第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
当前环境python3.5 ,windows10系统
Linux系统安装
在线安装,会自动安装scrapy模块以及相关依赖模块
pip install Scrapy
手动源码安装,比较麻烦要自己手动安装scrapy模块以及依赖模块
安装以下模块
1、lxml-3.8.0.tar.gz (XML处理库)
2、Twisted-17.5.0.tar.bz2 (用Python编写的异步网络框架)
3、Scrapy-1.4.0.tar.gz (高级web爬行和web抓取框架)
4、pyOpenSSL-17.2.0.tar.gz (OpenSSL库)
5、queuelib-1.4.2.tar.gz (Queuelib是用于Python的持久(基于磁盘的)队列的集合)
6、w3lib-1.17.0.tar.gz (与web相关的函数的Python库)
7、cryptography-2.0.tar.gz (密码学是一种包)
8、pyasn1-0.2.3.tar.gz (ASN类型和编解码器)
9、pyasn1-modules-0.0.9.tar.gz (ASN的集合。基于协议模块)
10、cffi-1.10.0.tar.gz (用于Python调用C代码的外部函数接口)
11、asn1crypto-0.22.0.tar.gz (快速的ASN一个解析器和序列化器)
12、idna-2.5.tar.gz (应用程序中的国际化域名(IDNA))
13、pycparser-2.18.tar.gz (C解析器在Python中)
windows系统安装
windows安装,首先要安装pywin32,根据自己的系统来安装32位还是64位
pywin32-221.win32-py3.5.exe
pywin32-221.win-amd64-py3.5.exe
在线安装
pip install Scrapy
手动源码安装,比较麻烦要自己手动安装scrapy模块以及依赖模块
安装以下模块
1、lxml-3.8.0.tar.gz (XML处理库)
2、Twisted-17.5.0.tar.bz2 (用Python编写的异步网络框架)
3、Scrapy-1.4.0.tar.gz (高级web爬行和web抓取框架)
4、pyOpenSSL-17.2.0.tar.gz (OpenSSL库)
5、queuelib-1.4.2.tar.gz (Queuelib是用于Python的持久(基于磁盘的)队列的集合)
6、w3lib-1.17.0.tar.gz (与web相关的函数的Python库)
7、cryptography-2.0.tar.gz (密码学是一种包)
8、pyasn1-0.2.3.tar.gz (ASN类型和编解码器)
9、pyasn1-modules-0.0.9.tar.gz (ASN的集合。基于协议模块)
10、cffi-1.10.0.tar.gz (用于Python调用C代码的外部函数接口)
11、asn1crypto-0.22.0.tar.gz (快速的ASN一个解析器和序列化器)
12、idna-2.5.tar.gz (应用程序中的国际化域名(IDNA))
13、pycparser-2.18.tar.gz (C解析器在Python中)
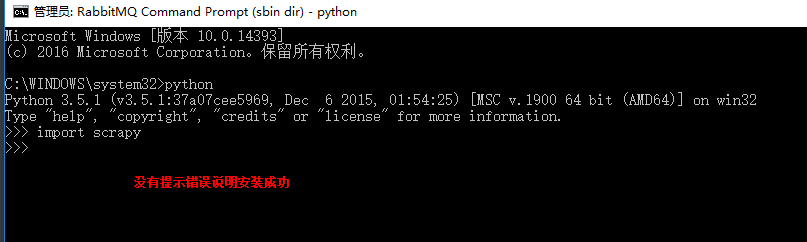
测试是否安装成功
在cmd终端,运行python
然后运行:import scrapy ,没有提示错误说明安装成功
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装的更多相关文章
- 第三百二十二节,web爬虫,requests请求
第三百二十二节,web爬虫,requests请求 requests请求,就是用yhthon的requests模块模拟浏览器请求,返回html源码 模拟浏览器请求有两种,一种是不需要用户登录或者验证的请 ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 第三百八十三节,Django+Xadmin打造上线标准的在线教育平台—第三方模块django-simple-captcha验证码
第三百八十三节,Django+Xadmin打造上线标准的在线教育平台—第三方模块django-simple-captcha验证码 下载地址:https://github.com/mbi/django- ...
随机推荐
- [保存]——pycharm5专业版激活方法
- python(50):python 向上取整 ceil 向下取整 floor 四舍五入 round
取整:ceil 向下取整:floor 四舍五入:round 使用如下:
- 【Kryo】简单地使用Kryo
公司用Kryo,先接触下,简单记录下. 引入包 <dependencies> <dependency> <groupId>com.esotericsoftware& ...
- 读取本地已有的.db数据库
public class MyDB extends SQLiteOpenHelper { // 数据库的缺省路径 private static String DB_PATH ; private sta ...
- 漫游Kafka之过期数据清理【转】
转自:http://blog.csdn.net/honglei915/article/details/49683065 Kafka将数据持久化到了硬盘上,允许你配置一定的策略对数据清理,清理的策略有两 ...
- css样式实现左边的固定宽度和高度的图片或者div跟随右边高度不固定的文字或者div垂直居中(文字高度超过图片,图片跟随文字居中,反之文字跟随图片居中非table实现)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Asp.net页面中调用soapheader进行验证的操作步骤
Asp.net页面中调用以SOAP头作验证的web services操作步骤 第一步:用来作SOAP验证的类必须从SoapHeader类派生,类中Public的属性将出现在自动产生XML节点中,即: ...
- 自定义NSOperation下载图片
自定义NSOperation的话,只是需要将要下载图片的操作下载它的main方法里面,考虑到,图片下载完毕,需要回传到控制器里,这里可以采用block,也可以采用代理的方式实现,我采用的是代理的方式实 ...
- linux笔记——一些命令工具
ntpdate 时间同步 netstat aux网络状态 htpasswd du -h 文件大小 df 文件信息 fdisk 磁盘分区 查找删除 rm `ls |grep ` ls |grep |xa ...
- Springmvc 定时器的实现
有时候会需要项目中,定时去执行一些东西,这个时候就需要用到定时器了.比较简单, 当你springmvc环境搭建成功的时候. 本文转载自:https://www.cnblogs.com/wqj-blog ...