编程作业2.2:Regularized Logistic regression
题目
在本部分的练习中,您将使用正则化的Logistic回归模型来预测一个制造工厂的微芯片是否通过质量保证(QA),在QA过程中,每个芯片都会经过各种测试来保证它可以正常运行。假设你是这个工厂的产品经理,你拥有一些芯片在两个不同测试下的测试结果,从这两个测试,你希望确定这些芯片是被接受还是拒绝,为了帮助你做这个决定,你有一些以前芯片的测试结果数据集,从中你可以建一个Logistic回归模型。
编程实现
在这部分训练中,我们将要通过加入正则项提升逻辑回归算法。简而言之,正则化是成本函数中的一个术语,它使算法更倾向于“更简单”的模型(在这种情况下,模型将更小的系数)。这个理论助于减少过拟合,提高模型的泛化能力。
1.Visualizing the data
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
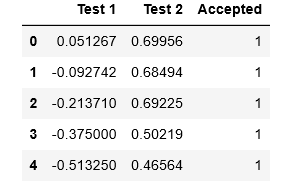
data2 = pd.read_csv('D:\BaiduNetdiskDownload\data_sets\ex2data2.txt', names=['Test 1', 'Test 2', 'Accepted'])
data2.head()
def plot_data():
# 把数据分成 positive 和 negetive 两类
positive = data2[data2['Accepted'].isin([1])]
negative = data2[data2['Accepted'].isin([0])]
fig, ax = plt.subplots(figsize=(8,5))
ax.scatter(positive['Test 1'], positive['Test 2'], s=50, c='b', marker='o', label='Accepted')
ax.scatter(negative['Test 1'], negative['Test 2'], s=50, c='r', marker='x', label='Rejected')
ax.legend(loc=2)
ax.set_xlabel('Test 1 Score')
ax.set_ylabel('Test 2 Score')
plot_data()
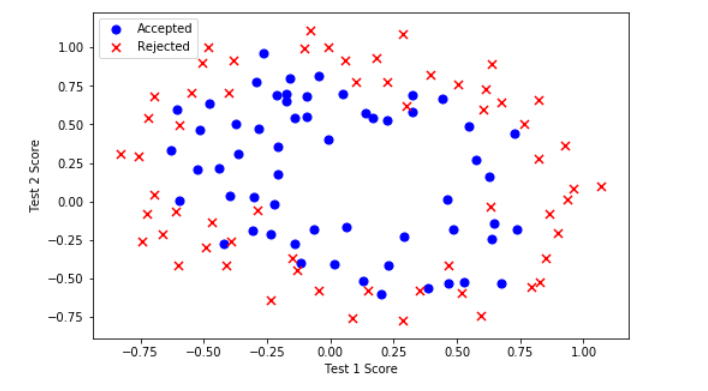
注意到其中的正负两类数据并没有线性的决策界限。因此直接用logistic回归在这个数据集上并不能表现良好,因为直接用logistic回归只能用来寻找一个线性的决策边界。
所以接下会提到一个新的方法。
2.Feature mapping
一个拟合数据的更好的方法是从每个数据点创建更多的特征。
我们将把这些特征映射到所有的x1和x2的多项式项上,直到第六次幂。
# 特征映射函数
def feature_mapping(x1, x2, power):
data = {}
for i in np.arange(power + 1): # for(i=0,i<power+1,i++)
for p in np.arange(i + 1): # for(p=0,p<i+1,p++)
data["f{}{}".format(i - p, p)] = np.power(x1, i - p) * np.power(x2, p) # f{i-p}{p} = x1^(i-p) * x2^(p)
# data = {"f{}{}".format(i - p, p): np.power(x1, i - p) * np.power(x2, p)
# for i in np.arange(power + 1)
# for p in np.arange(i + 1)
# }
return pd.DataFrame(data)
x1 = data2['Test 1'].values
x2 = data2['Test 2'].values
