Sql_索引分析
「索引就像书的目录, 通过书的目录就准确的定位到了书籍具体的内容」,这句话描述的非常正确, 但就像脱了裤子放屁,说了跟没说一样,通过目录查找书的内容自然是要比一页一页的翻书找来的快,同样使用的索引的人难到会不知道,通过索引定位到数据比直接一条一条的查询来的快,不然他们为什么要建索引。
想要理解索引原理必须清楚一种数据结构「平衡树」(非二叉),也就是b tree或者 b+ tree,重要的事情说三遍:“平衡树,平衡树,平衡树”。当然, 有的数据库也使用哈希桶作用索引的数据结构 , 然而, 主流的RDBMS都是把平衡树当做数据表默认的索引数据结构的。
我们平时建表的时候都会为表加上主键, 在某些关系数据库中, 如果建表时不指定主键,数据库会拒绝建表的语句执行。 事实上, 一个加了主键的表,并不能被称之为「表」。一个没加主键的表,它的数据无序的放置在磁盘存储器上,一行一行的排列的很整齐, 跟我认知中的「表」很接近。如果给表上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结构,也就是上面说的「平衡树」结构,换句话说,就是整个表就变成了一个索引。没错, 再说一遍, 整个表变成了一个索引,也就是所谓的「聚集索引」。 这就是为什么一个表只能有一个主键, 一个表只能有一个「聚集索引」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置。

上图就是带有主键的表(聚集索引)的结构图。图画的不是很好, 将就着看。其中树的所有结点(底部除外)的数据都是由主键字段中的数据构成,也就是通常我们指定主键的id字段。最下面部分是真正表中的数据。 假如我们执行一个SQL语句:
select * from table where id = 1256;
首先根据索引定位到1256这个值所在的叶结点,然后再通过叶结点取到id等于1256的数据行。 这里不讲解平衡树的运行细节, 但是从上图能看出,树一共有三层, 从根节点至叶节点只需要经过三次查找就能得到结果。如下图
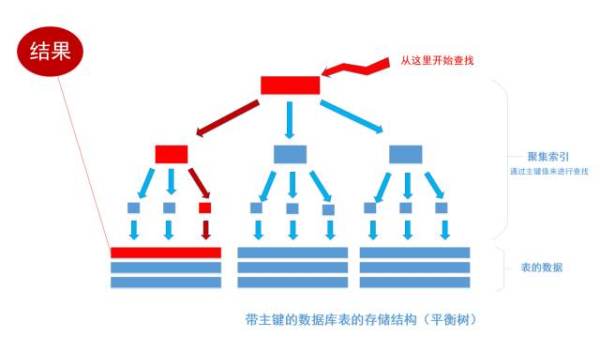
假如一张表有一亿条数据 ,需要查找其中某一条数据,按照常规逻辑, 一条一条的去匹配的话, 最坏的情况下需要匹配一亿次才能得到结果,用大O标记法就是O(n)最坏时间复杂度,这是无法接受的,而且这一亿条数据显然不能一次性读入内存供程序使用, 因此, 这一亿次匹配在不经缓存优化的情况下就是一亿次IO开销,以现在磁盘的IO能力和CPU的运算能力, 有可能需要几个月才能得出结果 。如果把这张表转换成平衡树结构(一棵非常茂盛和节点非常多的树),假设这棵树有10层,那么只需要10次IO开销就能查找到所需要的数据, 速度以指数级别提升,用大O标记法就是O(log n),n是记录总树,底数是树的分叉数,结果就是树的层次数。换言之,查找次数是以树的分叉数为底,记录总数的对数,用公式来表示就是

用程序来表示就是Math.Log(100000000,10),100000000是记录数,10是树的分叉数(真实环境下分叉数远不止10), 结果就是查找次数,这里的结果从亿降到了个位数。因此,利用索引会使数据库查询有惊人的性能提升。
然而, 事物都是有两面的, 索引能让数据库查询数据的速度上升, 而使写入数据的速度下降,原因很简单的, 因为平衡树这个结构必须一直维持在一个正确的状态, 增删改数据都会改变平衡树各节点中的索引数据内容,破坏树结构, 因此,在每次数据改变时, DBMS必须去重新梳理树(索引)的结构以确保它的正确,这会带来不小的性能开销,也就是为什么索引会给查询以外的操作带来副作用的原因。
讲完聚集索引 , 接下来聊一下非聚集索引, 也就是我们平时经常提起和使用的常规索引。
