[elk]elasticsearch实现冷热数据分离
本文以最新的elasticsearch-6.3.0.tar.gz为例,为了节约资源,本文将副本调为0, 无client角色
https://www.elastic.co/blog/hot-warm-architecture-in-elasticsearch-5-x
以前es2.x版本配置elasticsearch.yml 里的node.tag: hot这个配置不生效了
被改成了这个
node.attr.box_type: hot
es架构
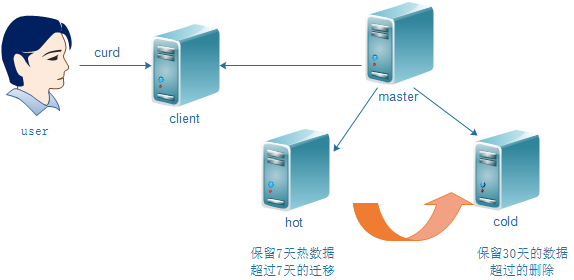
各节点的es配置
master节点:
[root@n1 ~]# cat /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: elk
node.master: true
node.data: false
node.name: 192.168.2.11
#node.attr.box_type: hot
#node.tag: hot
path.data: /data/es
path.logs: /data/log
network.host: 192.168.2.11
http.port: 9200
transport.tcp.port: 9300
transport.tcp.compress: true
discovery.zen.ping.unicast.hosts: ["192.168.2.11"]
cluster.routing.allocation.disk.watermark.low: 85%
cluster.routing.allocation.disk.watermark.high: 90%
indices.fielddata.cache.size: 10%
indices.breaker.fielddata.limit: 30%
http.cors.enabled: true
http.cors.allow-origin: "*"
- client节点(这里就不配置了)
node.master: false
node.data: false
- hot节点
[root@n2 ~]# cat /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: elk
node.master: false
node.data: true
node.name: 192.168.2.12
node.attr.box_type: hot
path.data: /data/es
network.host: 192.168.2.12
http.port: 9200
transport.tcp.port: 9300
transport.tcp.compress: true
discovery.zen.ping.unicast.hosts: ["192.168.2.11"]
cluster.routing.allocation.disk.watermark.low: 85%
cluster.routing.allocation.disk.watermark.high: 90%
indices.fielddata.cache.size: 10%
indices.breaker.fielddata.limit: 30%
http.cors.enabled: true
http.cors.allow-origin: "*"
- cold节点
[root@n3 ~]# cat /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: elk
node.master: false
node.data: true
node.name: 192.168.2.13
node.attr.box_type: cold
path.data: /data/es
network.host: 192.168.2.13
http.port: 9200
transport.tcp.port: 9300
transport.tcp.compress: true
discovery.zen.ping.unicast.hosts: ["192.168.2.11"]
cluster.routing.allocation.disk.watermark.low: 85%
cluster.routing.allocation.disk.watermark.high: 90%
indices.fielddata.cache.size: 10%
indices.breaker.fielddata.limit: 30%
http.cors.enabled: true
http.cors.allow-origin: "*"
如何实现某索引数据写到指定的node?(根据节点tag即可)
我hot节点打了tag
node.attr.box_type: cold
创建一个template(这里我用kibana来操作es的api)
PUT _template/test
{
"index_patterns": "test-*",
"settings": {
"index.number_of_replicas": "0",
"index.routing.allocation.require.box_type": "hot"
}
}
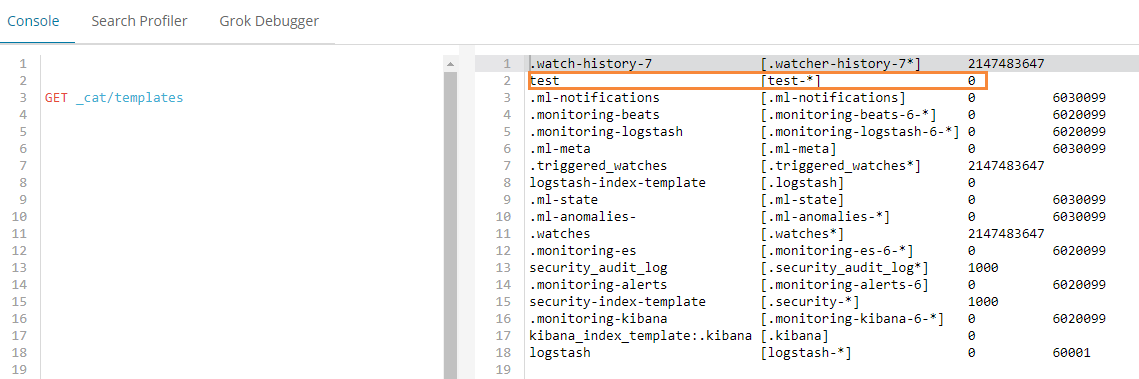
意思是test-*索引命名的,都将其数据放到hot节点上.
