爬虫新手学习2-爬虫进阶(urllib和urllib2 的区别、url转码、爬虫GET提交实例、批量爬取贴吧数据、fidder软件安装、有道翻译POST实例、豆瓣ajax数据获取)
1、urllib和urllib2区别实例
urllib和urllib2都是接受URL请求相关模块,但是提供了不同的功能,两个最显著的不同如下:
urllib可以接受URL,不能创建设置headers的Request类实例,urlib2可以。
url转码
https://www.baidu.com/s?wd=%E5%AD%A6%E7%A5%9E
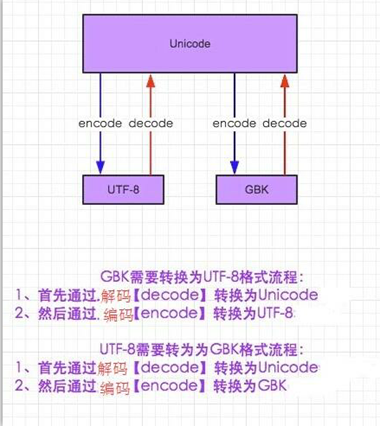
python字符集解码加码过程:
2.爬虫GET提交实例
#coding:utf-8 import urllib #负责url编码处理
import urllib2 url = "https://www.baidu.com/s"
word = {"wd": "繁华"}
word = urllib.urlencode(word) #转换成url编码格式(字符串)
newurl = url + "?" + word headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} request = urllib2.Request(newurl, headers=headers) response = urllib2.urlopen(request) print response.read()
#coding:utf-8 import urllib #负责url编码处理
import urllib2 url = "https://www.baidu.com/s"
word = {"wd": "咖菲猫"}
word = urllib.urlencode(word) #转换成url编码格式(字符串)
newurl = url + "?" + word headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} request = urllib2.Request(newurl, headers=headers) response = urllib2.urlopen(request) print response.read()
自定义爬虫GET提交实例
#coding:utf-8 import urllib #负责url编码处理
import urllib2 url = "https://www.baidu.com/s"
keyword = raw_input("请输入要查询的关键字:")
word = {"wd": keyword}
word = urllib.urlencode(word) #转换成url编码格式(字符串)
newurl = url + "?" + word headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} request = urllib2.Request(newurl, headers=headers) response = urllib2.urlopen(request) print response.read()
3.批量爬取贴吧页面数据
分析贴吧URL
http://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F
pn递增50为一页
0为第一页
http://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&pn=0
50为第二页
http://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&pn=50
100为第三页
http://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&pn=100
批量爬贴吧实例
#coding:utf-8 import urllib
import urllib2 def loadPage(url, filename):
'''
作用:根据url发送请求, 获取服务器响应文件
url:需要爬取的url地址
filename:文件名
''' print "正在下载" + filename headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} request = urllib2.Request(url, headers = headers)
response = urllib2.urlopen(request)
return response.read() def writeFile(html, filename):
'''
作用:保存服务器相应文件到本地硬盘文件里
html:服务器相应文件
filename:本地磁盘文件名
''' print "正在存储" + filename
with open(unicode(filename, 'utf-8'), 'w') as f:
f.write(html)
print "-" * 20 def tiebaSpider(url, beginPage, endPage, name):
'''
作用:负责处理url,分配每个url去发送请求
url:需要处理的第一个url
beginPage:爬虫执行的起始页面
endPage:爬虫执行的截止页面
'''
for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50 filename = "第" + name + "-" + str(page) + "页.html"
#组合为完整的url,并且pn值每次增加50
fullurl = url + "&pn=" + str(pn)
#print fullurl #调用loadPage()发送请求获取HTML页面
html = loadPage(fullurl, filename)
#将获取到的HTML页面写入本地磁盘文件
writeFile(html, filename) #模拟main函数"
if __name__ == "__main__":
kw = raw_input("请输入需要爬取的贴吧:")
beginPage = int(raw_input("请输入起始页:"))
endPage = int(raw_input("请输入终止页:")) url = "http://tieba.baidu.com/f?"
