新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍
1)定义
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams

2.NC服务安装并运行Spark Streaming
1)在线安装nc命令
yum install -y nc
2)运行Spark Streaming 的WordCount
bin/run-example streaming.NetworkWordCount localhost 9999
3)把文件通过管道作为nc的输入,然后观察spark Streaming计算结果
cat test.txt | nc -lk 9999
文件具体内容
hadoop storm spark
hbase spark flume
spark dajiangtai spark
hdfs mapreduce spark
hive hdfs solr
spark flink storm
hbase storm es
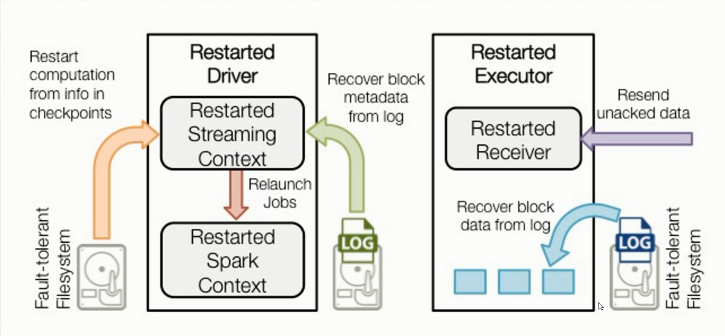
3.Spark Streaming工作原理
1)Spark Streaming数据流处理
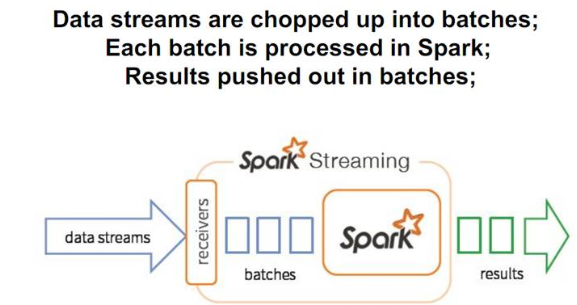
2)接收器工作原理
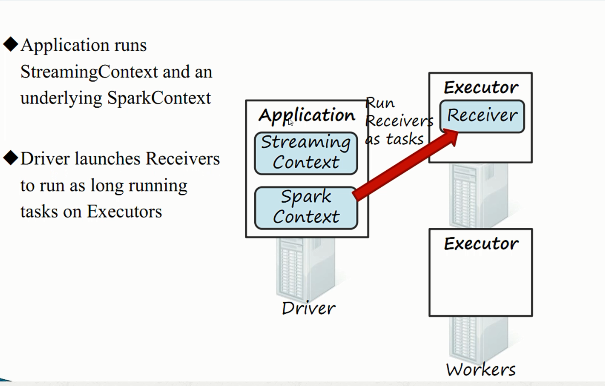
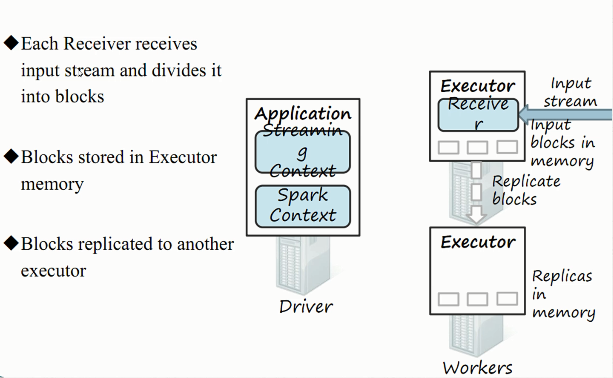
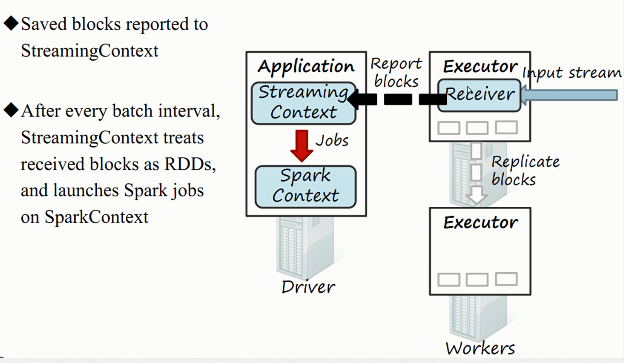
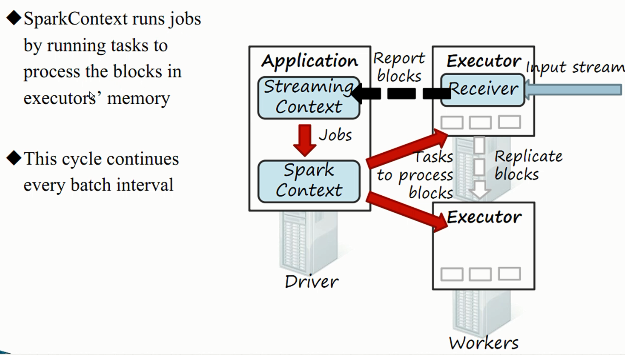
3)综合工作原理

4.Spark Streaming编程模型
1)StreamingContext初始化的两种方式
#第一种
val ssc = new StreamingContext(sc, Seconds(5))
#第二种
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
2)Spark Streaming socket代码
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount ")
System.exit(1)
}
//创建StreamingContext,每秒钟计算一次
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
//监听网络端口,参数一:hostname 参数二:port 参数三:存储级别,创建了lines流
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
//flatMap运算
val words = lines.flatMap(_.split(" "))
//map reduce 计算
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
5.Spark Streaming读取Socket流数据
1)spark-shell运行Streaming程序,要么线程数大于1,要么基于集群。
bin/spark-shell --master local[2]
bin/spark-shell --master spark://bigdata-pro01.kfk.com:7077
2)spark 运行模式

