爬虫多次爬取时候cookie的存储用于登入
一.用requests模块自动保存(保存缓存中)
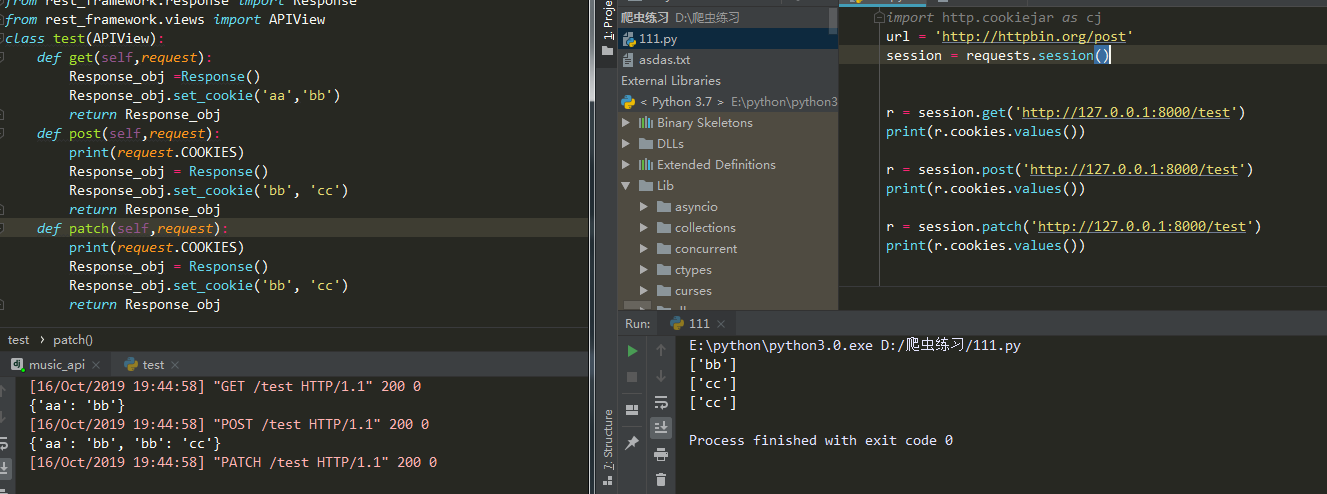
构建一个session对象session = requests.session()
用构建的session代替requests进行访问他就会自动存啦
import requests
session = requests.session()
r = session.get(......) #他会存返回的cookies不会存发送的cookies
r = session.post(......) #在请求同一url他会把存的cookies发送过去
注意点
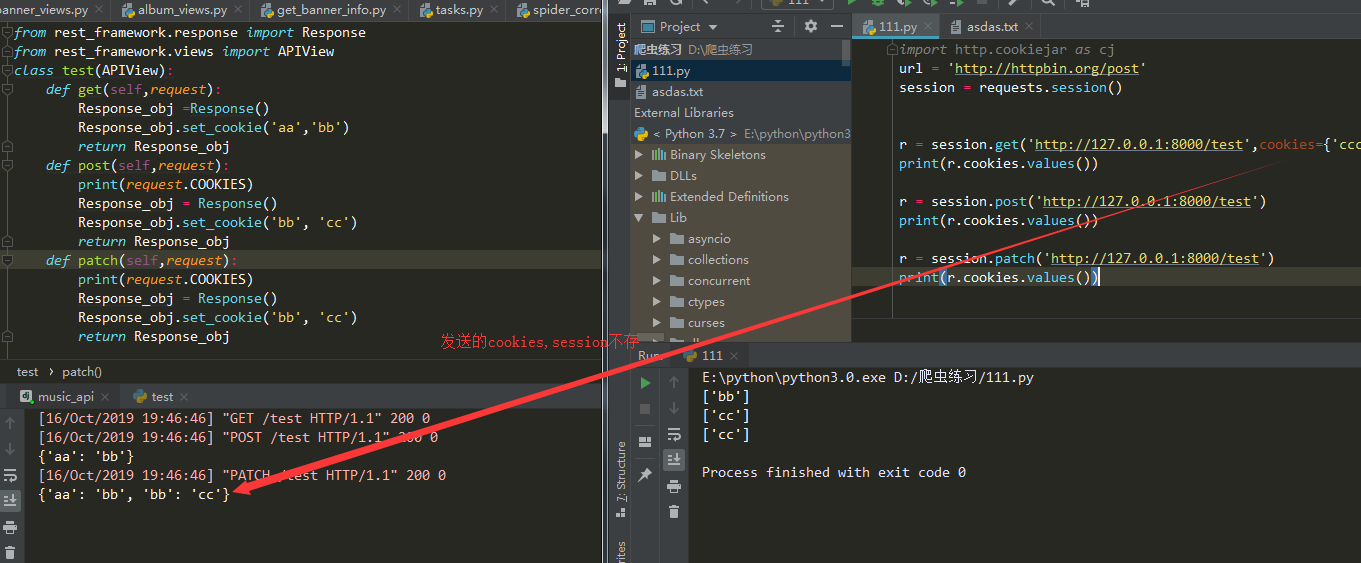
- 只存响应的cookie
- 不存发送请求时候带的cookie
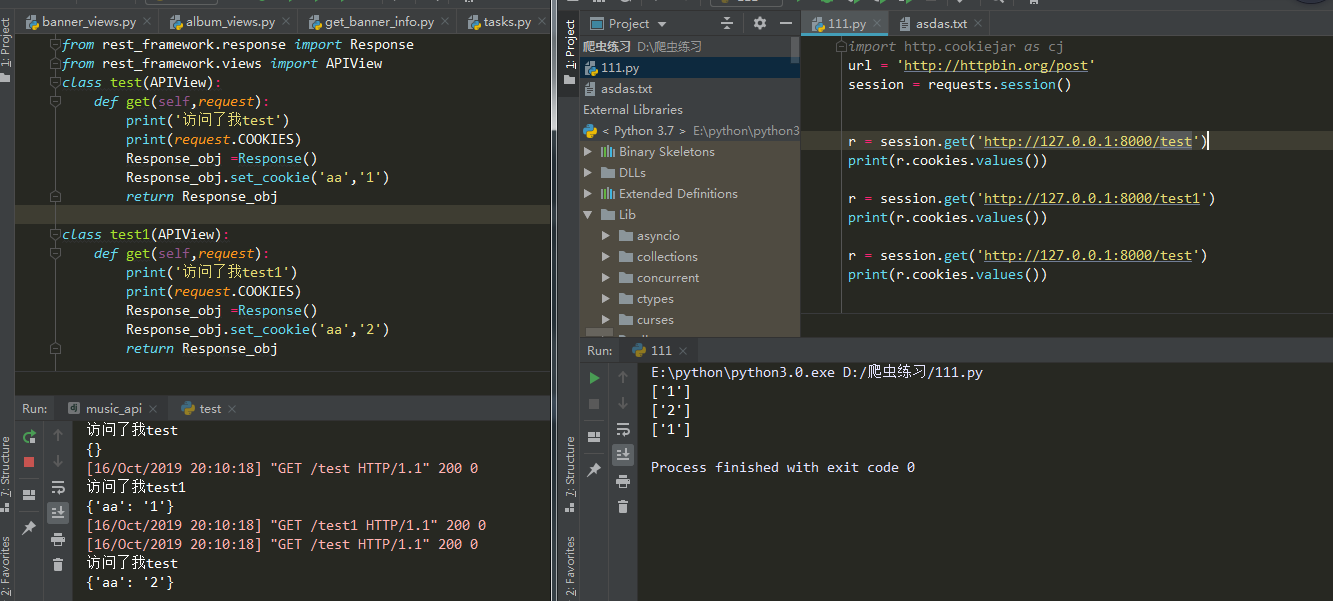
- 不同url没有影响
- cookie名字一样会覆盖掉
原因自己看下面自己看哈,有问题可以私聊我

二.将cookie存本地
1.基于session(推荐使用代码少哈哈)
import requests
from http import cookiejar
session =requests.session()
session.cookies = cookiejar.LWPCookieJar() #MozillaCookieJar或LWPCookieJar。
session.cookies.save(filename='1.txt') //存cookie
session.cookies.load(filename='1.txt') //读cookie
2.普通请求把cookies存本地
这个参照https://www.cnblogs.com/fu-yong/p/9032902.html
第一次访问
from urllib import request,parse
from http import cookiejar
# 创建filecookiejar实例对象
# 它需要一个参数,既cookie保存的位置
filename = 'cookie.txt'
cookie = cookiejar.FileCookieJar(filename)
# 根据创建的cookie生成cookie的管理器
cookie_handle = request.HTTPCookieProcessor(cookie)
# 创建http请求管理器
http_handle = request.HTTPHandler()
# 创建https管理器
https_handle = request.HTTPSHandler()
# 创建求求管理器,将上面3个管理器作为参数属性
# 有了opener,就可以替代urlopen来获取请求了
opener = request.build_opener(cookie_handle,http_handle,https_handle)