如何实现数据从hot节点迁移到老的cold节点?
以test-2018.07.05索引为例,将它从hot节点迁移到cold节点
kibana里操作:
PUT /test-2018.07.05/_settings
{
"settings": {
"index.routing.allocation.require.box_type": "cold"
}
}
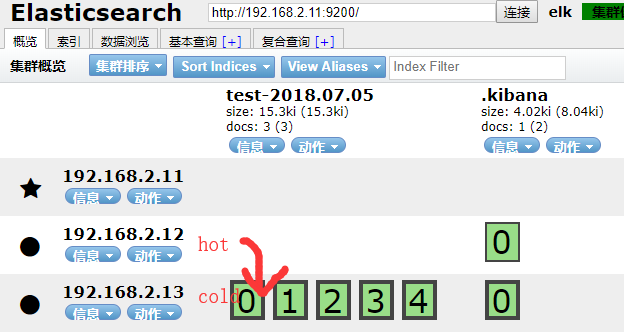
生产中可能每天,或每h,生成一个index.
test-2018.07.01
test-2018.07.02
test-2018.07.03
test-2018.07.04
test-2018.07.05
...
我可以写一个sh定时任务,每天晚上定时迁移数据.
如我在hot节点只保留7天的数据,7天以前的索引我匹配到, 每天晚上执行以下迁移命令即可.
cold节点数据保留1个月?
https://www.cnblogs.com/iiiiher/p/8029062.html
优化点:
1.为了提高吞吐量
path.data:/data1,/data2,/data3,/data4,/data5 可以每个目录挂一块盘
2.如果有10台hot节点,可以设置10个shards
logstash测试
input { stdin { } }
output {
elasticsearch {
index => "test-%{+YYYY.MM.dd}"
hosts => ["192.168.2.11:9200"]
}
stdout {codec => rubydebug}
}
/usr/local/logstash/bin/logstash -f logstash.yaml --config.reload.automatic
关于es的index template
关于es的template
es数据入库时候都会匹配一个index template,默认匹配的是logstash这个template
template大致分成setting和mappings两部分
- settings主要作用于index的一些相关配置信息,如分片数、副本数,tranlog同步条件、refresh等。
- mappings主要是一些说明信息,大致又分为_all、_source、prpperties这三部分: https://elasticsearch.cn/article/335
根据index name来匹配使用哪个index template. index template属于节点范围,而非全局. 需要给某个节点单独设置index_template(如给设置一些特有的tag).
[elk]elasticsearch实现冷热数据分离的更多相关文章
- ELK冷热数据分离
通常情况下,我们使用ELK日志分析平台最常用的数据时间为1周或一个月(因业务场景不同,可能存在差别),时间比较长的数据没有特殊情况可能我们就没有必要再进行查询了,但是因业务需求或者作为凭证,这些日 ...
- EFK教程(3) - ElasticSearch冷热数据分离
基于ElasticSearch多实例架构,实现资源合理分配.冷热数据分离 作者:"发颠的小狼",欢迎转载与投稿 目录 ▪ 用途 ▪ 架构 ▪ 192.168.1.51 elasti ...
- 分布式mysql 和 zk ( zookeeper )的分布式的区别 含冷热数据讨论
zk ( zookeeper )的分布式仅仅指的是备份模式. 分布式 mysql 不仅仅要关注备份(从以往的半主,主主,到 paxos). (mysql 比 hbase 的region成熟, hdfs ...
- 使用ELK(Elasticsearch + Logstash + Kibana) 搭建日志集中分析平台实践--转载
原文地址:https://wsgzao.github.io/post/elk/ 另外可以参考:https://www.digitalocean.com/community/tutorials/how- ...