非聚集索引和聚集索引一样, 同样是采用平衡树作为索引的数据结构。索引树结构中各节点的值来自于表中的索引字段, 假如给user表的name字段加上索引 , 那么索引就是由name字段中的值构成,在数据改变时, DBMS需要一直维护索引结构的正确性。如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。 如下图

每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。
非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据,如下图

不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径。
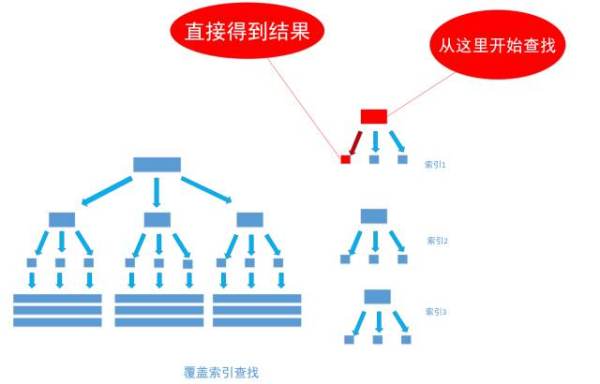
然而, 有一种例外可以不使用聚集索引就能查询出所需要的数据, 这种非主流的方法 称之为「覆盖索引」查询, 也就是平时所说的复合索引或者多字段索引查询。 文章上面的内容已经指出, 当为字段建立索引以后, 字段中的内容会被同步到索引之中, 如果为一个索引指定两个字段, 那么这个两个字段的内容都会被同步至索引之中。
先看下面这个SQL语句
//建立索引
create index index_birthday on user_info(birthday);
//查询生日在1991年11月1日出生用户的用户名
select user_name from user_info where birthday = '1991-11-1'
这句SQL语句的执行过程如下
首先,通过非聚集索引index_birthday查找birthday等于1991-11-1的所有记录的主键ID值
然后,通过得到的主键ID值执行聚集索引查找,找到主键ID值对就的真实数据(数据行)存储的位置
最后, 从得到的真实数据中取得user_name字段的值返回, 也就是取得最终的结果
我们把birthday字段上的索引改成双字段的覆盖索引
create index index_birthday_and_user_name on user_info(birthday, user_name);
这句SQL语句的执行过程就会变为
通过非聚集索引index_birthday_and_user_name查找birthday等于1991-11-1的叶节点的内容,然而, 叶节点中除了有user_name表主键ID的值以外, user_name字段的值也在里面, 因此不需要通过主键ID值的查找数据行的真实所在, 直接取得叶节点中user_name的值返回即可。 通过这种覆盖索引直接查找的方式, 可以省略不使用覆盖索引查找的后面两个步骤, 大大的提高了查询性能,如下图
Sql_索引分析的更多相关文章
- MySQL索引分析
索引的出现解决数据量上升导致查询越来越慢的问题,优化数据的查询,提高查询的速度. 索引 定义: 通过各种数据结构实现的值到行位置的映射.快速定位与访问特定的数据. 作用: 提高访问速度 实现主键.唯一 ...
- Elasticsearch的索引模块(正排索引、倒排索引、索引分析模块Analyzer、索引和搜索、停用词、中文分词器)
正向索引的结构如下: “文档1”的ID > 单词1:出现次数,出现位置列表:单词2:出现次数,出现位置列表:…………. “文档2”的ID > 此文档出现的关键词列表. 一般是通过key,去 ...
- MySQL 索引分析
MySQL复合唯一索引分析 关于复合唯一索引(unique key 或 unique index),网上搜索不少人说:"这种索引起到的关键作用是约束,查询时性能上没有得到提高或者查询时根本没 ...
- B+Tree和MySQL索引分析
首先区分两组概念: 稠密索引,稀疏索引: 聚簇索引,非聚簇索引: btree和mysql的分析: 参见 http://blog.csdn.net/hguisu/article/details/7786 ...
