scrapy——7 scrapy-redis分布式爬虫,用药助手实战,Boss直聘实战,阿布云代理设置
scrapy——7
什么是scrapy-redis
怎么安装scrapy-redis
scrapy-redis常用配置文件
scrapy-redis键名介绍
实战-利用scrapy-redis分布式爬取用药助手网站
实战-利用scrapy-redis分布式爬取Boss直聘网站
如何使用代理
什么是scrapy-redis-->简介
scrapy-redis是scrapy框架基于redis数据库的组件,用于scrapy项目分布式开发和部署
特征:
分布式爬取
你可以启动多个spider工程,相互之间共享单个redis的request队列。最适合广泛的多个域名网站的内容爬取。
分布式数据处理
爬取到的scrapy的item数据可以推入到redis队列中,这意味着你可以根据需求启动尽可能多的处理器程序来共享item队列,进行item数据持久化处理。
scrapy即插即用组件
Schedule调度器 + Duplication复制过滤器,itemPipleline,基本spider
什么是scrapy_redis?-->框架
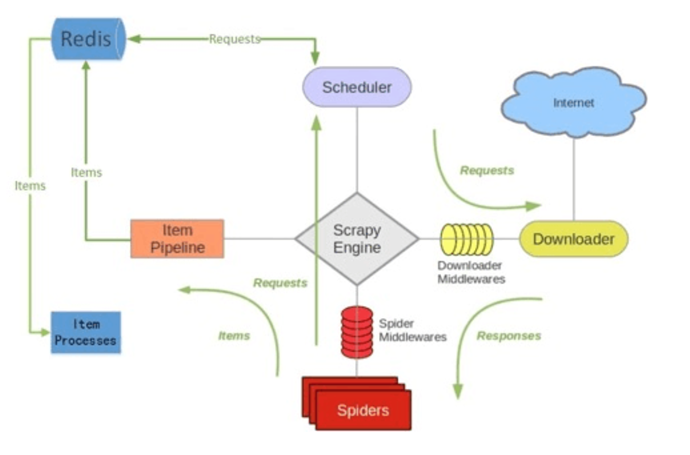
1. 首先Slaver端从Master端(装有redis的系统)拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
2. Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据
Scrapy_Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy_Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
怎样安装scrapy-redis
通过pip安装: pip install scrapy-redis
依赖环境:
- python
- redis
- scrapy
官方文档:https://scrapy-redis.readthedocs.io/en/stable/
源码位置:https://github.com/rmax/scrapy-redis
博客:https://www.cnblogs.com/kylinlin/p/5198233.html
怎样使用scrapy-redis?-->常用配置文件
- (必须)使用了scrapy_redis的去重组件,在redis数据库里做去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
- (必须)使用了scrapy_redis的调度器,在redis里分配请求
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
- (可选)在redis中保持scrapy-redis用到的各个队列,从而True允许暂停和暂停后和恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True
- (必须)通过配置RedisPipline将item写入key为spider.name:items的redis的list中,供后面的分布式处理item;这个已经由scrapy-redis实现,不需要我们写代码,直接使用即可
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 100
} - (必须)指定redis数据库的连接参数
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
怎样使用scrapy-redis?-->redis键名介绍
- “项目名: start_urls”
List 类型,用于获取spider启动时爬取的第一个url
- “项目名:dupefilter”
set类型,用于爬虫访问的URL去重
内容是 40个字符的 url 的hash字符串 - “项目名:requests”
zset类型,用于scheduler调度处理 requests
内容是 request 对象的序列化 字符串 - “项目名:items”
list 类型,保存爬虫获取到的数据item
内容是 json 字符串
实战-利用scrapy-redis分布式写爬虫项目
实战·1 爬取用药助手的所有药品简单信息,链接 http://drugs.dxy.cn/index.htm
首先分析网站,我们发现所有的药理分类用的都是网站内的锚点,获取不到url,所有我们选择获取药品类型进行爬取,查看源代码

不难看出,所有的h3标签就是我们需要的药品分类url,第一步获取所有的药品分类物品我们就完成了;
随便点一个进去,我们可以看到红线框中的就是我们需要爬取的数据
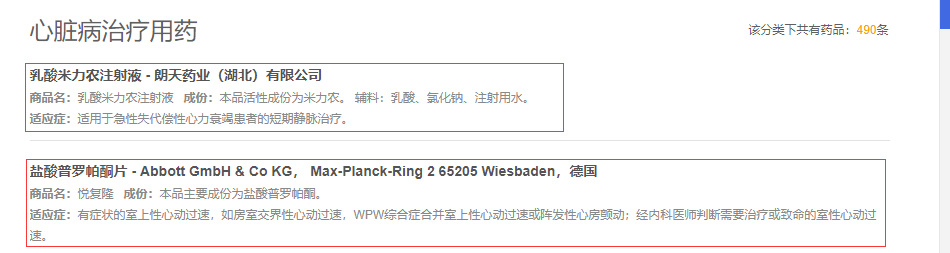
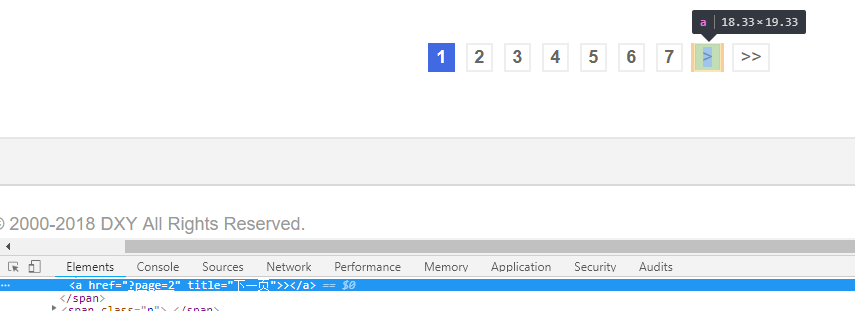