key = urllib.urlencode({"kw": kw}) #组合后的url示例:http://tieba.baidu.com/f?kw=绝地求生
newurl = url + key
tiebaSpider(newurl, beginPage, endPage, kw)
4.Fidder使用安装
下载fidder
安装后,照下图设置

5.有道翻译POST分析
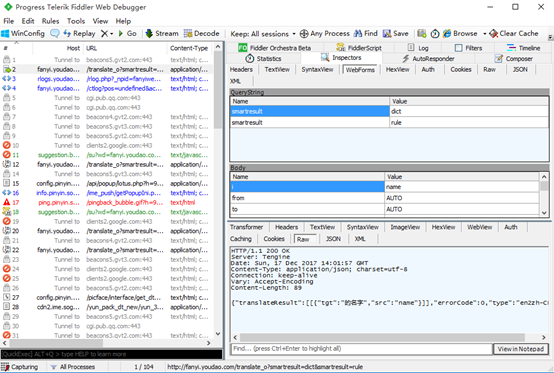
调用有道翻译POST API实例
#coding:utf-8 import urllib
import urllib2 #通过抓包的方式获取的url,并不是浏览器上显示的url
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null" #完整的headers
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Origin": "http://fanyi.youdao.com",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8"
} #用户接口输入
key = raw_input("请输入需要翻译的英文单词:") #发送到web服务器的表单数据
formdata = {
"i": key,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": "",
"sign": "29e3219b8c4e75f76f6e6aba0bb3c4b5",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTIME",
"typoResult": "false"
} #经过urlencode转码
data = urllib.urlencode(formdata) #如果Request()方法里的data参数有值,那么这个请求就是POST
#如果没有,就是Get
request = urllib2.Request(url, data= data, headers= headers) print urllib2.urlopen(request).read()
6.Ajax加载方式的数据获取
豆瓣分析Ajax
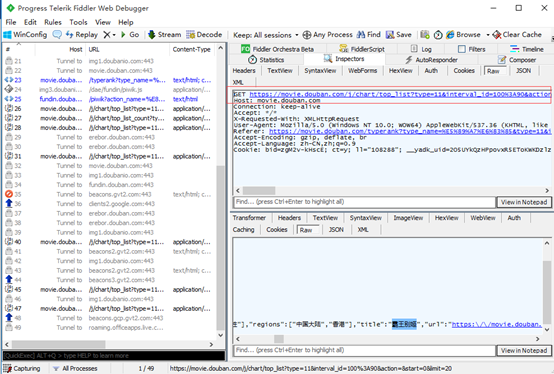
爬取豆瓣电影排行信息实例
#coding:utf-8 import urllib2
import urllib url = "https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=" headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} formdata = {
"start": "",
"limit": ""
} data = urllib.urlencode(formdata) request = urllib2.Request(url, data = data, headers = headers) print urllib2.urlopen(request).read()
爬虫新手学习2-爬虫进阶(urllib和urllib2 的区别、url转码、爬虫GET提交实例、批量爬取贴吧数据、fidder软件安装、有道翻译POST实例、豆瓣ajax数据获取)的更多相关文章
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- python爬虫25 | 爬取下来的数据怎么保存? CSV 了解一下
大家好 我是小帅b 是一个练习时长两年半的练习生 喜欢 唱! 跳! rap! 篮球! 敲代码! 装逼! 不好意思 我又走错片场了 接下来的几篇文章 小帅b将告诉你 如何将你爬取到的数据保存下来 有文本 ...
- Python爬虫:爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫——request实例:爬取网易云音乐华语男歌手top10歌曲
requests是python的一个HTTP客户端库,跟urllib,urllib2类似,但比那两个要简洁的多,至于request库的用法, 推荐一篇不错的博文:https://cuiqingcai. ...
- Python爬取招聘网站数据,给学习、求职一点参考
1.项目背景 随着科技的飞速发展,数据呈现爆发式的增长,任何人都摆脱不了与数据打交道,社会对于“数据”方面的人才需求也在不断增大.因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于 ...
- 4 urllib和urllib2的区别
4 urllib和urllib2的区别 这个面试官确实问过,当时答的urllib2可以Post而urllib不可以. urllib提供urlencode方法用来GET查询字符串的产生,而urllib2 ...
随机推荐
- JSP 学习笔记
JSP 全名为Java Server Pages,中文名叫java 服务器页面,它是在传统的 HTML 页面中插入 JAVA 代码片段和 JSP 标签形成的文件. 上一篇 Servlet 中只是讲解了 ...
- Python入门学习(二)
1 字典 1.1 字典的创建和访问 字典不同于前述的序列类型,它是一种映射类型.它的引入是为了简化定义索引值和元素值存在特定关系的定义和访问问题. 字典的定义形式为:字典变量名 = {key1:val ...
- C语言的第一个程序 “hello world!”
1,C语言的简介 C语言是一门通用计算机编程语言,应用广泛.C语言的设计目标是提供一种能以简易的方式编译.处理低级存储器.产生少量的机器码以及不需要任何运行环境支持便能运行的编程语言. ...
- Python学习二:词典基础详解
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/7862377.html 邮箱:moyi@moyib ...
- MySQL GTIDs(global transaction identifiers)
1.如何定义和生成GTIDs 唯一性:在所有主从库都是唯一的,由二元组构成 每个事务和GTIDs之间都有1:1映射 GTID = source_id:transaction_id source_id标 ...
- Python mysqldb模块
#!/usr/bin/env python2.7 #-*- coding:utf8 -*- import os import sys import logging import MySQLdb fro ...
- css实现左侧固定宽,右侧自适应的7中方法
一个面试会问的问题,如何实现两个盒子,左侧固定宽度,右侧自适应. 1.利用 calc 计算宽度的方法 css代码如下: .box{overflow: hidden;height: 100px;marg ...
- 《java.util.concurrent 包源码阅读》17 信号量 Semaphore
学过操作系统的朋友都知道信号量,在java.util.concurrent包中也有一个关于信号量的实现:Semaphore. 从代码实现的角度来说,信号量与锁很类似,可以看成是一个有限的共享锁,即只能 ...
- bootstrap 组件之"导航条"
一个典型的导航条基本代码如下: <nav class="navbar navbar-default"> <div class="container&qu ...
- HTML基础下
知识点一: HTML5的标准结构: <!DOCTYPE html> <html lang='en'> <head> <meat charset='utf-8' ...