Puppeteer爬虫实战(二)
连接浏览器
上一篇说到了Puppeteer本质是使用了Chrome Devtools协议控制浏览器,本篇就说说连接方式。
常规Hook浏览器
此方式其实就是需要一个浏览器可执行文件(不同平台需要下载对应平台文件),Puppeteer有两种方式,一种是安装Puppeteer包时下载的文件,另一种是自己下载文件通过环境变量指向文件路径就可以了(上篇文章有详细介绍),下面的演示为了视频我使用headless: false开启了FullHead模式。
在vscode里面使用export可查看环境变量
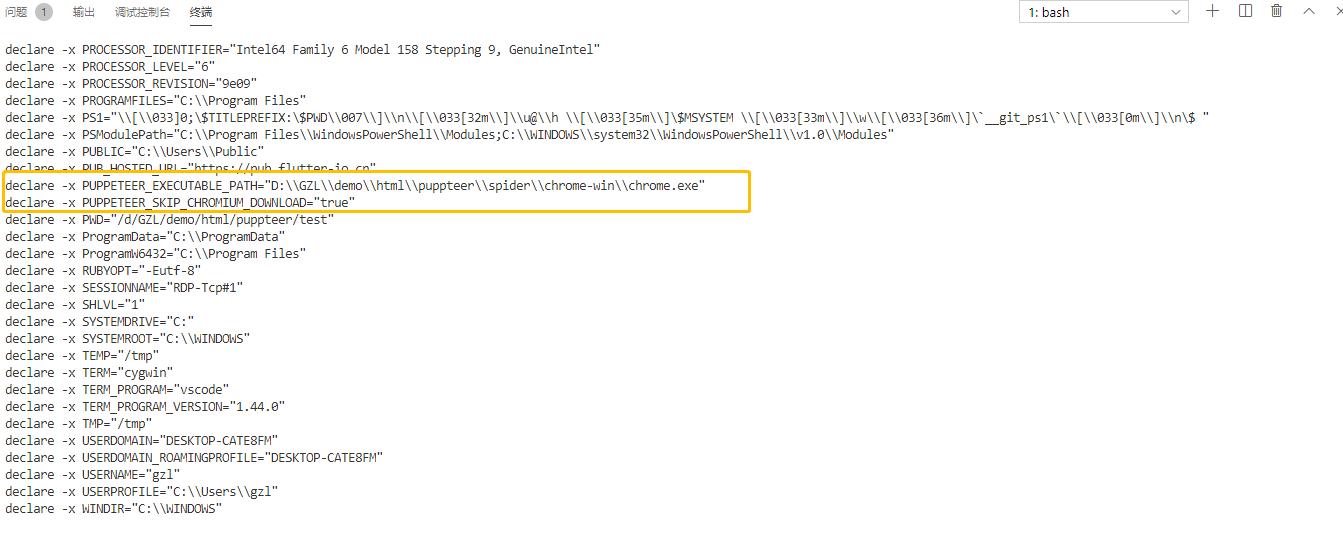
以上是我习惯的环境变量设置(使用launch参数executablePath也可达到同样效果,个人觉得环境变量更灵活),下面一段脚本来看看效果。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://www.cnblogs.com/');
await page.screenshot({ path: 'cnblogs.png' });
await browser.close();
})();

使用已经存在的浏览器
首先开启浏览器远程调试,配置端口
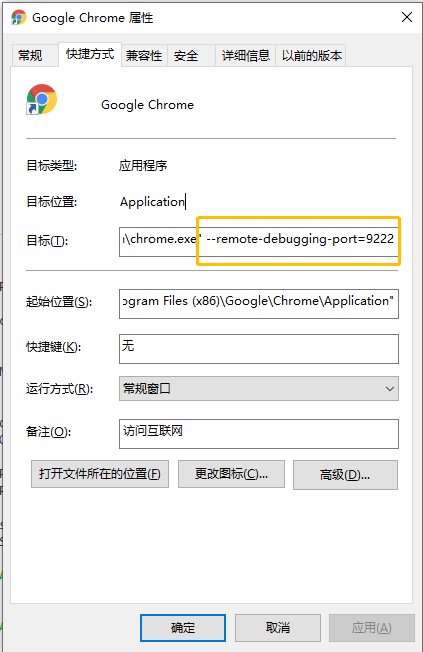
在浏览器的快捷方式加上 --remote-debugging-port=9222 即可,详细配置
下面一段脚本来看看效果
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.connect({
browserWSEndpoint: "ws://localhost:9222/devtools/browser/60442671-d10c-4236-b4e1-41c5f1d28b87",
headless: false
});
const page = await browser.newPage();
await page.goto('https://www.cnblogs.com/');
await page.screenshot({ path: 'cnblogs.png' });
// await browser.close();
})();
上面的代码可以看到browserWSEndpoint指定了一个地址,这个地址可以从下面获取
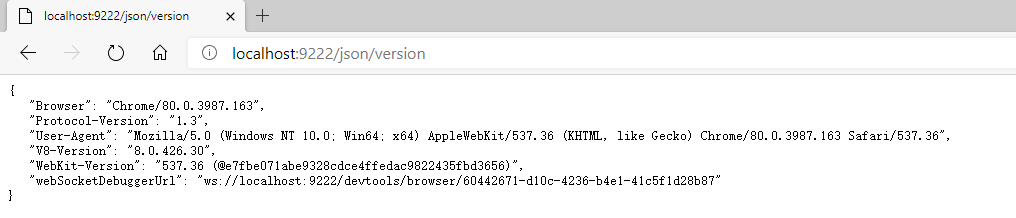
使用了Edge,嘿嘿
Puppeteer爬虫实战(二)的更多相关文章
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- Puppeteer爬虫实战(一)
Puppeteer 爬虫技术实践 信息简介 Puppeteer是Chrome开发团队发布的一个通过Chrome DevTool Protocol来控制浏览器Chrome(下文若无显式称呼Chromiu ...
