数据库实例有两个关联的内存结构-系统全局区(SGA),程序全局区(PGA). 系统全局(SGA):一组共享的内存结构(称为SG ...
- 国庆快乐!附ssh实战
小伙伴们,有一段时间没更新了,目前在中科院软件所实习,在这里我祝大家国庆快乐! 今天这一期带来ssh命令的实战教程,ssh在工作当中遇到的非常多,因为总是需要登服务器,而且玩法也有不少,这是我常用的几 ...
- 墨天轮最受DBA欢迎的数据库技术文档-容灾备份篇
在大家的支持与认可下,墨天轮编辑部继续为大家整理出了[墨天轮最受欢迎的技术文档]系列第二篇--容灾备份篇,希望能够帮助到大家. 作为一名数据库管理员,最怕数据库中心突然失去服务能力.影响业务,而不论是 ...
- 00 通过 Pytorch 实现 Transformer 框架完整代码
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看 配套 github 链接:https:// ...
- go~wasm插件的开发
Go和TinyGo是两种不同的Go语言编译器,它们之间有以下几点区别: 目标平台: Go:Go语言编译器主要面向通用计算机平台,如Windows.Linux.macOS等. TinyGo:TinyGo ...
- kotlin协程——>select 表达式(实验性的)
select 表达式(实验性的) select 表达式可以同时等待多个挂起函数,并 选择 第⼀个可⽤的. 在通道中 select 我们现在有两个字符串⽣产者:fizz 和 buzz .其中 fizz ...
- npm install报错 SyntaxError: Unexpected end of JSON input while parsing near '...=GmVg\r\n-----END PGP'
解决方法: npm cache clean --force 然后重新执行:npm install即可
- 每日学学Java开发规范,常量定义(附阿里巴巴Java开发手册(终极版))
前言 每次去不同的公司,码不同的代码,适应不同的规范,经常被老大教育规范问题,我都有点走火入魔的感觉,还是要去看看阿里巴巴Java开发规范,从中熟悉一下,纠正自己,码出高效,码出质量. 想细看的可以去 ...