强化学习中经验池的替代设计——A3C算法
读论文《Asynchronous methods for deep reinforcement learning》有感
----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------
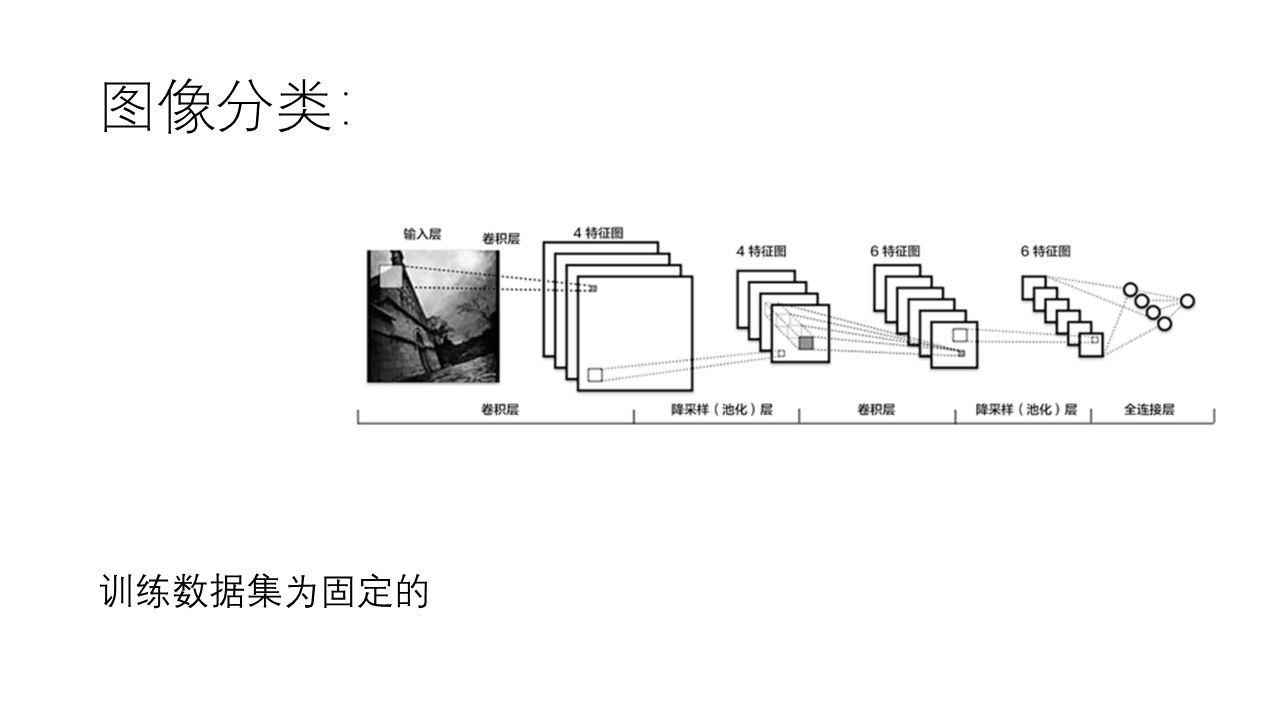
----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------
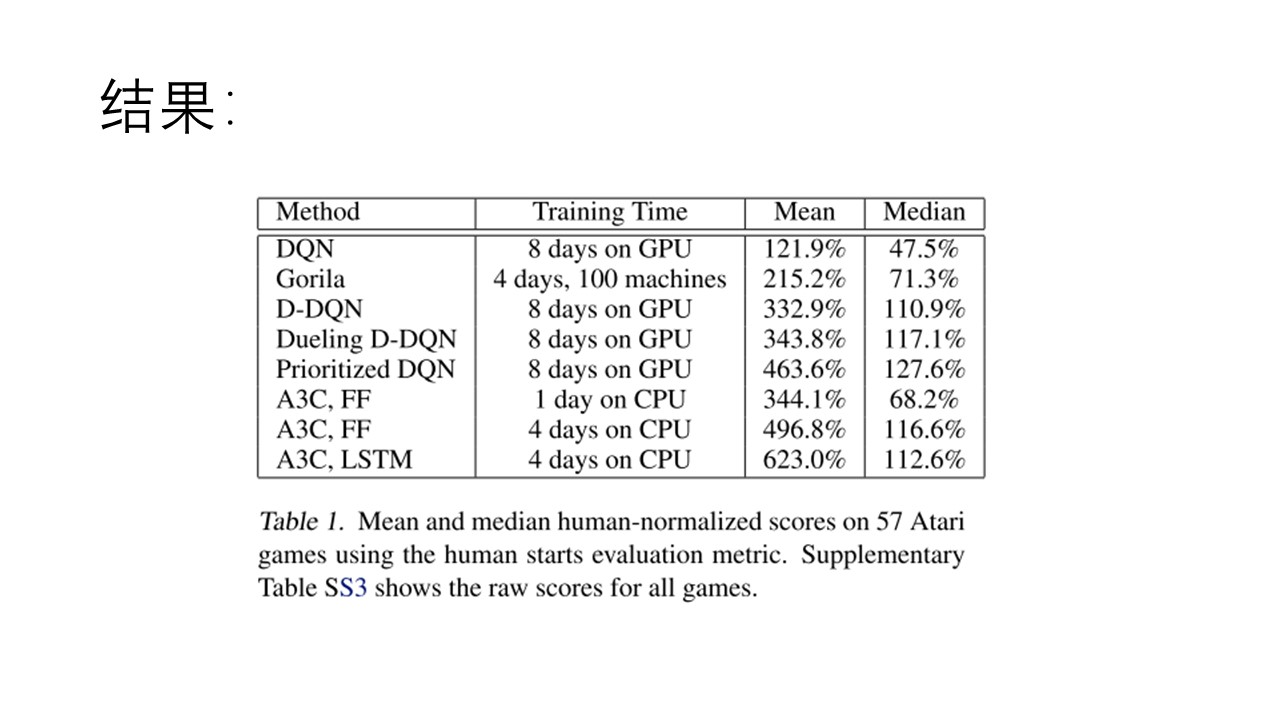
----------------------------------------------------------
强化学习中经验池的替代设计——A3C算法的更多相关文章
- 强化学习中REIINFORCE算法和AC算法在算法理论和实际代码设计中的区别
背景就不介绍了,REINFORCE算法和AC算法是强化学习中基于策略这类的基础算法,这两个算法的算法描述(伪代码)参见Sutton的reinforcement introduction(2nd). A ...