以及翻页
- 主要的流程分析完毕以后,再用scrapy shell进行测试,这里就不讲解测试的部分了,直接新建项目
- 我们编写scrapy-redis分布式爬取的时候,编写的逻辑可以先是单纯的scrapy框架,等程序逻辑没有问题以后,再用分布式(导入库,更换父类,定义redis_key,在更改setting)
- drugs\drugs\items.py items中,定义我们的数据,这里我们定义 药品名,生产公司,成分,适应症四个数据
import scrapy class DrugsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field() drugs_name = scrapy.Field() company = scrapy.Field() composition = scrapy.Field() indications = scrapy.Field() - 为了避免程序出错,先设置部分setting数据
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 3
- drugs\drugs\spiders\drugs_spider.py 编写主要逻辑代码
# -*- coding: utf-8 -*-
import scrapy
import re from ..items import DrugsItem class DrugsSpiderSpider(RedisSpider):
name = 'drugs_spider'
start_urls = ['http://drugs.dxy.cn/index.htm'] def parse(self, response):
# 匹配每一种药品类型
category_urls = response.xpath('//ul[@class="ullist clearfix"]/li/h3/a/@href').extract() for category_url in category_urls:
yield scrapy.Request(url=category_url, callback=self.detail_parse) def detail_parse(self, response):
try:
# 翻页
next_url = response.xpath('//a[@title="下一页"]/@href').extract_first()
yield scrapy.Request(url=response.url+next_url, callback=self.detail_parse)
# 药品名
drugs_name = re.findall(r'''<b>商品名:</b>(.*?) ''', response.text, re.S)
# 公司
company = response.xpath('//div[@class="fl"]/h3/a/text()').extract()
company = [i.strip().replace('\t\t\t\t\t\t\t\t\t\t\t', '') for i in company]
# 成分
composition = [i.replace('\n\n', '') for i in (re.findall(r'''<b>成份:</b>(.*?)<br/>''', response.text, re.S))]
# 适应症
indications = re.findall(r'''<b>适应症:</b>(.*?)\s*</p>''', response.text, re.S)
indications = [i.replace('\n\n', '') for i in indications] for drugs_name, company, composition, indications in zip(drugs_name, company, composition, indications):
items = DrugsItem()
items['drugs_name'] = drugs_name
items['company'] = company
items['composition'] = composition
items['indications'] = indications yield items
except:
pass - 如果代码完成并无逻辑和编写错误的话,现在就开始就之前的代码进行分布式操作
- drugs\drugs\settings.py 设置setting分布式的必须参数
ITEM_PIPELINES = {
'drugs.pipelines.DrugsPipeline': 300, # 这是本身就有的
'scrapy_redis.pipelines.RedisPipeline': 100 # 这是需要添加进去的
} DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # scrapy_redis的去重组件