# 登录url,需要从登录form的action属性中获取
url = 'xxxxxxxxxxxxxx'
# 登录所需要的数据,数据为字典形式,
# 此键值需要从form扁担中对应的input的name属性中获取
data = {
'email':'xxxx',
'password':'xxxxx'
}
# 将数据解析成urlencode格式
data = parse.urlencode(data)
req = request.Request(url,data=data)
# 正常是用request.urlopen(),这里用opener.open()发起请求
response = opener.open(req)
# 保存cookie文件
cookie.save()
第二次访问
from urllib import request,parse
from http import cookiejar
# 创建cookiejar实例对象
cookie = cookiejar.FileCookieJar()
# 读取已经保存的cookie文件
# 读取之后,就无需登录,直接访问主页即可
cookie.load('cookie.txt')
# 根据创建的cookie生成cookie的管理器
cookie_handle = request.HTTPCookieProcessor(cookie)
# 创建http请求管理器
http_handle = request.HTTPHandler()
# 创建https管理器
https_handle = request.HTTPSHandler()
# 创建求求管理器,将上面3个管理器作为参数属性
# 有了opener,就可以替代urlopen来获取请求了
opener = request.build_opener(cookie_handle,http_handle,https_handle)
url = 'http://xxxxxx'
res = opener.open(url)
html = res.read().decode()
with open('renren.html','w') as f:
f.write(html)
爬虫多次爬取时候cookie的存储用于登入的更多相关文章
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- 爬虫实战——Scrapy爬取伯乐在线所有文章
Scrapy简单介绍及爬取伯乐在线所有文章 一.简说安装相关环境及依赖包 1.安装Python(2或3都行,我这里用的是3) 2.虚拟环境搭建: 依赖包:virtualenv,virtualenvwr ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