# 把特征映射到power=6
_data2 = feature_mapping(x1, x2, power=6)
_data2.head()
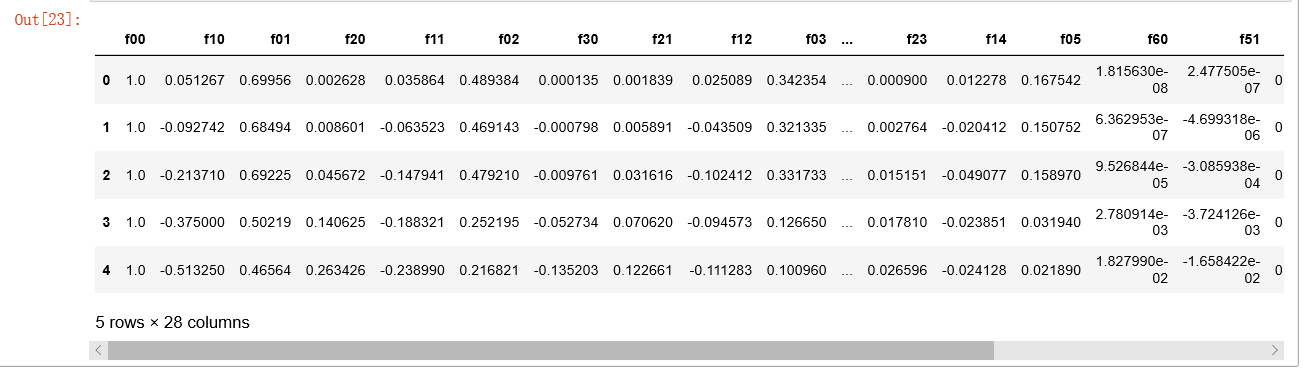
经过映射,我们将有两个特征的向量转化成了一个28维的向量。
在这个高维特征向量上训练的logistic回归分类器将会有一个更复杂的决策边界,当我们在二维图中绘制时,会出现非线性。
虽然特征映射允许我们构建一个更有表现力的分类器,但它也更容易过拟合。
在接下来的练习中,我们将实现正则化的logistic回归来拟合数据,并且可以看到正则化如何帮助解决过拟合的问题。
3.Regularized Cost function
正则化逻辑回归的代价函数如下:
\]
注意: 不惩罚第一项\(\theta_0\)
先获取特征,标签以及参数theta,确保维度良好:
# 这里因为做特征映射的时候已经添加了偏置项,所以不用手动添加了。
X = _data2.values
y = data2['Accepted'].values
theta = np.zeros(X.shape[1]) # X.shape[1]获取X的列数,这里theta是列向量
X.shape, y.shape, theta.shape
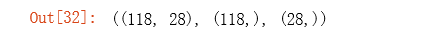
def sigmoid(z):
return 1 / (1 + np.exp(- z))
# 定义代价函数(能够返回代价函数值)
def cost(theta, X, y):
first = (-y) * np.log(sigmoid(X @ theta)) # 注意这里的 theta 是列向量
second = (1 - y)*np.log(1 - sigmoid(X @ theta))
return np.mean(first - second)
# 定义带正则项的代价函数
def costReg(theta, X, y, l=1):
# 不惩罚第一项
_theta = theta[1: ] #选取第二项以后的; _theta为27*1的向量;theta[1: ]是列向量
# theta@_theta:这个numpy一维数组的特殊用法,也就相当于求内积,也就是元素平方的和。
# @在numpy中表示矩阵相乘的意思,等价于np.dot()
reg = (l / (2 * len(X))) *( (_theta).T @ _theta) # _theta@_theta == inner product(点积,结果是一个数);这里用_theta@_theta 和(_theta).T @ _theta是一样的
return cost(theta, X, y) + reg
计算正则化代价函数的初始值:
# 计算正则化代价函数的初始值:
costReg(theta, X, y, l=1)

4.Regularized gradient
因为我们未对\({\theta }_{0}\)进行正则化,所以梯度下降算法将分两种情形:
\]
\]
# 定义计算梯度值(导数值)
def gradient(theta, X, y):
return (X.T @ (sigmoid(X @ theta) - y))/len(X)
# the gradient of the cost is a vector of the same length as θ where the jth element (for j = 0, 1, . . . , n)
# 定义正则化梯度值(导数值)
def gradientReg(theta, X, y, l=1):
reg = (l / len(X)) * theta
reg[0] = 0 # 不惩罚第一项
return gradient(theta, X, y) + reg
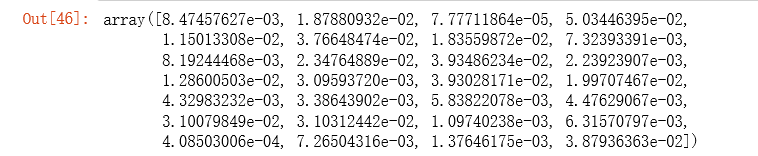
gradientReg(theta, X, y, 1)
