spark复习笔记(3)
在windows上实现wordcount单词统计
一、编写scala程序,引入spark类库,完成wordcount
1.sparkcontextAPI
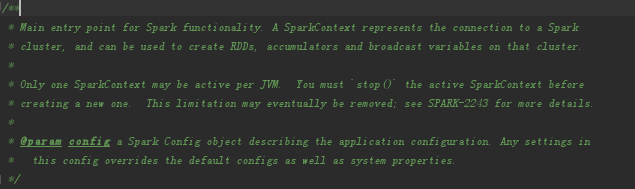
sparkcontext是spark功能的主要入口点,代表着到spark集群的连接,可用于在这些集群上创建RDD(弹性分布式数据集),累加器和广播变量。在每一个JVM上面只允许一个活跃的sparkcontext。在创建一个新的RDD之前,你应该停止这个活跃的SparkContext
2.sparkconf配置对象

sparkconf是对spark应用的配置,用来设置键值对的各种spark参数。大多数的时候,你需要通过new sparkconf的方式来创建一个对象,会从任何的spark系统属性中记性加载,从这个方面来讲,你在sparkconf上设置的参数会直接影响你在整个系统属性中的优先级
3.scala版单词统计:wordCount
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]): Unit = {
//创建spark配置对象
val conf = new SparkConf();
//设置app名字
conf.setAppName("WordConf")
//创建master
conf.setMaster("local");
//创建spark上下文对象
val sc = new SparkContext(conf);
//加载文本文件
val rdd1 = sc.textFile("E:\\studyFile\\data\\test.txt")
//对rdd1中的对象压扁
val rdd2 = rdd1.flatMap(line=>line.split(" "))
//映射w=>(w,1)
val rdd3 = rdd2.map((_,))
val rdd4 = rdd3.reduceByKey(_ + _)
val r= rdd4.collect()
//遍历打印
r.foreach(println)
}
}
3.java版单词统计:wordCount
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2; import java.util.ArrayList;
import java.util.Iterator;
import java.util.List; public class WordCountJava2 {
//创建conf对象
public static void main(String[] args){
SparkConf conf = new SparkConf();
conf.setAppName("WordCountJava2");
conf.setMaster("local");
//创建java版的sparkContext上下文对象
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> rdd1=sc.textFile("E:/studyFile/data/test.txt");
//先将单词压扁
JavaRDD<String> rdd2 = rdd1.flatMap(new FlatMapFunction<String, String>() {
//迭代的方法
public Iterator<String> call(String s) throws Exception {
List<String> list = new ArrayList<String>();
String[] arr = s.split(" ");
for(String ss:arr){
list.add(ss);
}
return list.iterator();
}
});
//映射,将单词映射为:word===>(word,1)
JavaPairRDD<String,Integer> rdd3=rdd2.mapToPair(new PairFunction<String, String, Integer>() { public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s,);
}
});
JavaPairRDD<String,Integer> rdd4 = rdd3.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
//函数捏合的过程
return v1+v2;
}
});
List<Tuple2<String,Integer>> list=rdd4.collect();
for(Tuple2<String,Integer> t :list){
System.out.println(t._1+":"+t._2);
}
}
}
4.提交作业到完全分布式spark集群上来运行
1)到处jar包
2)spark-submit --master local --name WordCount --class com.jd.spark.scala.WordCountDemoScala spark-daemon1-1.0-SNAPSHOT.jar /home/centos/test.txt
5.提交作业到完全分布式spark集群上来运行(只需要hdfs)
1)需要启动hadoop集群
$>start-dfs.sh
2)put文件到hdfs
hdfs dfs -put test.txt /user/centos/hadoop/
2)spark-submit提交命令运行job
$>spark-submit --master spark://s11:7070 --name WordCount --class com.jd.spark.scala.WordCountDemoScala spark-daemon1-1.0-SNAPSHOT.jar hdfs://s11:8020/user/centos/hadoop/test.txt
spark复习笔记(3)的更多相关文章
- spark复习笔记(1)
使用spark实现work count ---------------------------------------------------- (1)用sc.textFile(" &quo ...