3)Spark Streaming读取Socket流数据
a)编写测试代码,并本地运行
object TestStreaming {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount ")
System.exit(1)
}
val spark=SparkSession.builder().master("local[2]").setAppName("streaming").getOrCreate()
val sc = spark.SparkContext
val ssc = new StreamingContext(sc, Seconds(5))
//监听网络端口,参数一:hostname 参数二:port 参数三:存储级别,创建了lines流
val lines = ssc.socketTextStream("igdata-pro02.kfk.com", 9999, StorageLevel.MEMORY_AND_DISK_SER)
//flatMap运算
val words = lines.flatMap(_.split(" "))
//map reduce 计算
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
b)启动nc服务发送数据
nc -lk 9999
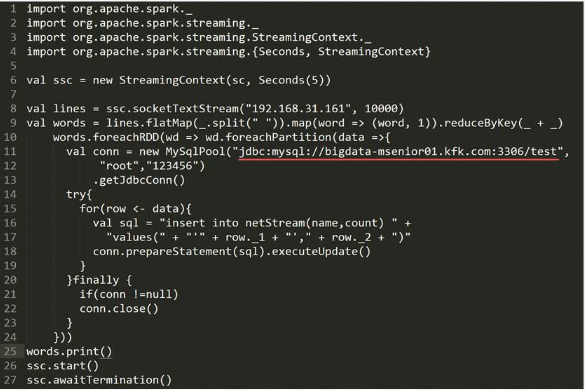
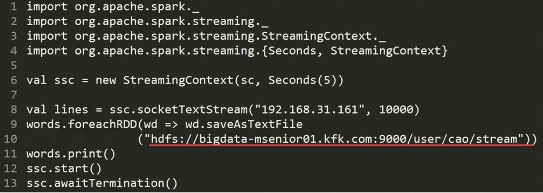
6.Spark Streaming保存数据到外部系统
1)保存到mysql数据库
2)保存到hdfs
7.Spark Streaming与Kafka集成
1)Maven引入相关依赖:spark-streaming-kafka
2)编写测试代码并启动运行
object StreamingKafka8 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[2]")
.appName("streaming").getOrCreate()
val sc =spark.sparkContext;
val ssc = new StreamingContext(sc, Seconds(5))
// Create direct kafka stream with brokers and topics
val topicsSet =Set("weblogs")
val kafkaParams = Map[String, String]("metadata.broker.list" -> "bigdata-pro01.kfk.com:9092")
val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
val lines = kafkaStream.map(x => x._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
3)启动Kafka服务并测试生成数据
bin/kafka-server-start.sh config/server.properties
bin/kafka-console-producer.sh --broker-list bigdata-pro01.kfk.com --topic weblogs
新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析的更多相关文章
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装 下载IDEA并安装,可以百度一下免费文档. 2.IDEA Maven工程创建与配置 1)配置maven 2)新建Project项目 3)选择maven骨架 4)创 ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- 新闻网大数据实时分析可视化系统项目——8、Flume数据采集准备
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
- 新闻网大数据实时分析可视化系统项目——14、Spark2.X环境准备、编译部署及运行
1.Spark概述 Spark 是一个用来实现快速而通用的集群计算的平台. 在速度方面, Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理 ...
随机推荐
- PXE无人值守实现批量化自动安装Linux系统
设想一个场景:假如让你给1000台服务器装系统,你会怎么做?跑去每一台服务器给它安装系统吗?显然不会.. 一.概括 通过网络引导系统的做法可以不必从硬盘.软盘或CD-ROM硬盘,而是完全通过网络来引导 ...
- Java中的基本数据类型语法补充
变量要先赋值后使用 不给变量赋值代表什么 不赋值就使用会怎样 (会报错) 计算并赋值运算符 作用是为了让代码更加简洁.比如 a = a + 10,可以简化为 a+=10 += -= *= /= %= ...
- 纪录片- 睡眠追踪(Chasing sleep) (共6集)
传送门:https://www.bilibili.com/bangumi/play/ep120260/ 小贴士传送门:https://www.bilibili.com/video/av11887055 ...
- Python 爬取 热词并进行分类数据分析-[JSP演示+页面跳转]
日期:2020.02.03 博客期:142 星期一 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Java 8 stream 实战
概述 平时工作用python的机会比较多,习惯了python函数式编程的简洁和优雅.切换到java后,对于数据处理的『冗长代码』还是有点不习惯的.有幸的是,Java8版本后,引入了Lambda表达式和 ...
- 3.ORM框架一对多的关系及使用
一对多就是主键与外键的关系,通过一个用户表,角色表进行举例子 角色表role:有外键,对应的是user表的主键 用户表users: from flask import Flask, render_te ...
- [转]轻松理解AOP思想(面向切面编程)
原文链接 Spring是什么 先说一个Spring是什么吧,大家都是它是一个框架,但框架这个词对新手有点抽象,以致于越解释越模糊,不过它确实是个框架的,但那是从功能的角度来定义的,从本质意义上来讲,S ...
- 十六 OGNL在Struts2环境的入门
一 配置核心过滤器
- Nvidia发布更快、功耗更低的新一代图形加速卡
导读 不出意外的,Nvidia在其举行的Supercomputing 19大会上公布了很多新闻,这些我们将稍后提到.但被忽略的一条或许是其中最有趣的:一张更快.功耗更低的新一代图形加速卡. 多名与会者 ...
- [NOI 2011]NOI 嘉年华
Description 题库链接 给你 \(n\) 个区间,让你选出其中一些分为两组,要求两组区间不能有交集,组内可以有交集.让你最大化两组之间区间个数较小的那一组的选取区间个数.以及对于每个区间 \ ...