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # scrapy_redis的调度器
SCHEDULER_PERSIST = True # 不清理redis queues
# redis数据库的连接参数(根据个人电脑安装情况定义)
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379 - drugs\drugs\spiders\drugs_spider.py 在之前的spider代码中,导入 from scrapy_redis.spiders import RedisSpider
- 将DrugsSpiderSpider类改成继承RedisSpider,注释掉start_urls,定义redis_key = 'drugs_start:urls'
- redis_key是固定词,后面的是在redis数据库中需要lpush的键值,如图,其他的不用改
- 接下来要在pipeline中保存数据,将数据保存在MongoDB中 drugs\drugs\pipelines.py
import pymongo class DrugsPipeline(object): def open_spider(self, spider):
self.conn = pymongo.MongoClient(host='127.0.0.1', port=27017)
self.db = self.conn['tanzhou_homework']
self.connection = self.db['drugs_helper'] def process_item(self, item, spider):
self.connection.insert(dict(item))
return item def close_spider(self,spider):
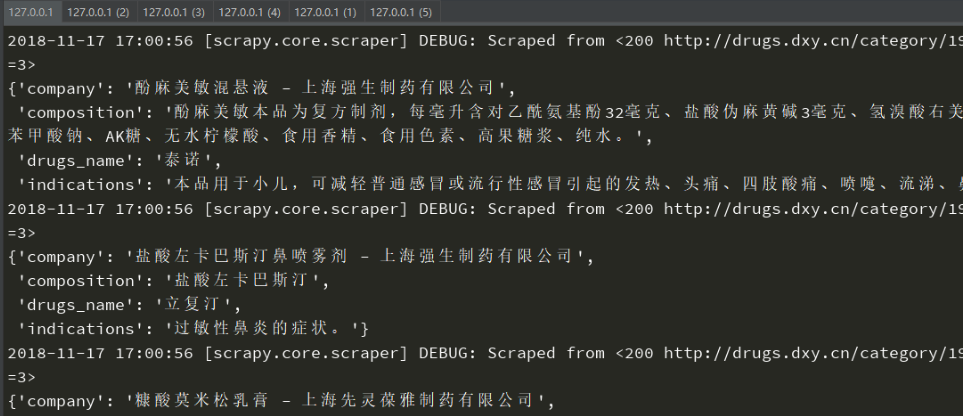
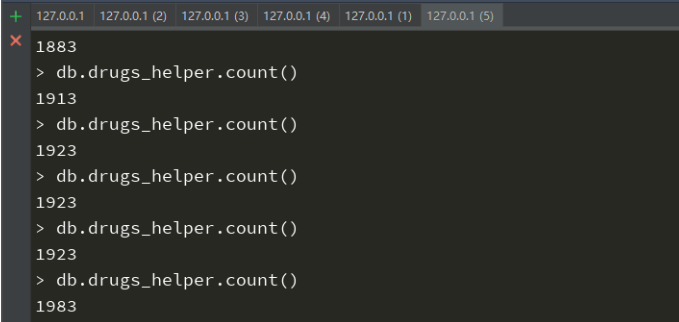
pass - 然后分布式爬虫就已经完成了,使用scrapy crawl drugs_spider 运行,控制台会阻塞,然后到redis中,使用lpush drugs_start:url http://drugs.dxy.cn/index.htm把需要爬取的链接传入进去,之前阻塞的控制台就会继续运行了,爬虫也就开始了。这样的话,就可以控制台多开了如图0,2,3,4在同时爬取数据,1是redis,5是MondoDB
实战2 爬取Boss直聘
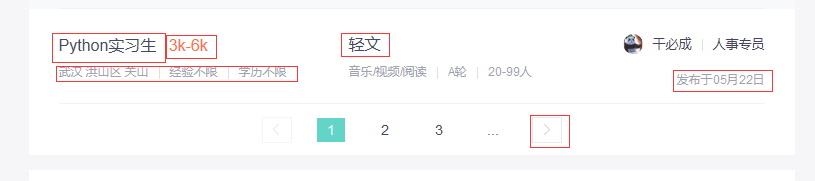
关于武汉,pthon的工作信息 https://www.zhipin.com/c101200100/?query=python&
- 分析网站,需要爬取的数据有 岗位,工资,信息,公司,职位描述,发布时间,还有一个翻页标签

- 思路比上一个要简单一些,这里简单讲解一下
- items设置数据
import scrapy class BossItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
job_title = scrapy.Field() wage = scrapy.Field() infomation = scrapy.Field() company = scrapy.Field() public_time = scrapy.Field() requirements = scrapy.Field() - setting
# 爬虫协议
ROBOTSTXT_OBEY = False
# 下载延迟
DOWNLOAD_DELAY = 5
# 请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'cookie': '_uab_collina=154233017050308004748422; lastCity=101010100; JSESSIONID=""; ...........,
}
# 管道
ITEM_PIPELINES = {
'boss.pipelines.BossPipeline': 200,
'scrapy_redis.pipelines.RedisPipeline': 100
}
# redis设置
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379 - boss_spider.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy_redis.spiders import RedisSpider
from ..items import BossItem class BossSpiderSpider(RedisSpider):