- sphinx索引分析——文件格式和字典是double array trie 检索树,索引存储 – 多路归并排序,文档id压缩 – Variable Byte Coding
1 概述 这是基于开源的sphinx全文检索引擎的架构代码分析,本篇主要描述index索引服务的分析.当前分析的版本 sphinx-2.0.4 2 index 功能 3 文件表 4 索引文件结构 4. ...
- SQL Server 2012 列存储索引分析(翻译)
一.概述 列存储索引是SQL Server 2012中为提高数据查询的性能而引入的一个新特性,顾名思义,数据以列的方式存储在页中,不同于聚集索引.非聚集索引及堆表等以行为单位的方式存储.因为它并不要求 ...
- PLSQL_性能优化系列12_Oracle Index Anaylsis索引分析
2014-10-04 Created By BaoXinjian
- Mysql索引分析:适合建索引?不适合建索引?【转】
数据库建立索引常用的规则如下: 1.表的主键.外键必须有索引: 2.数据量超过300的表应该有索引: 3.经常与其他表进行连接的表,在连接字段上应该建立索引: 4.经常出现在Where子句中的字段,特 ...
- MySQL高级知识(五)——索引分析
前言:前面已经学习了explain(执行计划)的相关知识,这里利用explain对索引进行优化分析. 0.准备 首先创建三张表:tb_emp(职工表).tb_dept(部门表)和tb_desc(描述表 ...
随机推荐
- csdn中使用git的一些注意事项---免得走弯路
csdn中使用git必须的条件(windows系统下): 1.本机当前登录用户文件夹下必须有.ssh隐藏文件,并且这个文件中必须有用git bash中用命令生成的密钥文件:id_rsa id_rsa ...
- tkinter中lable标签控件(二)
lable控件 对于tkinter来说,学起来很简单,只要设置好相应的参数即可出结果,所以不用刻意去记住这些参数.学习一遍后理解每个参数的作用是什么即可. 当下次用到的时候来笔记上看一下就行. 内容很 ...
- windows防火墙安全设置指定ip访问指定端口
场景摘要: 1.我有三台腾讯云服务器 2.我日常办公网络的ip换了 3.我在腾讯云上面改了安全规则,也不能访问我A服务器的21,1433等端口 4.开始我以为是办公网络的安全设置问题 5.我进B服务器 ...
- 个人博客作业Week3(微软必应词典客户端的案例分析)
软件缺陷常常又被叫做Bug,即为计算机软件或程序中存在的某种破坏正常运行能力的问题.错误,或者隐藏的功能缺陷.缺陷的存在会导致软件产品在某种程度上不能满足用户的需要.IEEE729-1983对缺陷有一 ...
- vue-cli打包到部署到nginx服务器
最近公司把云平台产品用vue 前后端分离的框架来写,前面大部分开发都比较顺利,后面打包部署出了bug 现在记录下自己遇到的哪些坑 1,我直接npm run build 打包出来,打开dist目录下面的 ...
- 机器C盘临时区
系统的临时区里:C:\Documents and Settings\Administrator(用户名)\Local Settings\Temporary Internet Files 这是临时文件夹 ...
- UVA127-"Accordian" Patience(模拟)
Problem UVA127-"Accordian" Patience Accept:3260 Submit:16060 Time Limit: 3000 mSec Proble ...
- 【转】BASE64编码简介
BASE64是一种编码方式,通常用于把二进制数据编码为可写的字符形式的数据. 这是一种可逆的编码方式. 编码后的数据是一个字符串,其中包含的字符为:A-Z.a-z.0-9.+./ 共64个字符:26 ...
- 转载 [ZooKeeper.net] 3 ZooKeeper的分布式锁
[ZooKeeper.net] 3 ZooKeeper的分布式锁 基于ZooKeeper的分布式锁 源码分享:http://pan.baidu.com/s/1miQCDKk ZooKeeper ...
- Java中static、final、static final的区别【转】
说明:不一定准确,但是最快理解. final: final可以修饰:属性,方法,类,局部变量(方法中的变量) final修饰的属性的初始化可以在编译期,也可以在运行期,初始化后不能被改变. final ...