python爬虫——爬取淘票票正在热映电影
今天正好学习了一下python的爬虫,觉得收获蛮大的,所以写一篇博客帮助想学习爬虫的伙伴们。
这里我就以一个简单地爬取淘票票正在热映电影为例,介绍一下一个爬虫的完整流程。
首先,话不多说,上干货——源代码
from bs4 import BeautifulSoup
import requests
import json #伪装成浏览器请求
headers={
'User-Agent':'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;',
'Referer':'https://www.taopiaopiao.com/showList.htm?spm=a1z21.3046609.header.4.1d69112aGq86y0&n_s=new'
} #获取网页的代码
def getPage(url):
try:
response=requests.get(url)
if response.status_code==200: #http状态码,200表示请求成功
return response.text
else:
return None
except Exception:
return None def getInfo(html):
soup=BeautifulSoup(html,'lxml') #创建bs对象 bs是使用的python默认的解析器,lxml也是解析器
items=soup.select('div .movie-card-wrap') #去网站的控制台找需要内容的上级标签元素,注意找的时候讲究方法,爬取的内容大部分都是有规律的,找到要爬取内容后,找你要爬的内容的父标签,这里找到div标签,然后后面的.movie-card-wrap是类名,当然也可以按照id查找,不会的自行百度soup.select
i=1
for item in items:
name=item.find(name='div',class_='movie-card-name').get_text().strip() #这个是找你要爬取内容的标签和它的类
info=item.find(name='div',class_='movie-card-list').get_text().strip()
print(str(i)+' '+'电影名:'+name+'\n'+info+'\n')
i=i+1 url='https://www.taopiaopiao.com/showList.htm?spm=a1z21.3046609.header.4.1d69112aGq86y0&n_s=new'
html=getPage(url)
getInfo(html)
然后说一下代码的具体含义,其实注释都有,我再详细讲一下流程吧
一、伪装成浏览器请求headers
这很好理解,因为如果不伪装的话,那你去爬取,爬取网站就能获悉你在爬数据,很容易被封,所以我们写一个headers的json伪装成浏览器来访问,不明白的自行百度
二、获取网页代码getPage
这部分代码很好理解,有用的就两行,所以就不详细说了,用的时候直接用即可
三、获取信息getInfo
这部分是我觉得就爬取而言最难的一部分,当然也不是很难,所以我结合例子详细说一下
首先我们要知道,爬取网页内容是爬取的网页代码中的内容,服务器端的数据我们是没办法爬取到的,什么意思,我们打开浏览器,按F12
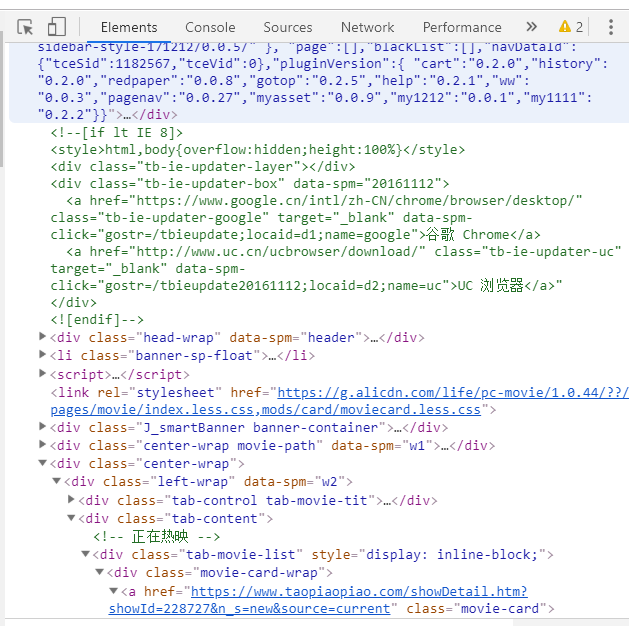
可以看到网页的源代码,然后我们要爬取的就是标签之间的那部分内容
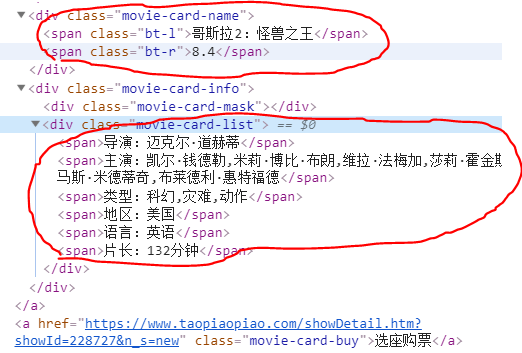
就是例如我上面画红圈的这些内容,我们这一步要做的,就是定位你要爬取内容在源代码中的位置,这么说大家可以理解吧。然后找到对应的标签,调用方法就可以了。
然后爬取到的信息可以存数据库,可以写成json数据,可以写入文件等再去做二次处理,筛选一些有用的数据,这里为了方便理解,我直接输出到控制台大家可以看一下结果。

这就是python爬虫,我也是新手,可能有很多说的不到位,希望大家海涵。
python爬虫——爬取淘票票正在热映电影的更多相关文章
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. ...
