吴恩达机器学习101:SVM优化目标
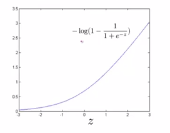
1.为了描述SVM,需要从logistic回归开始进行学习,通过改变一些小的动作来进行支持向量机操作。在logistic回归中我们熟悉了这个假设函数以及右边的sigmoid函数,下式中z表示θ的转置乘以x,
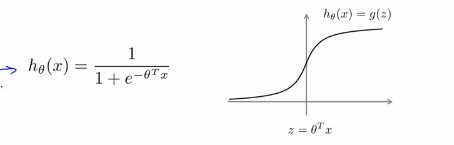
(1)如果我们有一个样本,其中y=1,这样的一个样本来自训练集或者测试集或者交叉验证集,我们希望h(x)能尽可能的接近1。因此我们想要正确的将样本进行分类,如果h(x)趋近于1,就意味着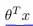 远大于0,即
远大于0,即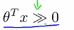 。
。
(2)相应的如果y=0,我们想hθ(x)=0,那么 远远小于0,即
远远小于0,即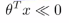
(3)logistic regresssion的代价函数:
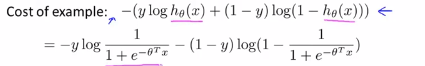
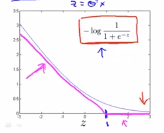
如果y=1,当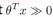 的时候,我们可以画下图:
的时候,我们可以画下图:
如果y=0,当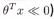 ,我们可以画下图:
,我们可以画下图:
线性回归代价函数:
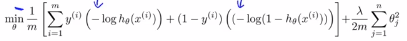
支持向量机代价函数:
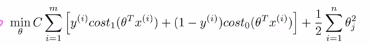
与logistic回归不同的是,支持向量机并不会输出概率,而是优化上面的这个代价函数,得到一个参数θ,而支持向量机所做的是进行了一个直接的预测,预测y是0还是1.所以如果θ的转置乘以x的值大于0,那么它就会输出1;如果θ的转置乘以x的转置小于0 ,那么它就会输出0
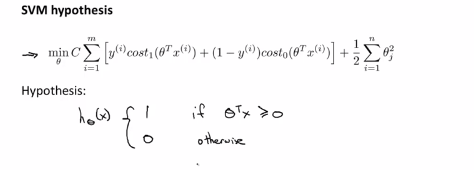
吴恩达机器学习101:SVM优化目标的更多相关文章
- 吴恩达机器学习笔记48-降维目标:数据压缩与可视化(Motivation of Dimensionality Reduction : Data Compression & Visualization)
目标一:数据压缩 除了聚类,还有第二种类型的无监督学习问题称为降维.有几个不同的的原因使你可能想要做降维.一是数据压缩,数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,而且它也让我们 ...
- ML:吴恩达 机器学习 课程笔记(Week1~2)
吴恩达(Andrew Ng)机器学习课程:课程主页 由于博客编辑器有些不顺手,所有的课程笔记将全部以手写照片形式上传.有机会将在之后上传课程中各个ML算法实现的Octave版本. Linear Reg ...
- 吴恩达机器学习笔记47-K均值算法的优化目标、随机初始化与聚类数量的选择(Optimization Objective & Random Initialization & Choosing the Number of Clusters of K-Means Algorithm)
一.K均值算法的优化目标 K-均值最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和,因此 K-均值的代价函数(又称畸变函数 Distortion function)为: 其中
- [吴恩达机器学习笔记]12支持向量机3SVM大间距分类的数学解释
12.支持向量机 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广 12.3 大间距分类背后的数学原理- Mathematic ...
- 吴恩达机器学习笔记58-协同过滤算法(Collaborative Filtering Algorithm)
在之前的基于内容的推荐系统中,对于每一部电影,我们都掌握了可用的特征,使用这些特征训练出了每一个用户的参数.相反地,如果我们拥有用户的参数,我们可以学习得出电影的特征. 但是如果我们既没有用户的参数, ...
- [吴恩达机器学习笔记]13聚类K-means
13.聚类 觉得有用的话,欢迎一起讨论相互学习~Follow Me 13.1无监督学习简介 从监督学习到无监督学习 在一个典型的监督学习中,我们有一个有标签的训练集,我们的目标是找到能够区分正样本和负 ...
- 吴恩达机器学习笔记41-支持向量机的优化目标(Optimization Objective of Support Vector Machines)
- 吴恩达机器学习笔记45-使用支持向量机(Using A SVM)
本篇我们讨论如何运行或者运用SVM. 在高斯核函数之外我们还有其他一些选择,如:多项式核函数(Polynomial Kernel)字符串核函数(String kernel)卡方核函数( chi-squ ...
- [吴恩达机器学习笔记]12支持向量机2 SVM的正则化参数和决策间距
12.支持向量机 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广 12.2 大间距的直观理解- Large Margin I ...
随机推荐
- ZooKeePer总汇
一.什么Zookeeper Zookeeper是一个分布式开源框架,提供了协调分布式应用的基本服务,它向外部应用暴露一组通用服务——分布式同步(Distributed Synchronization) ...
- ThreadPool用法与优势
1. 线程池的优点: 合理利用线程池能够带来三个好处.第一:降低资源消耗.通过重复利用已创建的线程降低线程创建和销毁造成的消耗.第二:提高响应速度.当任务到达时,任务可以不需要等到线程创建就能立即执 ...
- 第七周总结&第五次实验报告
学习总结 这周我们加深了对抽象类与接口的学习,获得的知识点也比上周多了许多,抽象类与接口很相似,就比如别人还没有做完的是交给你来做,而他那些样式都做好了,你只需要完善即可 但也有不同点. 区别点 抽象 ...
- 【python】小型神经网络的搭建
import numpy as np def sigmoid(x): # Sigmoid activation function: f(x) = 1 / (1 + e^(-x)) return 1 / ...
- 浏览器端-W3School-HTML:HTML DOM Area 对象
ylbtech-浏览器端-W3School-HTML:HTML DOM Area 对象 1.返回顶部 1. HTML DOM Area 对象 Area 对象 Area 对象代表图像映射的一个区域(图像 ...
- Android 面试汇总<三>
1.3 计算机网络 基础 Q:五层协议的体系结构分别是什么?每一层都有哪些协议? 技术点:网络模型.协议 思路:分条解释每层名字以及协议 参考回答: 物理层 数据链路层:逻辑链路控制LLC.媒体接入控 ...
- 自定义View饼状图的绘制
package com.loaderman.customviewdemo; import android.content.Context; import android.graphics.Canvas ...
- 第一部分 Python基础知识
Python测试开发核心编程主要分两部分,python3基础和Python进阶,每部分的重点内容如下 一. Python测试开发核心编程 数据类型 控制结构 异常处理 文件操作 线程与进程(了解) 常 ...
- 分期花呗 账户交易通知:尾号6932客户,您的申请已通过,账户余额38139元,无手续费,点t.cn/Aijsx9vq取款,回T退订。
10692285499 分期花呗 账户变动通知:尾号6932客户,您的申请已通过,账户余额5000元,请及时点击t.cn/AiOMsNAm取款,回T退订. 106935276259002分期花呗 账户 ...
- Kibana 5.5.2 安装包下载 (各种历史版本下载)
背景说明 最近项目中在使用 5.5.2 版本的 Elasticsearch 作为数据库,使用的是以前的老版本. 用到 Elasticsearch ,难免要和其相关基本操作命令打交道.选择一款顺手的工 ...