- spark复习笔记(7):sparkstreaming
一.介绍 1.sparkStreaming是核心模块Spark API的扩展,具有可伸缩,高吞吐量以及容错的实时数据流处理等.数据可以从许多来源(如Kafka,Flume,Kinesis或TCP套接字 ...
- spark复习笔记(7):sparkSQL
一.saprkSQL模块,使用类sql的方式访问Hadoop,实现mr计算,底层使用的是rdd 1.hive //hadoop mr sql 2.phenoix //hbase上构建sql的交互过 ...
- spark复习笔记(6):RDD持久化
在spark中最重要的功能之一是跨操作在内存中持久化数据集.当你持久化一个RDD的时候,每个节点都存放了一个它在内存中计算的一个分区,并在该数据集的其他操作中进行重用,持久化一个RDD的时候,节点上的 ...
- spark复习笔记(6):数据倾斜
一.数据倾斜 spark数据倾斜,map阶段对key进行重新划分.大量的数据在经过hash计算之后,进入到相同的分区中,zao
- spark复习笔记(4):RDD变换
一.RDD变换 1.返回执行新的rdd的指针,在rdd之间创建依赖关系.每个rdd都有一个计算函数和指向父rdd的指针 Spark是惰性的,因此除非调用某个转换或动作,否则不会执行任何操作,否则将触发 ...
- spark复习笔记(5):API分析
0.spark是基于hadoop的mr模型,扩展了MR,高效实用MR模型,内存型集群计算,提高了app处理速度. 1.特点:(1)在内存中存储中间结果 (2)支持多种语言:java scala pyt ...
- spark复习笔记(4):spark脚本分析
1.[start-all.sh] #!/usr/bin/env bash # # Licensed to the Apache Software Foundation (ASF) under one ...
- spark复习笔记(3):使用spark实现单词统计
wordcount是spark入门级的demo,不难但是很有趣.接下来我用命令行.scala.Java和python这三种语言来实现单词统计. 一.使用命令行实现单词的统计 1.首先touch一个a. ...
随机推荐
- 10个你不得不知的WEB移动端开发的兼容问题
1.IOS下input设置type=button属性disabled设置true,会出现样式文字和背景异常问题,使用opacity=1来解决 2.一些情况下对非可点击元素如(label,span)监听 ...
- 长链剖分优化树形DP总结
长链剖分 规定若\(x\)为叶结点,则\(len[x]=1\). 否则定义\(preferredchild[x]\)(以下简称\(pc[x]\),称\(pc[x]\)为\(x\)的长儿子)为\(x\) ...
- sqlserver控制台-添加用户
1.右键新建登陆名 2. 常规选项 3.服务器角色 4.用户映射
- Linux相关基础知识
文件目录 /bin 放置系统执行档的目录,指令可被root与一般账户所使用. /boot 放置开机使用到的文档,包括linux核心档案,开机选单与所需设定档. /dev 任何装置与周边设备都是以档案的 ...
- 「BalticOI 2011」Switch the Lamp On
Casper is designing an electronic circuit on a \(N \times M\) rectangular grid plate. There are \(N ...
- org.xml.sax.SAXParseException: 元素类型 "input" 必须由匹配的结束标记 "</input>" 终止。
错误记录 Spring Boot推荐使用thymeleaf作为视图,按照SpringBoot实战一书的案例写Demo. 发生错误: org.xml.sax.SAXParseException: 元素类 ...
- ThinkPHP框架实现rewrite路由配置
rewrite路由形式: //网址/分组/控制器/方法 配置实现rewrite路由的配置: 1. 修改apache的配置 先修改httpd.conf配置文件中的AllowOverrideAll,全 ...
- PEP8中文版 -- Python编码风格指南
Python部落组织翻译, 禁止转载 目录 缩进 制表符还是空格? 行的最大长度 空行 源文件编码 导入 无法忍受的 其 ...
- Delphi XE2 之 FireMonkey 入门(14) - 滤镜: 概览
相关单元: FMX.Filter FMX.FilterCatBlur FMX.FilterCatGeometry FMX.FilterCatTransition FMX_FilterCatColor ...
- 手把手教您在 Windows Server 2019 上使用 Docker
配置 Windows 功能 要运行容器,您还需要启用容器功能 Install-WindowsFeature -Name Containers 在 Window Server 2019 上安装 Dock ...