5.Learning θ parameters
import scipy.optimize as opt
# 这里使用fimin_tnc方法来拟合
# func:优化的目标函数
# x0:初值
# fprime:提供优化函数func的梯度函数,不然优化函数func必须返回函数值和梯度,或者设置approx_grad=True
# args:元组,是传递给优化函数的参数
result2 = opt.fmin_tnc(func=costReg, x0=theta, fprime=gradientReg, args=(X, y, 1))
result2

计算经过高级优化算法之后正则化代价函数的值:
# result2[0] 是优化过后的参数值
costReg(result2[0], X, y, l=1)
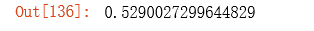
6.Evaluating logistic regression
def predict(theta, X):
probability = sigmoid(X @ theta)
return [1 if x >= 0.5 else 0 for x in probability] # return a list
final_theta = result2[0]
predictions = predict(final_theta, X)
correct = [1 if a==b else 0 for (a, b) in zip(predictions, y)]
accuracy = sum(correct) / len(correct)
accuracy
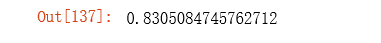
可以看到预测精度达到了83%。
7.Decision boundary
x = np.linspace(-1, 1.5, 250)
xx, yy = np.meshgrid(x, x)
z = feature_mapping(xx.ravel(), yy.ravel(), 6).values
z = z @ final_theta
z = z.reshape(xx.shape)
plot_data()
plt.contour(xx, yy, z, 0)
plt.ylim(-.8, 1.2)
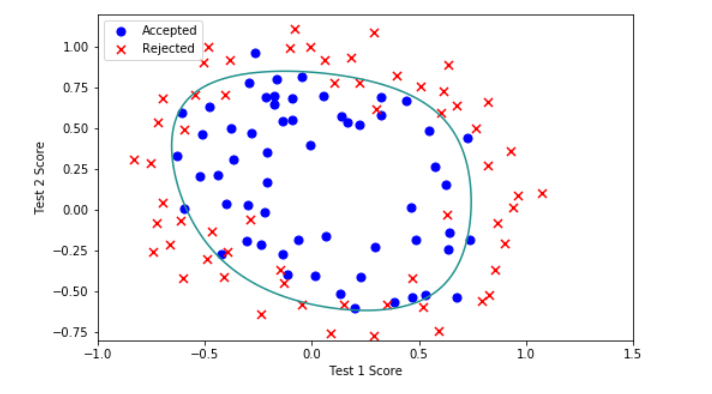
总结
当我们选取非常多的特征来拟合数据(本练习最终映射了28个特征)的时候,很容易出现过拟合的现象(即对训练集的数据拟合的非常好,但是泛化新样本的能力却不太好),这时候就需要进行正则化。\(\lambda\)是正则化参数,它的作用是可以更好的拟合数据集,保持参数尽量地小,从而保持假设函数模型相对简单,避免出现过拟合的现象。
\(\lambda\)值的选取也很重要,当\(\lambda\)过大时,容易出现欠拟合,偏差大的情况,当\(\lambda\)的值太小,容易出现过拟合,方差大的情况。
- \(\lambda=0\)
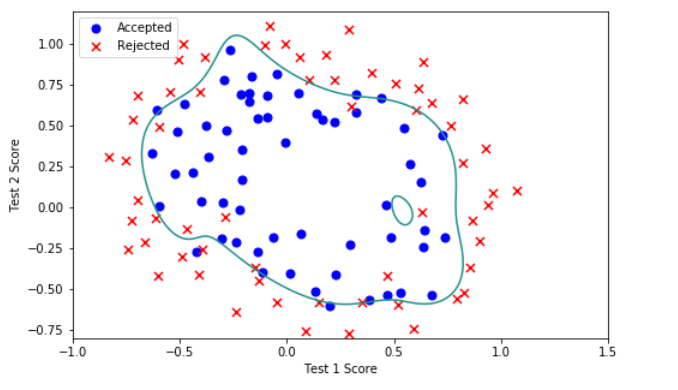
- \(\lambda=1\)
- \(\lambda=10\)

- \(\lambda=100\)

对比以上\(\lambda\)取0、1、10、100的情况,某种程度上说,\(\lambda=1\)是比较合适的。所以正则化中\(\lambda\)值的选取非常重要。
参考资料
Scipy优化算法--scipy.optimize.fmin_tnc()/minimize()
编程作业2.2:Regularized Logistic regression的更多相关文章
- 编程作业2.1:Logistic regression
题目 在这部分的练习中,你将建立一个逻辑回归模型来预测一个学生是否能进入大学.假设你是一所大学的行政管理人员,你想根据两门考试的结果,来决定每个申请人是否被录取.你有以前申请人的历史数据,可以将其用作 ...