- 爬虫实战(二) 51job移动端数据采集
在上一篇51job职位信息的爬取中,对岗位信息div下各式各样杂乱的标签,简单的Xpath效果不佳,加上string()函数后,也不尽如人意.因此这次我们跳过桌面web端,选择移动端进行爬取. ...
- 爬虫实战(二) 用Python爬取网易云歌单
最近,博主喜欢上了听歌,但是又苦于找不到好音乐,于是就打算到网易云的歌单中逛逛 本着 "用技术改变生活" 的想法,于是便想着写一个爬虫爬取网易云的歌单,并按播放量自动进行排序 这篇 ...
- Puppeteer爬虫实战(三)
本篇文章针对大家熟知的技术站点作为目标进行技术实践. 确定需求 访问目标网站并按照筛选条件(关键词.日期.作者)进行检索并获取返回数据中的目标数据.进行技术拆分如下: 打开目标网站 找到输入框元素 ...
- 自学Python九 爬虫实战二(美图福利)
作为一个新世纪有思想有文化有道德时刻准备着的屌丝男青年,在现在这样一个社会中,心疼我大慢播抵制大百度的前提下,没事儿上上网逛逛YY看看斗鱼翻翻美女图片那是必不可少的,可是美图虽多翻页费劲!今天我们就搞 ...
- Python网络爬虫实战(二)数据解析
上一篇说完了如何爬取一个网页,以及爬取中可能遇到的几个问题.那么接下来我们就需要对已经爬取下来的网页进行解析,从中提取出我们想要的数据. 根据爬取下来的数据,我们需要写不同的解析方式,最常见的一般都是 ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
随机推荐
- app之功能测试
1 什么是APP测试? App测试就是软件工程师对这类应用软件进行功能测试,性能测试,安全性测试以及兼容性测试等. 对于app测试我们一般采用的是黑盒测试方法,也会在必要的时候进行自动化测试以及性能测 ...
- 洛谷 CF1012C Hills (动态规划)
题目大意:有n个山丘 , 可以在山丘上建房子 , 建房子的要求是 : 该山丘的左右山丘严格的矮于该山丘 (如果有的话),你有一架挖掘机,每单位时间可以给一个山丘挖一个单位的高度,问你想要建造 1,2, ...
- ceph luminous版本的安装部署
1. 前期准备 本次安装环境为: ceph1(集群命令分发管控,提供磁盘服务集群) CentOs7.5 10.160.20.28 ceph2(提供磁盘服务集群) CentOs7.5 10. ...
- 半导体质量管理_SQM 供应商质量管理
供应链上的质量保证 SPACE的此附加组件可帮助您与全球生产现场的供应商和分包商更紧密地合作.基于电子分析证书(eCOA,电子分析证书),您可以为整个供应链实施具有约束力的质量标准,并可以对其进行验证 ...
- 一文读懂 Redis 分布式部署方案
为什么要分布式 Redis是一款开源的基于内存的K-V型数据库,因为内存访问速度快,一般被用来做系统的缓存. Redis作为单机部署能够支持业务简单,数据量不大的系统需求,但在实际应用中,一旦系统规模 ...
- 又一款开源图标库 CSS.GG,值得一用
嗨,我是 Martin,也叫老王,今天推荐一款好用的开源图标库. 我们平常找图标往往会去 iconfont 但是今天,我们看了 Martin 的文章之后,就会有一个新的选择--CSS.GG Githu ...
- 树的子结构(剑指offer-17)
题目描述 输入两棵二叉树A,B,判断B是不是A的子结构.(ps:我们约定空树不是任意一个树的子结构) 解析 解答 /** public class TreeNode { int val = 0; Tr ...
- ASP.NET网页请求以及处理全过程(反编译工具查看源代码)
本文是自己查看源码后的个人总结,不保证其准确性.大家可作为参考. 浏览器和服务器之间的通信. 当敲一个域名到浏览器上面,然后回车的时候,如:http://www.baidu.com/index.asp ...
- 实现new关键字
一.new做了什么 1.创建了一个全新的对象. 2.这个对象会被执行[[Prototype]](也就是__proto__)链接. 3.生成的新对象会绑定到函数调用的this. 4.通过new创建的每个 ...
- java IO流 (七) 对象流的使用
1.对象流: ObjectInputStream 和 ObjectOutputStream2.作用:ObjectOutputStream:内存中的对象--->存储中的文件.通过网络传输出去:序列 ...