SparkMLlib-----GMM算法
Gaussian Mixture Model(GMM)是一个很流行的聚类算法。它与K-Means的很像,但是K-Means的计算结果是算出每个数据点所属的簇,而GMM是计算出这些数据点分配到各个类别的概率。与K-Means对比K-Means存在一些缺点,比如K-Means的聚类结果易受样本中的一些极值点影响。此外GMM的计算结果由于是得出一个概率,得出一个概率包含的信息量要比简单的一个结果多,对于49%和51%的发生的事件如果仅仅使用简单的50%作为阈值来分为两个类别是非常危险的。
Gaussian Mixture Model,顾名思义,它是假设数据服从高斯混合分布,或者说是从多个高斯分布中生成出来的。每个GMM由K个高斯分布组成,每个高斯分布称为一个"Component",这些Component线性加在一起就组成了GMM的概率密度函数:
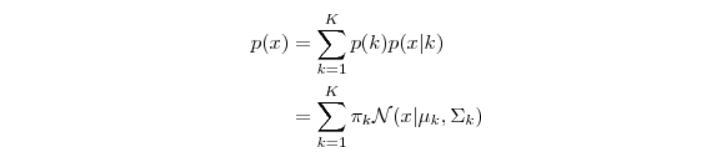
使用GMM做聚类的方法,我们先使用R等工具采样数据绘出数据点分布的图观察是否符合高斯混合分布,或者直接假设我们的数据是符合高斯混合分布的,之后根据数据推算出GMM的概率分布,对应的每个高斯分布就是每个类别,因为我们已知(假设)了概率密度分布的形式,要去求出其中参数,所以是一个参数估计的过程,我们要推导出每个混合成分的参数(均值向量mu,协方差矩阵sigma,权重weight),高斯混合模型在训练时使用了极大似然估计法,最大化以下对数似然函数:
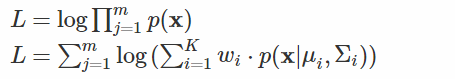
该式无法直接解析求解,因此采用了期望-最大化方法(Expectation-Maximization,EM)方法求解,具体步骤如下:
1.根据给定的K值,初始化K个多元高斯分布以及其权重;
2.根据贝叶斯定理,估计每个样本由每个成分生成的后验概率;(EM方法中的E步)
3.根据均值,协方差的定义以及2步求出的后验概率,更新均值向量、协方差矩阵和权重;(EM方法的M步)重复2~3步,直到似然函数增加值已小于收敛阈值,或达到最大迭代次数
接下来进行模型的训练与分析,我们采用了mllib包封装的GMM算法,具体代码如下
package com.xj.da.gmm import breeze.linalg.DenseVector
import breeze.numerics.sqrt
import org.apache.commons.math.stat.correlation.Covariance
import org.apache.spark.mllib.clustering.{GaussianMixture, GaussianMixtureModel}
import org.apache.spark.mllib.linalg
import org.apache.spark.mllib.linalg.distributed.RowMatrix
import org.apache.spark.mllib.linalg.{Matrices, Matrix, Vectors}
import org.apache.spark.mllib.stat.distribution.MultivariateGaussian
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable.ArrayBuffer /**
* author : kongcong
* number : 27
* date : 2017/7/19
*/
object GMMWithMultivariate {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
//.setMaster("local")
.setAppName("GMMWithMultivariate")
val sc = new SparkContext(conf) val rawData: RDD[String] = sc.textFile("hdfs://master:8020/home/kongc/data/query_result.csv")
//val rawData: RDD[String] = sc.textFile("data/query_result.csv")
println("count: " + rawData.count())
//println(rawData.count())
// col1, col2, status
val data: RDD[linalg.Vector] = rawData.map { line =>
val raw: Array[String] = line.split(",")
Vectors.dense(raw(0).toDouble, raw(1).toDouble, raw(4).toDouble)
}
// data.collect().take(10).foreach(println(_))
// col1, col2, status
val trainData: RDD[linalg.Vector] = rawData.map { line =>
val raw: Array[String] = line.split(",")
Vectors.dense(raw(0).toDouble, raw(1).toDouble)
}
// trainData.collect().take(10).foreach(println(_)) // 指定初始模型
// 0
val filter0: RDD[linalg.Vector] = data.filter(_.toArray(2) == 0)
println(filter0.count()) //23195
// 1
val filter1: RDD[linalg.Vector] = data.filter(_.toArray(2) == 1)
println(filter1.count()) //14602 val w1: Double = (filter0.count()/319377.toDouble)
val w2: Double = (filter1.count()/319377.toDouble)
println(s"w1 = $w1") // 均值
val m0x: Double = filter0.map(_.toArray(0)).mean()
val m0y: Double = filter0.map(_.toArray(1)).mean()
val m1x: Double = filter1.map(_.toArray(0)).mean()
val m1y: Double = filter1.map(_.toArray(1)).mean()
// 方差
val vx0: Double = filter0.map(_.toArray(0)).variance()