- machine learning(15) --Regularization:Regularized logistic regression
Regularization:Regularized logistic regression without regularization 当features很多时会出现overfitting现象,图 ...
- matlab(7) Regularized logistic regression : mapFeature(将feature增多) and costFunctionReg
Regularized logistic regression : mapFeature(将feature增多) and costFunctionReg ex2_reg.m文件中的部分内容 %% == ...
- matlab(6) Regularized logistic regression : plot data(画样本图)
Regularized logistic regression : plot data(画样本图) ex2data2.txt 0.051267,0.69956,1-0.092742,0.68494, ...
- Regularized logistic regression
要解决的问题是,给出了具有2个特征的一堆训练数据集,从该数据的分布可以看出它们并不是非常线性可分的,因此很有必要用更高阶的特征来模拟.例如本程序中个就用到了特征值的6次方来求解. Data To be ...
- matlab(8) Regularized logistic regression : 不同的λ(0,1,10,100)值对regularization的影响,对应不同的decision boundary\ 预测新的值和计算模型的精度predict.m
不同的λ(0,1,10,100)值对regularization的影响\ 预测新的值和计算模型的精度 %% ============= Part 2: Regularization and Accur ...
- 吴恩达机器学习笔记22-正则化逻辑回归模型(Regularized Logistic Regression)
针对逻辑回归问题,我们在之前的课程已经学习过两种优化算法:我们首先学习了使用梯度下降法来优化代价函数
- Andrew Ng机器学习编程作业:Logistic Regression
编程作业文件: machine-learning-ex2 1. Logistic Regression (逻辑回归) 有之前学生的数据,建立逻辑回归模型预测,根据两次考试结果预测一个学生是否有资格被大 ...
- week3编程作业: Logistic Regression中一些难点的解读
%% ============ Part : Compute Cost and Gradient ============ % In this part of the exercise, you wi ...
随机推荐
- 微信小程序如何刷新当前界面
在微信小程序开发的过程中,在一个页面中对数据操作之后我们大多数时间都需要刷新一下当前界面以把操作之后的结果显示出来,但是如何在执行操作后进行本页面的刷新就成了一个问题很大但是很需要的操作.下面介绍一下 ...
- 九十四、SAP中ALV事件之八,显示功能按钮栏
一.我们把其他代码都注释掉,直接写一行调用 SET PF-STATUS 'TIANPAN_TOOLS'. 二.运行程序,会看到我们上一篇所添加的相关功能栏图标, 三.点击不同图标,会按程序代码,有不同 ...
- 修改ssh主机名
三台机器的配置相似,以zk1为例 1.修改hostname vi /etc/hostname zk1 2.修改hosts文件 vi /etc/hosts 10.45.48.233 zk1 10.45. ...
- Maven的安装和创建项目的过程
一.下载Maven包和配置环境变量 1.将下载好的maven包放到一个目录中:目录中不能有汉字和空格 2.配置环境变量 3.配置path路径 二.配置阿里云私服 1.找到setting目录,配置下载j ...
- Linux学习《第二章命令》本章小结
经过这一章的学习,了解了常用的命令.这是学习Linux系统最最基础的工作,必须努力掌握,个人觉得,并不是这个章节学习结束之后,命令的学习就结束了,而是刚刚开始,今后在每个知识点学习过程中,都会 学习到 ...
- 【LeetCode】最长公共子序列
[问题]给定两个字符串A和B,长度分别为m和n,要求找出它们最长的公共子串,并返回其长度.例如:A = "HelloWorld"B = "loop"则A与B的最 ...
- ABP框架没有httpPost,httpget,httpput特性
需要引用一下组件, Microsoft.AspNetCore.Mvc
- Airflow 使用 Celery 时,如何添加 Celery 配置
背景 前段时间我选用了 Airflow 对 wms 进行数据归档,在运行一段时间后,经常发现会报以下错误: [-- ::,: WARNING/ForkPoolWorker-] Failed opera ...
- C语言编程实现SYN-Flood(Dos)攻击
## 实验环境为了方便,直接在win10 VS2013Ultimate实现(攻击机),靶机为同一局域网的另外一台主机或外网服务器. ## 实验依赖基于WinPcap实现,需要安装WinPcap4. ...
- 春节前“摸鱼”指南——SCA命令行工具助你快速构建FaaS服务
春节将至,身在公司的你是不是已经完全丧失了工作的斗志? 但俗话说得好:"只要心中有沙,办公室也能是马尔代夫." 职场人如何才能做到最大效能地带薪"摸鱼",成为了 ...