Puppeteer爬虫实战(二)
连接浏览器
上一篇说到了Puppeteer本质是使用了Chrome Devtools协议控制浏览器,本篇就说说连接方式。
常规Hook浏览器
此方式其实就是需要一个浏览器可执行文件(不同平台需要下载对应平台文件),Puppeteer有两种方式,一种是安装Puppeteer包时下载的文件,另一种是自己下载文件通过环境变量指向文件路径就可以了(上篇文章有详细介绍),下面的演示为了视频我使用headless: false开启了FullHead模式。
在vscode里面使用export可查看环境变量
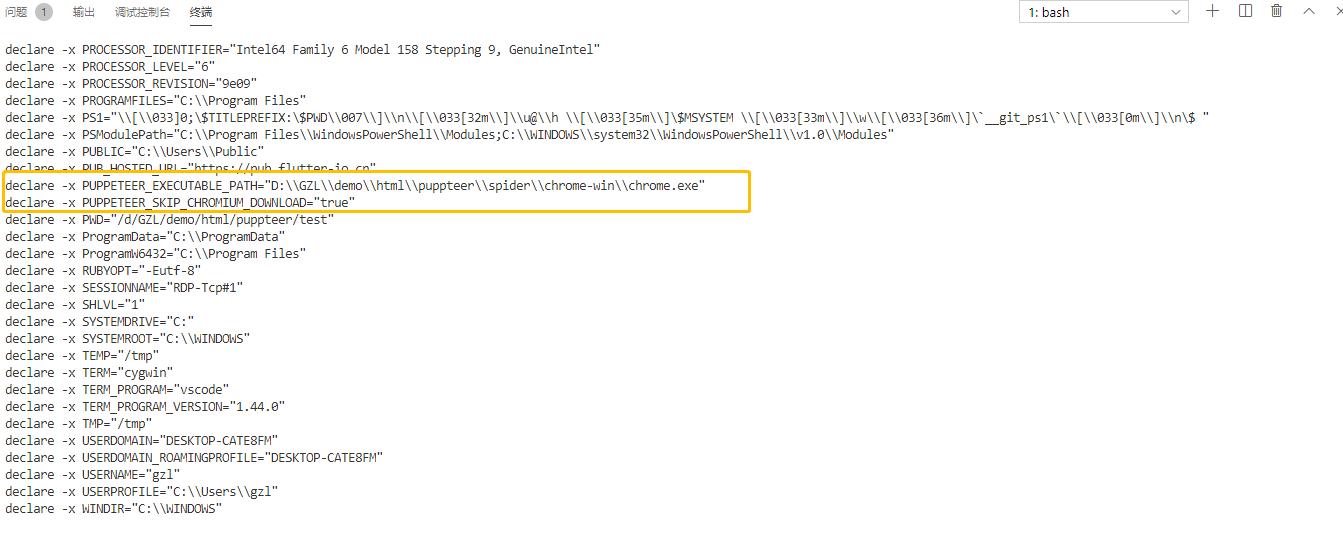
以上是我习惯的环境变量设置(使用launch参数executablePath也可达到同样效果,个人觉得环境变量更灵活),下面一段脚本来看看效果。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://www.cnblogs.com/');
await page.screenshot({ path: 'cnblogs.png' });
await browser.close();
})();

使用已经存在的浏览器
首先开启浏览器远程调试,配置端口
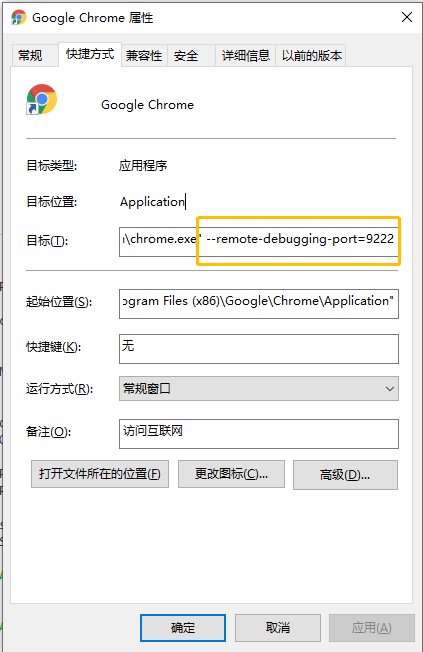
在浏览器的快捷方式加上 --remote-debugging-port=9222 即可,详细配置
下面一段脚本来看看效果
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.connect({
browserWSEndpoint: "ws://localhost:9222/devtools/browser/60442671-d10c-4236-b4e1-41c5f1d28b87",
headless: false
});
const page = await browser.newPage();
await page.goto('https://www.cnblogs.com/');
await page.screenshot({ path: 'cnblogs.png' });
// await browser.close();
})();
上面的代码可以看到browserWSEndpoint指定了一个地址,这个地址可以从下面获取
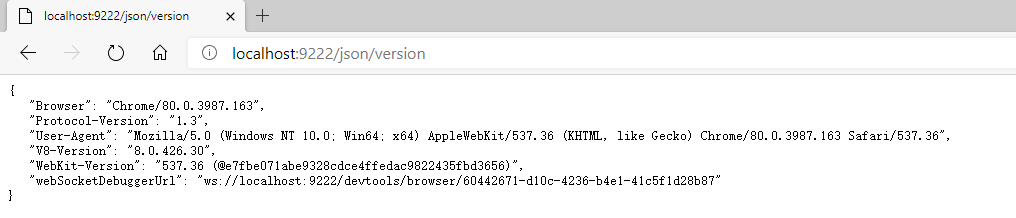
使用了Edge,嘿嘿
Puppeteer爬虫实战(二)的更多相关文章
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- Puppeteer爬虫实战(一)
Puppeteer 爬虫技术实践 信息简介 Puppeteer是Chrome开发团队发布的一个通过Chrome DevTool Protocol来控制浏览器Chrome(下文若无显式称呼Chromiu ...