val vy0: Double = filter0.map(_.toArray(1)).variance()
val vx1: Double = filter1.map(_.toArray(0)).variance()
val vy1: Double = filter1.map(_.toArray(1)).variance() // 均值向量
val mu1: linalg.Vector = Vectors.dense(Array(m0x, m0y))
val mu2: linalg.Vector = Vectors.dense(Array(m1x, m1y))
println(s"mu1 : $mu1")
println(s"mu2 : $mu2") val array: RDD[Array[Double]] = rawData.map { line =>
val raw: Array[String] = line.split(",")
Array(raw(0).toDouble, raw(1).toDouble, raw(4).toDouble)
} val f0: RDD[Array[Double]] = array.filter(_(2) == 0)
val f1: RDD[Array[Double]] = array.filter(_(2) == 1)
println("f0.count:"+f0.count())
println("f1.count:"+f1.count()) // 0 x,y求协方差矩阵
val x0: RDD[Double] = f0.map(_(0))
val y0: RDD[Double] = f0.map(_(1))
//println(x0.collect().length == y0.collect().length)
// 1 x,y求协方差矩阵
val x1: RDD[Double] = f1.map(_(0))
val y1: RDD[Double] = f1.map(_(1))
val ma0: Array[Array[Double]] = Array(x0.collect(),y0.collect())
val ma1: Array[Array[Double]] = Array(x1.collect(),y1.collect()) val r0: RDD[Array[Double]] = sc.parallelize(ma0)
val r1: RDD[Array[Double]] = sc.parallelize(ma1) val rdd0: RDD[linalg.Vector] = r0.map(f => Vectors.dense(f))
val rdd1: RDD[linalg.Vector] = r1.map(f => Vectors.dense(f)) val RM0: RowMatrix = new RowMatrix(rdd0)
val RM1: RowMatrix = new RowMatrix(rdd1) // 计算协方差矩阵
//println(RM0.computeCovariance().numCols) /*val i: Double = DenseVector(1.0, 2.0, 3.0, 4.0) dot DenseVector(1.0, 1.0, 1.0, 1.0)
val c0yx: Double = i - m0x * m0y*/ val c0yx: Double = DenseVector(x0.collect()) dot DenseVector(y0.collect()) - m0x * m0y
val c1yx: Double = DenseVector(x1.collect()) dot DenseVector(y1.collect()) - m1x * m1y //cov(Vectors.dense(x0.collect()),Vectors.dense(y0.collect()))
val sigma1 = Matrices.dense(2, 2, Array(vx0, c0yx, c0yx, vy0))
val sigma2 = Matrices.dense(2, 2, Array(vx1, c1yx, c1yx, vy1))
val gmm1 = new MultivariateGaussian(mu1, sigma1)
val gmm2 = new MultivariateGaussian(mu2, sigma2) val gaussians = Array(gmm1, gmm2) // 构建一个GaussianMixtureModel需要两个参数 一个是权重数组 一个是组成混合高斯分布的每个高斯分布
val initModel = new GaussianMixtureModel(Array(w1, w2), gaussians) for (i <- 0 until initModel.k) {
println("weight=%f\nmu=%s\nsigma=\n%s\n" format
(initModel.weights(i), initModel.gaussians(i).mu, initModel.gaussians(i).sigma))
} val gaussianMixture = new GaussianMixture()
val mixtureModel = gaussianMixture
.setInitialModel(initModel)
.setK(2)
.setConvergenceTol(0.0001)
.run(trainData) val predict: RDD[Int] = mixtureModel.predict(trainData)
rawData.zip(predict).saveAsTextFile("hdfs://master:8020/home/kongc/data/out/gmm/predict2") for (i <- 0 until mixtureModel.k) {
println("weight=%f\nmu=%s\nsigma=\n%s\n" format
(mixtureModel.weights(i), mixtureModel.gaussians(i).mu, mixtureModel.gaussians(i).sigma))
} }
}
参考:http://blog.pluskid.org/?p=39
http://dblab.xmu.edu.cn/blog/1456/
SparkMLlib-----GMM算法的更多相关文章
- GMM算法k-means算法的比较
1.EM算法 GMM算法是EM算法族的一个具体例子. EM算法解决的问题是:要对数据进行聚类,假定数据服从杂合的几个概率分布,分布的具体参数未知,涉及到的随机变量有两组,其中一组可观测另一组不可观测. ...