- 深度强化学习中稀疏奖励问题Sparse Reward
Sparse Reward 推荐资料 <深度强化学习中稀疏奖励问题研究综述>1 李宏毅深度强化学习Sparse Reward4 强化学习算法在被引入深度神经网络后,对大量样本的需求更加 ...
- 强化学习中的无模型 基于值函数的 Q-Learning 和 Sarsa 学习
强化学习基础: 注: 在强化学习中 奖励函数和状态转移函数都是未知的,之所以有已知模型的强化学习解法是指使用采样估计的方式估计出奖励函数和状态转移函数,然后将强化学习问题转换为可以使用动态规划求解的 ...
- 强化学习(五)—— 策略梯度及reinforce算法
1 概述 在该系列上一篇中介绍的基于价值的深度强化学习方法有它自身的缺点,主要有以下三点: 1)基于价值的强化学习无法很好的处理连续空间的动作问题,或者时高维度的离散动作空间,因为通过价值更新策略时是 ...
- 强化学习中的经验回放(The Experience Replay in Reinforcement Learning)
一.Play it again: reactivation of waking experience and memory(Trends in Neurosciences 2010) SWR发放模式不 ...
- SpiningUP 强化学习 中文文档
2020 OpenAI 全面拥抱PyTorch, 全新版强化学习教程已发布. 全网第一个中文译本新鲜出炉:http://studyai.com/course/detail/ba8e572a 个人认为 ...
- webservice入门程序学习中经验总结
***第一步:创建客户端服务 1)创建一个服务接口 2)创建一个实现类实现接口 3)创建一个方法开启服务 这三步注意点:::实现类上必须添加@WebService标签 :::发布服务的时候用到的函数是 ...
- 强化学习模型实现RL-Adventure
源代码:https://github.com/higgsfield/RL-Adventure 在Pytorch1.4.0上解决bug后的复现版本:https://github.com/lucifer2 ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- 强化学习算法DQN
1 DQN的引入 由于q_learning算法是一直更新一张q_table,在场景复杂的情况下,q_table就会大到内存处理的极限,而且在当时深度学习的火热,有人就会想到能不能将从深度学习中借鉴方法 ...
随机推荐
- JAVA RSA 私钥签名 公钥验证签名 公钥验签
JAVA RSA 私钥签名 公钥验证签名 公钥验签 1.待签名字符串转为byte数组时,一般使用UTF8. 2.将私钥字符串(PKCS8格式)转为PKCS8EncodedKeySpec对象. 3.使用 ...
- work05
第一题:分析以下需求,并用代码实现 手机类Phone 属性: 品牌brand 价格price 行为: 打电话call() 发短信sendMessage() 玩游戏playGame() 要求: 1.按照 ...
- 企业快速落地IT服务管理体系的六大关键步骤
许多企业在实施信息化战略时,一味地追求"技术高消费"而忽视了对信息技术的管理和内部业务流程的变革,侧重点仍然只是事后的技术支持和故障解决方面,随着企业对于信息技术的依赖程度的加重, ...
- Puremvc
Puremvc 框架unitypuremvc PureMVC健壮.易扩展.易维护 Many so-called Model-View-Controller frameworks today seem ...
- 使用python+pytesseract实现图片中文字的识别
一.安装tesseract 1.下载链接 https://digi.bib.uni-mannheim.de/tesseract/ 2.网盘下载地址 链接:https://pan.baidu.com/s ...
- 推荐一款基于业务行为驱动开发(BDD)测试框架:Cucumber!
大家好,我是狂师. 今天给大家介绍一款行为驱动开发测试框架:Cucumber. 1.介绍 Cucumber是一个行为驱动开发(BDD)工具,它结合了文本描述和自动化测试脚本.它使用一种名为Gherki ...
- 高通Android平台 电池 相关配置
背景 在新基线上移植有关的代码时,在log中发现有关的东西,请教了有关的同事以后,解决了这个问题. [ 12.775863] pmi632_charger: smblib_eval_chg_termi ...
- openfoam 修改 src 库经验记录
遇到一个问题,要把 sprayFoam 求解器的蒸发模型修改为自定义蒸发模型. sprayFoam 求解器本身没有实现蒸发模型,而是调用 $FOAM_SRC/lagrangian/intermedia ...
- 基于防火墙的SSLVPN
SCVPN即SSLVPN 拓补图 记得打开策略! 设置外接口(一些管理方式要打开) 设置SSL 地址池(如没要求设iP,随意设) 建立SSL VPN 出接口,地址池要选对 创建一个本地用户(账号A 密 ...
- [FLET] 02 route 测试
from typing import Dict import flet from flet import AppBar, ElevatedButton, Page, Text, View, color ...