name = 'boss_spider'
# start_urls = ['https://www.zhipin.com/c101200100/?query=python&']
redis_key = 'zp_start:urls' def parse(self, response):
# 翻页
next_url = response.xpath('//a[@class="next"]/@href').extract_first()
yield scrapy.Request(url='https://www.zhipin.com'+next_url) job_title = response.xpath('//div[@class="job-title"]/text()').extract()
wage = response.xpath('//span[@class="red"]/text()').extract()
info = response.xpath('//div[@class="info-primary"]/p/text()').extract()
infomations = [info[i:i+3] for i in range(0, len(info), 3)]
infomation = [''.join(i) for i in infomations]
companys = response.xpath('//div[@class="company-text"]/h3/a/text()').extract()
company = [company for company in companys if '\n' not in company]
public_time = response.xpath('//div[@class="info-publis"]/p/text()').extract()
detail_urls = response.xpath('//div[@class="info-primary"]//h3/a/@href').extract()
detail_urls = ['https://www.zhipin.com' + detail_url for detail_url in detail_urls] for url, job_title, wage, infomation, company, public_time in zip(detail_urls, job_title, wage, infomation, company, public_time):
item = BossItem()
item['job_title'] = job_title,
item['wage'] = wage,
item['infomation'] = infomation,
item['company'] = company,
item['public_time'] = public_time yield scrapy.Request(url=url, callback=self.detail_parse, meta={'item':item}) def detail_parse(self, response):
item = response.meta.get('item')
requirements = response.xpath('string(//div[@class="text"])').extract_first()
print(requirements.strip())
item['requirements'] = requirements yield item - 运行和上面方法一样,就不多做描述,这里还要讲的东西就是,redis运行以后会有这三个数据,详情请参考前面提到的键名介绍
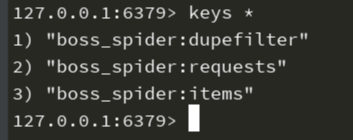
运行结果展示
如何使用代理
在前面的Boss直聘网站数据爬取中,有没有注意到setting中设置了延时为5秒,这是因为Boss直聘反爬还是很有严重的,如果你的短时间内访问的次数过多的话,或者爬取速度过快的话,ip会被封掉,这个时候,我们就需要接入代理了,使用代理爬取数据的话,就不用担心这个问题了。
网上也有有些免费的代理供游客使用,但是一般能用的都不多,而且也是各种不好用,在这里推荐使布云购买代理使用,经济实惠质量高(绝非广告,只是个人喜好),你也可以选择别的代理产品,例如快代理什么的。
在网站快代理中,有许多免费的ip代理,如图

如果可以用的话,在scrapy中的middlewares.py中,新添上代码,
class process_ProxiesMiddlewares(object):
def process_request(self, request, spider):
# 知道ip和端口的免费代理
proxies = 'http://000.00.00.00:0000'
request.meta['proxy'] = proxies
