转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中。因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程。
一、准备数据
有条件的同学,可以去imagenet的官网http://www.image-net.org/download-images,下载imagenet图片来训练。但是我没有下载,一个原因是注册账号的时候,验证码始终出不来(听说是google网站的验证码,而我是上不了google的)。第二个原因是数据太大了。。。
我去网上找了一些其它的图片来代替,共有500张图片,分为大巴车、恐龙、大象、鲜花和马五个类,每个类100张。需要的同学,可到我的网盘下载:http://pan.baidu.com/s/1nuqlTnN
编号分别以3,4,5,6,7开头,各为一类。我从其中每类选出20张作为测试,其余80张作为训练。因此最终训练图片400张,测试图片100张,共5类。我将图片放在caffe根目录下的data文件夹下面。即训练图片目录:data/re/train/ ,测试图片目录: data/re/test/
二、转换为lmdb格式
具体的转换过程,可参见我的前一篇博文:Caffe学习系列(11):图像数据转换成db(leveldb/lmdb)文件
首先,在examples下面创建一个myfile的文件夹,来用存放配置文件和脚本文件。然后编写一个脚本create_filelist.sh,用来生成train.txt和test.txt清单文件
# sudo mkdir examples/myfile
# sudo vi examples/myfile/create_filelist.sh
编辑此文件,写入如下代码,并保存

#!/usr/bin/env sh
DATA=data/re/
MY=examples/myfile
echo "Create train.txt..."
rm -rf $MY/train.txt
for i in 3 4 5 6 7
do
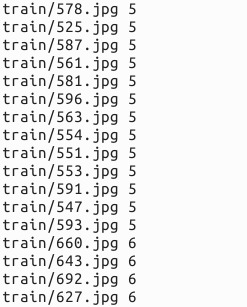
find $DATA/train -name $i*.jpg | cut -d '/' -f4-5 | sed "s/$/ $i/">>$MY/train.txt
done
echo "Create test.txt..."
rm -rf $MY/test.txt
for i in 3 4 5 6 7
do
find $DATA/test -name $i*.jpg | cut -d '/' -f4-5 | sed "s/$/ $i/">>$MY/test.txt
done
echo "All done"
然后,运行此脚本
# sudo sh examples/myfile/create_filelist.sh
成功的话,就会在examples/myfile/ 文件夹下生成train.txt和test.txt两个文本文件,里面就是图片的列表清单。
接着再编写一个脚本文件,调用convert_imageset命令来转换数据格式。
# sudo vi examples/myfile/create_lmdb.sh
插入:
#!/usr/bin/env sh
MY=examples/myfile echo "Create train lmdb.."
rm -rf $MY/img_train_lmdb
build/tools/convert_imageset \
--shuffle \
--resize_height=256 \
--resize_width=256 \
/home/xxx/caffe/data/re/ \
$MY/train.txt \
$MY/img_train_lmdb echo "Create test lmdb.."
rm -rf $MY/img_test_lmdb
build/tools/convert_imageset \
--shuffle \
--resize_width=256 \
--resize_height=256 \
/home/xxx/caffe/data/re/ \
$MY/test.txt \
$MY/img_test_lmdb echo "All Done.."
因为图片大小不一,因此我统一转换成256*256大小。运行成功后,会在 examples/myfile下面生成两个文件夹img_train_lmdb和img_test_lmdb,分别用于保存图片转换后的lmdb文件。
三、计算均值并保存
图片减去均值再训练,会提高训练速度和精度。因此,一般都会有这个操作。
caffe程序提供了一个计算均值的文件compute_image_mean.cpp,我们直接使用就可以了
# sudo build/tools/compute_image_mean examples/myfile/img_train_lmdb examples/myfile/mean.binaryproto
compute_image_mean带两个参数,第一个参数是lmdb训练数据位置,第二个参数设定均值文件的名字及保存路径。
运行成功后,会在 examples/myfile/ 下面生成一个mean.binaryproto的均值文件。
四、创建模型并编写配置文件
模型就用程序自带的caffenet模型,位置在 models/bvlc_reference_caffenet/文件夹下, 将需要的两个配置文件,复制到myfile文件夹内
# sudo cp models/bvlc_reference_caffenet/solver.prototxt examples/myfile/
# sudo cp models/bvlc_reference_caffenet/train_val.prototxt examples/myfile/
修改其中的solver.prototxt
# sudo vi examples/myfile/solver.prototxt
net: "examples/myfile/train_val.prototxt"
test_iter: 2
test_interval: 50
base_lr: 0.001
lr_policy: "step"
gamma: 0.1
stepsize: 100
display: 20
max_iter: 500
momentum: 0.9
weight_decay: 0.005
solver_mode: GPU
100个测试数据,batch_size为50,因此test_iter设置为2,就能全cover了。在训练过程中,调整学习率,逐步变小。
修改train_val.protxt,只需要修改两个阶段的data层就可以了,其它可以不用管。
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "examples/myfile/mean.binaryproto"
}
data_param {
source: "examples/myfile/img_train_lmdb"
batch_size: 256
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "examples/myfile/mean.binaryproto"
}
data_param {
source: "examples/myfile/img_test_lmdb"
batch_size: 50
backend: LMDB
}
}
实际上就是修改两个data layer的mean_file和source这两个地方,其它都没有变化 。
五、训练和测试
如果前面都没有问题,数据准备好了,配置文件也配置好了,这一步就比较简单了。
# sudo build/tools/caffe train -solver examples/myfile/solver.prototxt
运行时间和最后的精确度,会根据机器配置,参数设置的不同而不同。我的是gpu+cudnn运行500次,大约8分钟,精度为95%。

转 Caffe学习系列(12):训练和测试自己的图片的更多相关文章
- Caffe学习系列(12):不同格式下计算图片的均值和caffe.proto
均值是所有训练样本的均值,减去之后再进行训练会提高其速度和精度. 1.caffe下的均值 数据格式是二进制的binaryproto,作者提供了计算均值的文件compute_image_mean, 计算 ...