- 简单的python爬虫--爬取Taobao淘女郎信息
最近在学Python的爬虫,顺便就练习了一下爬取淘宝上的淘女郎信息:手法简单,由于淘宝网站本上做了很多的防爬措施,应此效果不太好! 爬虫的入口:https://mm.taobao.com/json/r ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
随机推荐
- egon说一切皆对象--------面向对象进阶紫禁之巅
一.检查isinstance(obj,cls)和issubclass(sub,super) class Foo(object): pass obj = Foo() isinstance(obj, Fo ...
- IP电话的配置
内容描述:IP电话配置 问题描述: IP电话站点为8203,IP地址为10.11.6.3,电话状态为空心(不正常). 处理过程: 1.在浏览器中打开输入原先已经配置正常的IP话机的IP地址访问其配置, ...
- css实现div内凹角样式
平常的开发中我们一般使用到圆角都是外凸的,即border-radius属性.而如果有内凹角的情况,我们一般的考虑实现方法有2种.一种是直接使用背景图片,一种是使用css. 用到的属性则是backgro ...
- 关于数据库抛出异常:Incorrect string value: '\xE1\x...' for column '字段名' at row 1 问题的解决方法
打开sql,进行语句编辑 ENGINE=InnoDB DEFAULT CHARSET=utf8;字符集设置utf-8编码
- 造个自己的Vue的UI组件库类似Element
前言 随着前端的三大框架的出现,组件化的思想越来越流行,出现许多组件库.它能够帮助开发者节省时间提高效率, 如React的Ant-design,Vue的iView,Element等,它们的功能已经很完 ...
- 一、MyBatis基本使用,包括xml方式、注解方式、及动态SQL
一.简介 发展历史:MyBatis 的前 身是 iBATIS.最初侧重于 密码软件的开发 , 后来发展成为一款基于 Java 的持久层框架. 定 位:MyBatis 是一款优秀的支持自定义 ...
- 前端之CSS:CSS补充
css样式之补充... css常用的一些属性: 1.去掉下划线 :text-decoration:none ;2.加上下划线: text-decoration: underline; 3.调整文本和图 ...
- python 小游戏,和电脑玩剪刀石头布
# -*- coding: utf-8 -*- """ Created on Fri Oct 25 16:28:12 2019 if判断综合演练,剪刀石头布 @autho ...
- iOS Core Image-----十行代码实现微信朋友圈模糊效果
昨天下午微信的朋友圈着实火了一把,在这之后好多程序员都通过抓包工具看到了原图,但是我却在想,网上说是在移动前端做到的那是怎么做到的呢,经过一些学习,终于掌握了一些Core Image的知识,做出了相应 ...
- ipcloud上传裁切图片,保存为base64再压缩传给后台
<!doctype html> <html> <head> <meta charset="utf-8"> <meta name ...