def process_response(self, request, response, spider):
# 返回数据的处理
return .....
再在setting中,添加如下代码就可以使用了
DOWNLOADER_MIDDLEWARES = {'boss.middlewares.process_ProxiesMiddlewares': 543 # 添加的
}
如果我们选择使用付费的代理,就需要使用别人的API接入,比如之前说到的阿布云代理,scrapy的接入方法如下
#! -*- encoding:utf-8 -*-
import base64
# 代理服务器
proxyServer = "http://http-dyn.abuyun.com:9020"
# 代理隧道验证信息
proxyUser = "H01234567890123D"
proxyPass = ""
# for Python2
proxyAuth = "Basic " + base64.b64encode(proxyUser + ":" + proxyPass)
# for Python3
#proxyAuth = "Basic " + base64.urlsafe_b64encode(bytes((proxyUser + ":" + proxyPass), "ascii")).decode("utf8")
class ProxyMiddleware(object):
def process_request(self, request, spider):
request.meta["proxy"] = proxyServer
request.headers["Proxy-Authorization"] = proxyAuth
requests的接入方法
#! -*- encoding:utf-8 -*-
import requests
# 要访问的目标页面
targetUrl = "http://test.abuyun.com"
# 代理服务器
proxyHost = "http-dyn.abuyun.com"
proxyPort = ""
# 代理隧道验证信息
proxyUser = "H01234567890123D"
proxyPass = ""
proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host" : proxyHost,
"port" : proxyPort,
"user" : proxyUser,
"pass" : proxyPass,
}
proxies = {
"http" : proxyMeta,
"https" : proxyMeta,
}
resp = requests.get(targetUrl, proxies=proxies)
print resp.status_code
print resp.text
还有别的方法不在此叙述,详情可以参考链接
然后这里主要讲解一下scrapy的使用方法
import base64
class ProxyMiddleware(object):
# 代理服务器
proxyServer = "http://http-dyn.abuyun.com:9020" # 代理隧道验证信息 这里填入你购买的验证信息
proxyUser = "H01234567890123D"
proxyPass = "" proxyAuth = "Basic " + base64.urlsafe_b64encode(bytes((proxyUser + ":" + proxyPass), "ascii")).decode("utf8") def process_request(self, request, spider):
request.meta["proxy"] = self.proxyServer
request.headers["Proxy-Authorization"] = self.proxyAuth def process_response(self, request, response, spider):
# 返回数据的处理
if response.status == 200:
return response
# 不成功重新请求
return request
setting设置对应的类
DOWNLOADER_MIDDLEWARES = {
'boss.middlewares.process_ProxiesMiddlewares': 543 # 添加的
}
如此,设置了IP代理的爬虫程序就不怕被封IP了
scrapy——7 scrapy-redis分布式爬虫,用药助手实战,Boss直聘实战,阿布云代理设置的更多相关文章
- 爬虫系列---scrapy post请求、框架组件和下载中间件+boss直聘爬取
一 Post 请求 在爬虫文件中重写父类的start_requests(self)方法 父类方法源码(Request): def start_requests(self): for url in se ...
