Python爬虫教程-15-读取cookie(人人网)和SSL(12306官网)
Python爬虫教程-15-爬虫读取cookie(人人网)和SSL(12306官网)
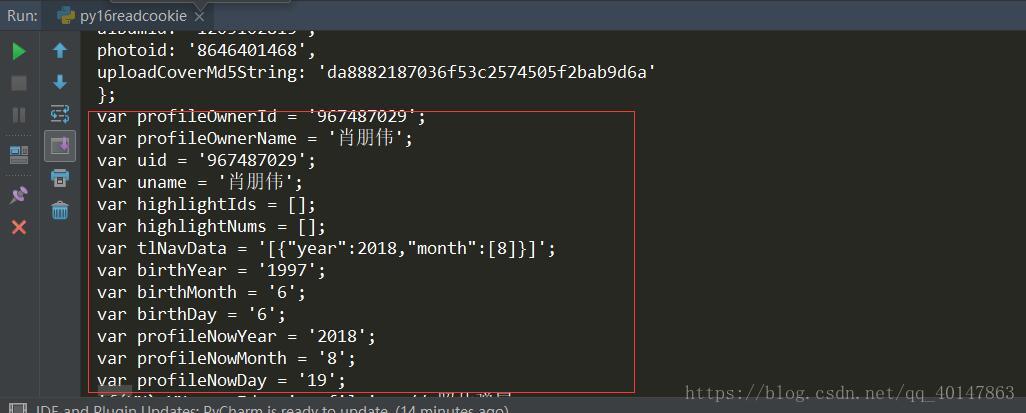
上一篇写道关于存储cookie文件,本篇介绍怎样读取cookie文件
cookie的读取
# 读取cookie文件
from urllib import request,parse
from http import cookiejar
# 创建cookiejar的实例
cookie = cookiejar.MozillaCookieJar()
cookie.load('py15renrenCookie.txt', ignore_discard=True, ignore_expires=True)
# 常见cookie的管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
# 创建http请求的管理器
http_handler = request.HTTPHandler()
# 生成https管理器
https_handler = request.HTTPSHandler()
# 创建请求管理器
opener = request.build_opener(http_handler,https_handler,cookie_handler)
def getHomePage():
# 地址是用在浏览器登录后的个人信息页地址
url = "http://www.renren.com/967487029/profile"
# 如果已经执行login函数,则opener自动已经包含cookie
rsp = opener.open(url)
html = rsp.read().decode()
with open("py13rsp.html", "w", encoding="utf-8")as f:
# 将爬取的页面
print(html)
f.write(html)
if __name__ == '__main__':
getHomePage()
运行结果
同样是当返回页面有个人信息,才算成功!
SSL
- ssl证书就是指遵守ssl安全套阶层协议的服务器数字证书(SercureSocketLayer)
- 美国网景公司开发
- 使用ssl,加密信息
- 俗称https协议
- CA(CertificateAuthority)是数字证书任重中心,是发放,管理,废除数字证书的收信人的第三方机构
- 遇到不信任的SSL证书,需要单独处理
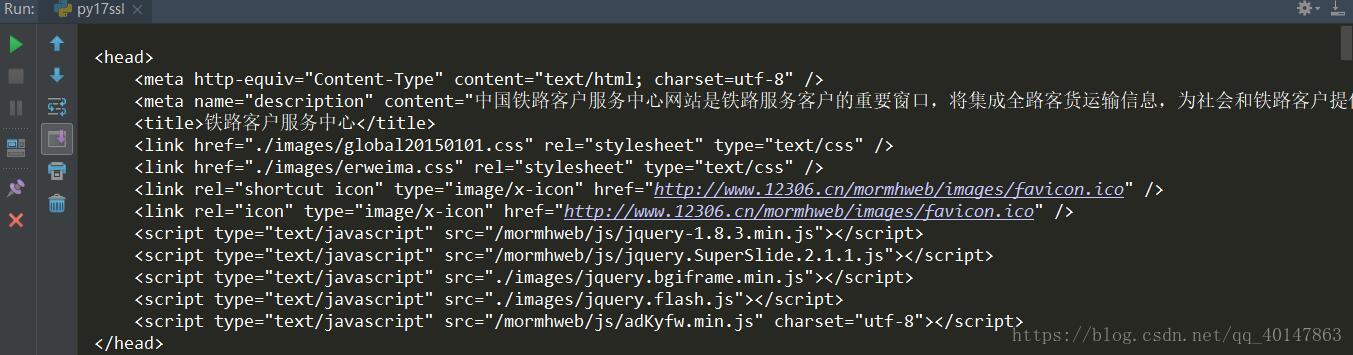
- 案例v17ssl文件:
'''
使用ssl
1.直接访问https://www.12306.cn/mormhweb/会无法访问,报错如下
----------------------------------
您的连接不是私密连接
攻击者可能会试图从 www.12306.cn 窃取您的信息
(例如:密码、通讯内容或信用卡信息)
-----------------------------------
2.不使用https使用http解可以访问
3.因为12306的证书是自己做的,而不是第三方机构
4.所以说http不安全会泄露个人信息
'''
from urllib import request
import ssl
# 利用非认证上下文环境替换认证的上下文环境
ssl._create_default_https_context = ssl._create_unverified_context
url = "https://www.12306.cn/mormhweb/"
rsp = request.urlopen(url)
html = rsp.read().decode()
print(html)
运行结果
不是报错页面,表示使用成功
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-15-读取cookie(人人网)和SSL(12306官网)的更多相关文章
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-14-爬虫使用filecookiejar保存cookie文件(人人网)