- Caffe学习系列(12):训练和测试自己的图片--linux平台
Caffe学习系列(12):训练和测试自己的图片 学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测 ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- Caffe 学习系列
学习列表: Google protocol buffer在windows下的编译 caffe windows 学习第一步:编译和安装(vs2012+win 64) caffe windows学习:第一 ...
- Caffe学习系列(23):如何将别人训练好的model用到自己的数据上
caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model.这个model将图片分为1000类,应该是目前为止最好的图片分类model了. 假设我现在有一些自己的图片想进行分 ...
- Caffe系列4——基于Caffe的MNIST数据集训练与测试(手把手教你使用Lenet识别手写字体)
基于Caffe的MNIST数据集训练与测试 原创:转载请注明https://www.cnblogs.com/xiaoboge/p/10688926.html 摘要 在前面的博文中,我详细介绍了Caf ...
- Caffe学习系列(22):caffe图形化操作工具digits运行实例
上接:Caffe学习系列(21):caffe图形化操作工具digits的安装与运行 经过前面的操作,我们就把数据准备好了. 一.训练一个model 右击右边Models模块的” Images" ...
- Caffe学习系列(21):caffe图形化操作工具digits的安装与运行
经过前面一系列的学习,我们基本上学会了如何在linux下运行caffe程序,也学会了如何用python接口进行数据及参数的可视化. 如果还没有学会的,请自行细细阅读: caffe学习系列:http:/ ...
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
随机推荐
- 《.NET 设计规范》第 4 章:类型设计规范
第 4 章:类型设计规范 4.1 类型和命名空间 要用命名空间把类型组织成一个由相关的功能区所构成的层次结构中. 避免非常深的命名空间层次.因为用户需要经常回找,所以这样的层次浏览起来很困难. 避免有 ...
- mvn mybatis-generator:generate postgresql
postgresql 配置文件 <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE genera ...
- JS高级程序设计第3章读书笔记
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- HDU 6181 Two Paths
这是一道次短路的题 但是本题有两个坑 注意边权的范围,一定要在所有与距离有关的地方开 long long 本题所求的并不是次短路,而是与最短路不同的最短的路径,如果最短路不止一条,那么就输出最短路的长 ...
- bzoj 4825: [Hnoi2017]单旋 [lct]
4825: [Hnoi2017]单旋 题意:有趣的spaly hnoi2017刚出来我就去做,当时这题作死用了ett,调了5节课没做出来然后发现好像直接用lct就行了然后弃掉了... md用lct不知 ...
- CF 375D. Tree and Queries加强版!!!【dfs序分块 大小分类讨论】
传送门 题意: 一棵树,询问一个子树内出现次数$\ge k$的颜色有几种,Candy?这个沙茶自带强制在线 吐槽: 本来一道可以离散的莫队我非要强制在线用分块做:上午就开始写了然后发现思路错了...: ...
- BZOJ 1488: [HNOI2009]图的同构 [Polya]
完全图中选出不同构的简单图有多少个 上题简化版,只有两种颜色....直接copy就行了 太诡异了,刚才电脑上多了一个不动的鼠标指针,然后打开显卡管理界面就没了 #include<iostream ...
- POJ 2826 An Easy Problem?![线段]
An Easy Problem?! Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 12970 Accepted: 199 ...
- C#开发短信发送
//需要用到的命名空间 using System.Net;using System.IO;using System.Text;//调用时只需要把拼成的URL传给该函数即可.判断返回值即可public ...
- 通过Log4net来配置我们需要的日志文件格式
我们先来看看配置写入txt文件是如何 的,当然不止可以配置txt格式还有其它格式. <?xml version="1.0" encoding="utf-8&qu ...