- Python爬虫——Scrapy整合Selenium案例分析(BOSS直聘)
概述 本文主要介绍scrapy架构图.组建.工作流程,以及结合selenium boss直聘爬虫案例分析 架构图 组件 Scrapy 引擎(Engine) 引擎负责控制数据流在系统中所有组件中流动,并 ...
- Scrapy 爬取BOSS直聘关于Python招聘岗位
年前的时候想看下招聘Python的岗位有多少,当时考虑目前比较流行的招聘网站就属于boss直聘,所以使用Scrapy来爬取下boss直聘的Python岗位. 1.首先我们创建一个Scrapy 工程 s ...
- Python的scrapy之爬取boss直聘网站
在我们的项目中,单单分析一个51job网站的工作职位可能爬取结果不太理想,所以我又爬取了boss直聘网的工作,不过boss直聘的网站一次只能展示300个职位,所以我们一次也只能爬取300个职位. jo ...
- Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗
Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗 零.致谢 感谢BOSS直聘相对权威的招聘信息,使本人有了这次比较有意思的研究之旅. 由于爬虫持续爬取 www.zhipin.com 网 ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
- 【Python3爬虫】爬取美女图新姿势--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- 【Python3爬虫】学习分布式爬虫第一步--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
随机推荐
- win7下远程登录ubuntu mysql
网络上找了很久的一个办法,不然老是远程访问不了linux mysql. 原先一直用root登录,进不了,新建一个root1倒是可以了. 安装好mysql后,按以下步骤: 1.将vim /etc/mys ...
- cmd 命令操纵文件管理器、创建(删除)多级文件夹
命令行打开文件夹窗口的六种方法 1. 使用 start 命令 # 打开指定文件夹 > start 路径 # 打开当前文件夹 > start . # 打开含空格文件夹 > start ...
- 【POJ 1995】 Raising Modulo Numbers
[题目链接] http://poj.org/problem?id=1995 [算法] 快速幂 [代码] #include <algorithm> #include <bitset&g ...
- [Swift通天遁地]七、数据与安全-(4)CoreData数据的增、删、改、查
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★➤微信公众号:山青咏芝(shanqingyongzhi)➤博客园地址:山青咏芝(https://www.cnblogs. ...
- ORA-01012:not logged on的解决办法
conn / as sysdba 报错ORA-01012: not logged on 发生原因:关闭数据库是shutdown 后面没有接关闭参数中的任何一个. nomal ————- —-所有连接都 ...
- mysql数据库存储的引擎和数据类型
一.查看支持的存储引擎 SHOW ENGINES \G; 或者 SHOW VARIABLES LIKE 'have%'; 二.安装版mysql的默认引擎是InnoDB,免安装版默认引擎是MyISAM ...
- Log4J2的 PatternLayout
Log4J2 PatternLayout 参考 日志样例 : 2018-10-21 07:30:05,184 INFO - DeviceChannelServiceImpl.java:434[defa ...
- Web开发中跨域的几种解决方案
同domain(或ip),同端口,同协议视为同一个域,一个域内的脚本仅仅具有本域内的权限,可以理解为本域脚本只能读写本域内的资源,而无法访问其它域的资源.这种安全限制称为同源策略. 出于安全考虑,HT ...
- Leetcode0133--Clone Graph 克隆无向图
[转载请注明]:https://www.cnblogs.com/igoslly/p/9699791.html 一.题目 二.题目分析 给出一个无向图,其中保证每点之间均有连接,给出原图中的一个点 no ...
- CxImage实现9PNG
CxImage* ScaleImageBy9PNG(CxImage *pRawImage, int nDstWidth,int nDstHeight) { if(NULL == pRawImage) ...