Python爬虫教程-14-爬虫使用filecookiejar保存cookie文件(人人网) 上一篇介绍了利用CookieJar访问人人网,本篇将使用filecookiejar将cookie以文件形式 ...
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下) 自动使用cookie的方法,告别手动拷贝cookie http模块包含一些关于cookie的模块,通过他们我们可以自动的使用co ...
- Python爬虫教程-12-爬虫使用cookie爬取登录后的页面(人人网)(上)
Python爬虫教程-12-爬虫使用cookie(上) 爬虫关于cookie和session,由于http协议无记忆性,比如说登录淘宝网站的浏览记录,下次打开是不能直接记忆下来的,后来就有了cooki ...
- Python爬虫入门六之Cookie的使用
大家好哈,上一节我们研究了一下爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在 ...
- python爬虫 - Urllib库及cookie的使用
http://blog.csdn.net/pipisorry/article/details/47905781 lz提示一点,python3中urllib包括了py2中的urllib+urllib2. ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
随机推荐
- [转] Linux中的默认权限与隐藏权限(文件、目录)
[From] https://blog.csdn.net/davidsky11/article/details/25424615 一个文件(或目录)拥有若干个属性,包括(r/w/x)等基本属性,以及是 ...
- gitlab之gitlab-runner自动部署(二)
转载自:https://blog.csdn.net/hxpjava1/article/details/78514999 简介 gitlab-ci全称是gitlab continuous integra ...
- 【数据服务中间件】一、HttpServlet
一.概念 Servlet的框架是由两个Java包组成:javax.servlet和javax.servlet.http GenericServlet和HttpServlet 3个方法代表了Servle ...
- 基于web端去除空格小工具
读论文时,不时需要抓取PDF版的段落,可是复制到word的时候会出现很多空格,利用javascript强大的功能,几行命令实现了去除段落里的空格,实现如下: <!DOCTYPE html PUB ...
- 【DB2】普通用户最小查询权限分配
1. 通过实例用户或者有dbadm权限的用户连接数据库 db2 connect to <db-name> 2. 分配普通用户连接权限db2 "grant connect on d ...
- eclipse中修改tomcat的配置,解决全局性的get提交乱码问题
在项目中如果页面提交方式为get的时候,中文会出现乱码. 为了解决乱码问题我们有两种办法. 第一种:在程序中加入get提交乱码的解决 String username = new String(user ...
- H5页面JS调试
页面调试 常用的调试方法 开发时候的调试基本是在chrome的控制台Emulation完成 现有的一些手机端调试方案: Remote debugging with Opera Dragonfly 需要 ...
- 大型网站技术学习-3. 容器Docker与kubernetes
大型网站技术基石篇-容器Docker与kubernetes Docker和Kubernetes的关系就如Xen与OpenStack. Docker是一种容器技术,和Hypervisor(KVM/X ...
- iostat命令——监控系统设备的IO负载情况
iostat命令的安装 #yum install sysstat iostat常见选项 -t 输出数据时打印搜集数据的时间 -m 输出的数据以MB为单位 -d 显示磁盘的统计信息 # iost ...
- step6: item与pipeline
目的:提取内容进行格式化输出,类似于字典 编写item文件 class JobBoleArticleItem(scrapy.Item): title = scrapy.Field() #支持传进任何数 ...