python爬虫——爬取小说 | 探索白子画和花千骨的爱恨情仇(转载)
转载出处:药少敏 ,感谢原作者清晰的讲解思路!
下述代码是我通过自己互联网搜索和拜读完此篇文章之后写出的具有同样效果的爬虫代码:
from bs4 import BeautifulSoup
import requests if __name__ == '__main__':
html = requests.get('http://www.136book.com/huaqiangu/')
soup = BeautifulSoup(html.content, 'lxml')
#获取所有div
soup_texts = soup.find_all('div', id = 'book_detail', class_= 'box1') f=open('F:/huaqiangu.txt', 'w') #第二个div有用
for x in soup_texts[1].find_all('a'):
#控制台输出网址,章节标题
print(x.get('href'),x.get_text()) down_html = requests.get(x.get('href'))
down_soup = BeautifulSoup(down_html.content, 'lxml')
#获取正文
down_texts = down_soup.select('p') f.write('\n\n')
#写入章节标题
f.write(x.get_text() + '\n')
#写入章节内容
for s in down_texts:
f.write(s.text) f.close()
知识就像碎布,记得“缝一缝”,你才能华丽丽地亮相。
1.Beautiful Soup
1.Beautifulsoup 简介
此次实战从网上爬取小说,需要使用到Beautiful Soup。
Beautiful Soup为python的第三方库,可以帮助我们从网页抓取数据。
它主要有如下特点:
- 1.Beautiful Soup可以从一个HTML或者XML提取数据,它包含了简单的处理、遍历、搜索文档树、修改网页元素等功能。可以通过很简短地代码完成我们地爬虫程序。
- 2.Beautiful Soup几乎不用考虑编码问题。一般情况下,它可以将输入文档转换为unicode编码,并且以utf-8编码方式输出,
2.Beautiful Soup安装
win命令行下:
pip install beautifusoup4
3.Beautiful Soup基础
大家可以参考文档来学习(中文版的哦):
http://beautifulsoup.readthedocs.io/zh_CN/latest/#id8
对于本次爬虫任务,只要了解以下几点基础内容就可以完成:
1.Beautiful Soup的对象种类:
- Tag
- Navigablestring
- BeautifulSoup
- Comment
2.遍历文档树:find、find_all、find_next和children
3.一点点HTML和CSS知识(没有也将就,现学就可以)
2.爬取小说花千骨
1.爬虫思路分析
本次爬取小说的网站为136书屋。
先打开花千骨小说的目录页,是这样的。
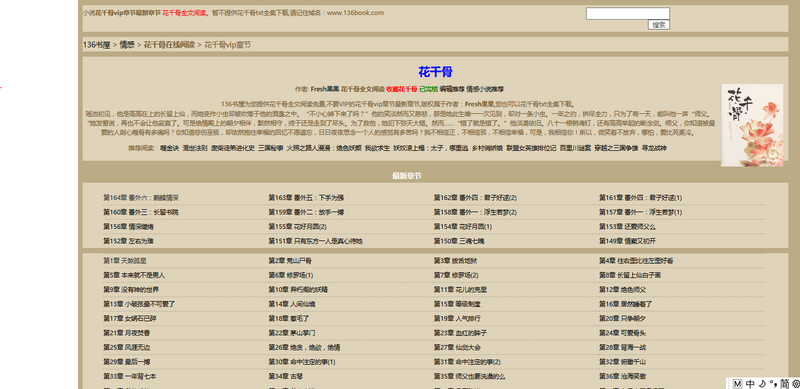
我们的目的是找到每个目录对应的url,并且爬取其中地正文内容,然后放在本地文件中。
2.网页结构分析