- SparkMLlib分类算法之支持向量机
SparkMLlib分类算法之支持向量机 (一),概念 支持向量机(support vector machine)是一种分类算法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最 ...
- SparkMLlib回归算法之决策树
SparkMLlib回归算法之决策树 (一),决策树概念 1,决策树算法(ID3,C4.5 ,CART)之间的比较: 1,ID3算法在选择根节点和各内部节点中的分支属性时,采用信息增益作为评价标准.信 ...
- GMM算法的matlab程序
GMM算法的matlab程序 在“GMM算法的matlab程序(初步)”这篇文章中已经用matlab程序对iris数据库进行简单的实现,下面的程序最终的目的是求准确度. 作者:凯鲁嘎吉 - 博客园 h ...
- GMM算法的matlab程序(初步)
GMM算法的matlab程序 在https://www.cnblogs.com/kailugaji/p/9648508.html文章中已经介绍了GMM算法,现在用matlab程序实现它. 作者:凯鲁嘎 ...
- SparkMLlib分类算法之决策树学习
SparkMLlib分类算法之决策树学习 (一) 决策树的基本概念 决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风 ...
- SparkMLlib分类算法之逻辑回归算法
SparkMLlib分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/5169383 ...
- 机器学习——EM算法与GMM算法
目录 最大似然估计 K-means算法 EM算法 GMM算法(实际是高斯混合聚类) 中心思想:①极大似然估计 ②θ=f(θold) 此算法非常老,几乎不会问到,但思想很重要. EM的原理推导还是蛮复杂 ...
- Kmeans算法学习与SparkMlLib Kmeans算法尝试
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的方法,逐次更新各聚类中心的 ...
- EM算法和GMM算法的相关推导及原理
极大似然估计 我们先从极大似然估计说起,来考虑这样的一个问题,在给定的一组样本x1,x2······xn中,已知它们来自于高斯分布N(u, σ),那么我们来试试估计参数u,σ. 首先,对于参数估计的方 ...
随机推荐
- STM32伺服编码器接口
在STM32的高级定时器和一般定时器中有Encoder interface mode(编码器接口),TI1和TI2分别对应TIM_CH1 和TIM_CH2 通道. 一.计数规则如下: 表55的是编码器 ...
- ReactNative学习之Html基础
前言: React Native开发作为一种新型的移动开发方式,个人觉得App的一部分需求会逐步替换成这种方式,也是公司移动开发人员所必须掌握的一种开发技术,所以鉴于这种情况我觉得很有必要学习一下,特 ...
- JavaSE教程-02Java基本语法
1.注释 什么是注释 用于解释说明程序作用的文字 Java中注释分类格式 单行注释 格式: //注释文字 多行注释 格式: /* 注释文字 */ 文档注释 格式:/* 注释文字 / 2.关键字 什么是 ...
- 如何在vuejs中抽出公共代码
当我们在使用vue构建中大型项目时,通常会遇到某些经常用的方法以及属性,比如说搭建一个员工管理系统,请求的url需要一个共同的前缀,或者在某几个view中需要用到时间,这个时间是通过某方法格式化之后的 ...
- Codility---EquiLeader
Task description A non-empty zero-indexed array A consisting of N integers is given. The leader of t ...
- 增强for循环用法
1.首先增强for循环和iterator遍历的效果是一样的,也就说增强for循环的内部也就是调用iteratoer实现的, 但是增强for循环有些缺点,例如不能在增强循环里动态的删除集合内容.不能获取 ...
- flask 扩展之 -- flask-pagedown
支持 Markdown 语法, 并添加 富文本文章的预览功能. 使用到的包列表: PageDown : 使用 JavaScript 实现的客户端 Markdown 到 HTML 的转换程序. Flas ...
- 对js运算符“||”和“&&”的总结
首先出个题: 如图: 假设对成长速度显示规定如下: 成长速度为5显示1个箭头: 成长速度为10显示2个箭头: 成长速度为12显示3个箭头: 成长速度为15显示4个箭头: 其他都显示都显示0各箭头. 用 ...
- web前端面试总结(二)
这段时间大大小小面试确实不少,相对之前那篇被虐到体无完肤这几次确实相对来说有很大进步这里总结一下: 1.发现自己,站在个人角度我还是挺赞成出去面试的,不管你对现在的公司是否满意,当你觉得在这里已经有一 ...
- 长沙JavaEE培训机构哪家比较靠谱?Java培训的职业前景
长沙JavaEE培训机构哪家比较靠谱?可信度高? 全球信息化的时代已经到来,IT行业越来越受大众的欢迎,所以越来越多的人把注意力集中到IT职业教育培训.在软件开发领域,Java培训已经成为人们的首选, ...