- ELk(Elasticsearch, Logstash, Kibana)的安装配置
目录 ELk(Elasticsearch, Logstash, Kibana)的安装配置 1. Elasticsearch的安装-官网 2. Kibana的安装配置-官网 3. Logstash的安装 ...
- ELK(elasticsearch+kibana+logstash)搜索引擎(二): elasticsearch基础教程
1.elasticsearch的结构 首先elasticsearch目前的结构为 /index/type/id id对应的就是存储的文档ID,elasticsearch一般将数据以JSON格式存储. ...
- ElasticSearch5.X的冷热数据架构
转载:https://my.oschina.net/xiaomaijiang/blog/826701 当使用ElasticSearch做大规模的时序数据分析的时候,我们建议使用基于时序的索引并且采用3 ...
- CentOS 6.x ELK(Elasticsearch+Logstash+Kibana)
CentOS 6.x ELK(Elasticsearch+Logstash+Kibana) 前言 Elasticsearch + Logstash + Kibana(ELK)是一套开源的日志管理方案, ...
- ELK(elasticsearch+logstash+kibana)入门到熟练-从0开始搭建日志分析系统教程
#此文篇幅较长,涵盖了elk从搭建到运行的知识,看此文档,你需要会点linux,还要看得懂点正则表达式,还有一个聪明的大脑,如果你没有漏掉步骤的话,还搭建不起来elk,你来打我. ELK使用elast ...
随机推荐
- Java设计模式从精通到入门五 抽象工厂方法模式
定义 抽象工厂类为创建一组相关和相互依赖的对象提供一组接口,而无需指定一个具体的类. 这里我得把工厂方法模式得定义拿出来做一下比较:定义一个创建对象的接口,由子类决定实例化哪一个类.工厂方法是一个 ...
- 想造轮子的时候,ctrl+f一下
Chardet,字符编码探测器,可以自动检测文本.网页.xml的编码. colorama,主要用来给文本添加各种颜色,并且非常简单易用. Prettytable,主要用于在终端或浏览器端构建格式化的输 ...
- thinkpad那些事儿
之前玩过windows系统的acer笔记本,联想台式机,os系统的mac pro笔记本,最近刚接触windows系统的thinkpad笔记本,对它的键盘触感印象深刻,舒服.thinkpad,思考本,是 ...
- node安装及配置之windows版
一.下载地址 https://nodejs.org/zh-cn/download/ https://nodejs.org/zh-cn/download/releases/ 二.安装步骤 1.双击“no ...
- 编辑datagridview单元格
以这3种为例,最简单的是第三种,直接让单元格处于可编辑状态,当完成编辑后触发CellEndEdit事件,最后对输入的数据进行处理. private DateTimePicker dtp = new D ...
- Mac如何彻底卸载Mysql
因为工作变动,到新公司需要安装开发环境,因为电脑是我的“前任”在使用,一般的开发环境都有,就直接上手代码,连接公司数据库.直到某天打算自己写点东西,连接本地的mysql,发现navicat怎么都连接不 ...
- Java笔记(十)堆与优先级队列
优先级队列 一.PriorityQueue PriorityQueue是优先级队列,它实现了Queue接口,它的队列长度 没有限制,与一般队列的区别是,它有优先级概念,每个元素都有优先 级,队头的元素 ...
- BZOJ5101 : [POI2018]Powód
求出Kruskal重构树,那么重构树上每个点的取值范围是定的. 考虑树形DP,则对于一个点,要么所有点水位相同,要么还未发生合并. 故$dp[x]=up[x]-down[x]+1+dp[l[x]]\t ...
- BZOJ4910 : [Sdoi2017] 苹果树
问题等价于树形依赖背包,允许一条链每个点各免费一次. 设$f[i][j]$表示按DFS序考虑到$i$,体积为$j$的最大收益. 先放入不能免费的物品,等遍历完儿子后再放入必选的物品,那么$i$到根路径 ...
- Java 多线程 ReadWriteLock
ReadWriteLock是JDK 1.5提供的读写分离锁,可以减少锁竞争.例如,线程A1.A2和A3进行写操作,线程B1.B2和B3进行读操作,如果使用重入锁或者内部锁,那么理论上所有读之间.读与写 ...