随机推荐
- visual studio 2019 企业版下载
由于visual studio从2017开始就是网络下载安装,所以网速慢的朋友安装上就存在时间感,所以笔者在百度云上提供了visual studio 2019的下载包.需要的朋友自己下载安装.不过,2 ...
- [zhuan]SQLSERVER 数据库性能的基本
SQLSERVER 数据库性能的基本 很久没有写文章了,在系统正式上线之前,DBA一般都要测试一下服务器的性能 比如你有很多的服务器,有些做web服务器,有些做缓存服务器,有些做文件服务器,有些做数据 ...
- Eclipse安装代码反编译插件Enhanced Class Decompiler
在开发过程中,如果想查看引入资源的源代码,可以借助eclipse的插件Enhanced Class Decompiler轻松实现,下面我来讲解一下如何安装使用这个插件. 1.打开Eclipse菜单-& ...
- Flume监控指标项
配置监控 1.修改flume-env.sh export JAVA_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmx ...
- 闭包(python)
1.闭包的理解 我们可以将闭包理解为一种特殊的函数,这种函数由两个函数的嵌套组成,且称之为外函数和内函数,外函数返回值是内函数的引用,此时就构成了闭包. 2. 闭包的格式 下面用伪代码进行闭包格式的描 ...
- PHP 简易网页访问统计
传统的网页访问统计,已经有很多,如 51la.百度统计.站长统计 一般都需要引用JS,在你的网页内嵌入JS,这个操作存在风险,并且不可控. 可以考虑使用 [img src.css src.link h ...
- 创建Observer
观察者 观察者作用就是监听事件, 然后对这个事件做出响应, 或者说任何响应时间的行为都是观察者 1. 在subscribe()方法中创建监听者 创建观察者最直接的方法就是在Observable的sub ...
- word 条件多项式公式对齐
条件多项式公式对齐 觉得有用的话,欢迎一起讨论相互学习~Follow Me 对于使用word编写具有多个多项式的公式时,经常会有所偏移 最不优雅的方式就是使用逗号进行分隔和排版使其公式上下对齐 第二种 ...
- oracle plsql 自定义异常
set serveroutput on DECLARE ; pename emp.ename%type; --自定义异常 no_emp_found exception; begin open cemp ...
- Java8 特性
1.jdk8的特性stream().map() 2.Java8中用Lambda表达式的groupBy合并多个相同属性的对象集合 3.Java8 Stream 语法详解 & 用法实例