首先,目录页左上角有几个可以提高你此次爬虫成功后成就感的字眼:暂不提供花千骨txt全集下载。
继续往下看,发现是最新章节板块,然后便是全书的所有目录。我们分析的对象便是全书所有目录。点开其中一个目录,我们便可以都看到正文内容。
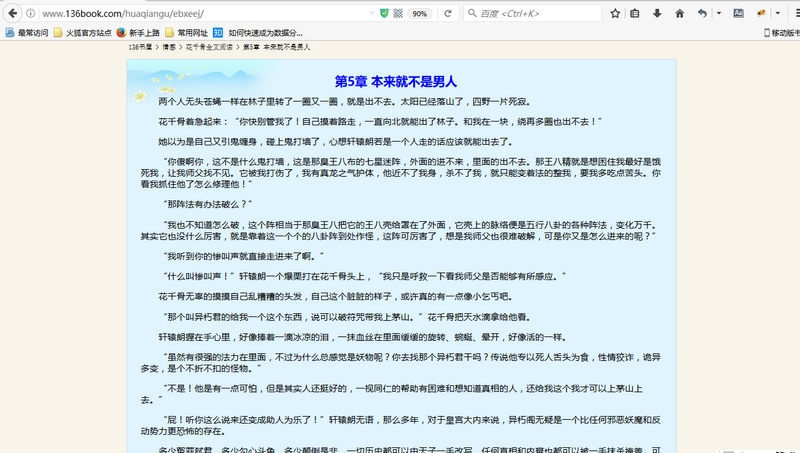
按F12打开审查元素菜单。可以看到网页前端的内容都包含在这里。

我们的目的是要找到所有目录的对应链接地址,爬取每个地址中的文本内容。
有耐心的朋友可以在里面找到对应的章节目录内容。有一个简便方法是点击审查元素中左上角箭头标志的按钮,然后选中相应元素,对应的位置就会加深显示。
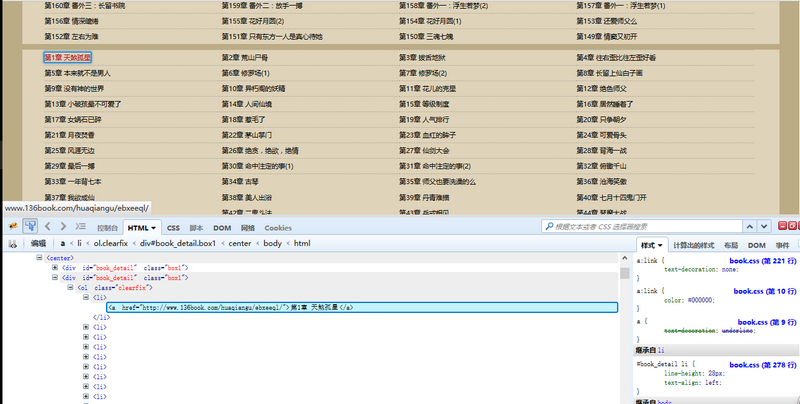
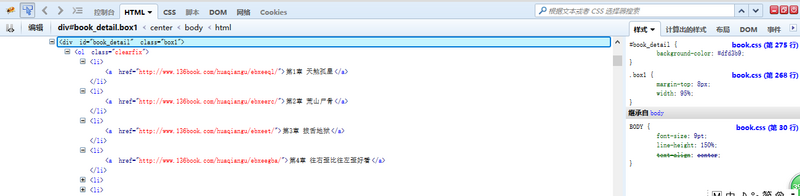
这样我们可以看到,每一章的链接地址都是有规则地存放在<li>中。而这些<li>又放在<div id=”book_detail” class=”box1″>中。
我不停地强调“我们的目的”是要告诉大家,思路很重要。爬虫不是约pao,蒙头就上不可取。
3.单章节爬虫
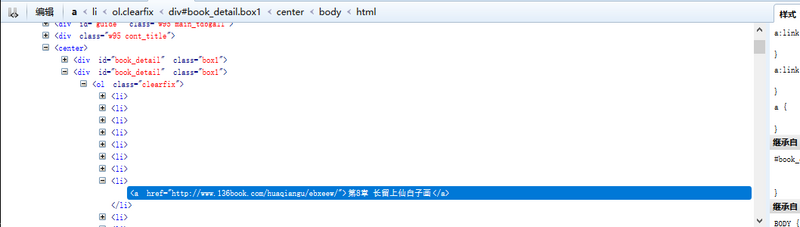
刚才已经分析过网页结构。我们可以直接在浏览器中打开对应章节的链接地址,然后将文本内容提取出来。
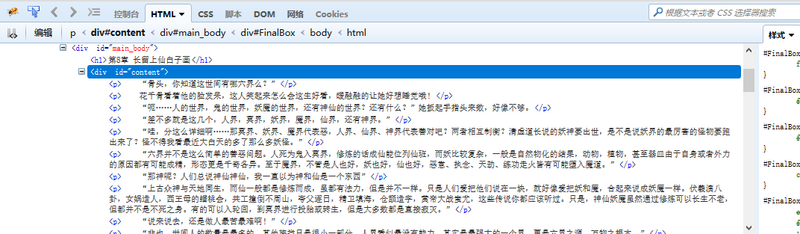
我们要爬取的内容全都包含在这个<div>里面。
代码整理如下:
from urllib import request
from bs4 import BeautifulSoup if __name__ == '__main__':
# 第8章的网址
url = 'http://www.136book.com/huaqiangu/ebxeew/'
head = {}
# 使用代理
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
req = request.Request(url, headers = head)
response = request.urlopen(req)
html = response.read()
# 创建request对象
soup = BeautifulSoup(html, 'lxml')
# 找出div中的内容
soup_text = soup.find('div', id = 'content')
# 输出其中的文本
print(soup_text.text)
运行结果如下:
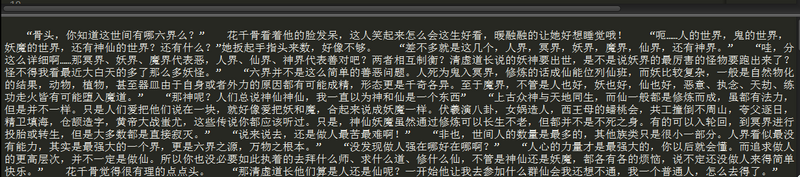
这样,单章节内容爬取就大功告成了。
4.小说全集爬虫
单章节爬虫我们可以直接打开对应的章节地址解析其中的文本,全集爬虫我们不可能让爬虫程序在每章节网页内中跑一遍,如此还不如复制、粘贴来的快。
我们的思路是先在目录页中爬取所有章节的链接地址,然后再爬取每个链接对应的网页中的文本内容。说来,就是比单章节爬虫多一次解析过程,需要用到Beautiful Soup遍历文档树的内容。
1.解析目录页
在思路分析中,我们已经了解了目录页的结构。所有的内容都放在一个所有的内容都放在一个<div id=”book_detail” class=”box1″>中。
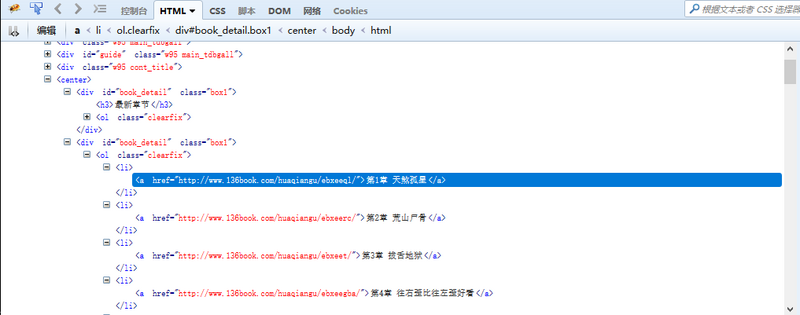
这儿有两个一模一样的<div id=”book_detail” class=”box1″>。