- 爬虫实战(二) 51job移动端数据采集
在上一篇51job职位信息的爬取中,对岗位信息div下各式各样杂乱的标签,简单的Xpath效果不佳,加上string()函数后,也不尽如人意.因此这次我们跳过桌面web端,选择移动端进行爬取. ...
- 爬虫实战(二) 用Python爬取网易云歌单
最近,博主喜欢上了听歌,但是又苦于找不到好音乐,于是就打算到网易云的歌单中逛逛 本着 "用技术改变生活" 的想法,于是便想着写一个爬虫爬取网易云的歌单,并按播放量自动进行排序 这篇 ...
- Puppeteer爬虫实战(三)
本篇文章针对大家熟知的技术站点作为目标进行技术实践. 确定需求 访问目标网站并按照筛选条件(关键词.日期.作者)进行检索并获取返回数据中的目标数据.进行技术拆分如下: 打开目标网站 找到输入框元素 ...
- 自学Python九 爬虫实战二(美图福利)
作为一个新世纪有思想有文化有道德时刻准备着的屌丝男青年,在现在这样一个社会中,心疼我大慢播抵制大百度的前提下,没事儿上上网逛逛YY看看斗鱼翻翻美女图片那是必不可少的,可是美图虽多翻页费劲!今天我们就搞 ...
- Python网络爬虫实战(二)数据解析
上一篇说完了如何爬取一个网页,以及爬取中可能遇到的几个问题.那么接下来我们就需要对已经爬取下来的网页进行解析,从中提取出我们想要的数据. 根据爬取下来的数据,我们需要写不同的解析方式,最常见的一般都是 ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
随机推荐
- SpringCloud与Eureka,Feign,Ribbon,Hystrix,Zuul核心组件间的关系
Eureka:各个服务启动时,Eureka Client都会将服务注册到Eureka Server,并且Eureka Client还可以反过来从Eureka Server拉取注册表,从而知道其他服务在 ...
- java scoket Blocking 阻塞IO socket通信二
在上面一节中,服务端收到客户端的连接之后,都是new一个新的线程来处理客户端发送的请求,每次new 一个线程比较耗费系统资源,如果100万个客户端,我们就要创建100万个线程,相当的 耗费系统的资源, ...
- 个人项目-Wc-Java
一.Github项目地址: https://github.com/Heiofungfming/xiaoming01 二.PSP表格 PSP2.1 任务内容 计划完成需要的时间(min) 实际完成需要的 ...
- linux 配置ssh免密登录
一.SSH概念(百度) SSH 为 Secure Shell 的缩写,由 IETF 的网络小组(Network Working Group)所制定:SSH 为建立在应用层基础上的安全协议.SSH 是目 ...
- caffe的python接口学习(3)训练模型training
如果不进行可视化,只想得到一个最终的训练model, 那么代码非常简单,如下 : import caffe caffe.set_device(0) caffe.set_mode_gpu() solve ...
- (win7) 在IIS6.0 中配置项目
1.进入IIS管理器 右击“计算机”->管理->服务和应用程序->Internet信息服务(IIS)管理器 2.将项目加入IIS中 网站->右击“默认网站”->添加虚拟目 ...
- Feign拦截器应用 (F版)
Spring Cloud 为开发者提供了在分布式系统中的一些常用的组件(例如配置管理,服务发现,断路器,智能路由,微代理,控制总线,一次性令牌,全局锁定,决策竞选,分布式会话集群状态).使用Sprin ...
- abp + vue 模板新建页面
新建页面 创建按对应的模块和实体 新建的模块需要进行注册
- 【react】实现动态表单中嵌套动态表单
要实现一个功能动态表单中嵌套动态表单如下: 仔细看看antd的文档其实不难 具体步骤如下 1.建立一个 名为 ConcatRegion的组件(动态表单A)代码如下 export function Co ...
- SQL注入原理及代码分析(一)
前言 我们都知道,学安全,懂SQL注入是重中之重,因为即使是现在SQL注入漏洞依然存在,只是相对于之前现在挖SQL注入变的困难了.而且知识点比较多,所以在这里总结一下.通过构造有缺陷的代码,来理解常见 ...