第一个<div>包含着最近更新的章节,第二个<div>包含着全集内容。
请注意,我们要爬取的是第二个<div>中的内容。
代码整理如下:
from urllib import request
from bs4 import BeautifulSoup if __name__ == '__main__':
# 目录页
url = 'http://www.136book.com/huaqiangu/'
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
req = request.Request(url, headers = head)
response = request.urlopen(req)
html = response.read()
# 解析目录页
soup = BeautifulSoup(html, 'lxml')
# find_next找到第二个<div>
soup_texts = soup.find('div', id = 'book_detail', class_= 'box1').find_next('div')
# 遍历ol的子节点,打印出章节标题和对应的链接地址
for link in soup_texts.ol.children:
if link != '\n':
print(link.text + ': ', link.a.get('href'))
执行结果如图:
2.爬取全集内容
将每个解析出来的链接循环代入到url中解析出来,并将其中的文本爬取出来,并且写到本地F:/huaqiangu.txt中。
代码整理如下:
from urllib import request
from bs4 import BeautifulSoup if __name__ == '__main__':
url = 'http://www.136book.com/huaqiangu/'
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
req = request.Request(url, headers = head)
response = request.urlopen(req)
html = response.read()
soup = BeautifulSoup(html, 'lxml')
soup_texts = soup.find('div', id = 'book_detail', class_= 'box1').find_next('div')
# 打开文件
f = open('F:/huaqiangu.txt','w')
# 循环解析链接地址
for link in soup_texts.ol.children:
if link != '\n':
download_url = link.a.get('href')
download_req = request.Request(download_url, headers = head)
download_response = request.urlopen(download_req)
download_html = download_response.read()
download_soup = BeautifulSoup(download_html, 'lxml')
download_soup_texts = download_soup.find('div', id = 'content')
# 抓取其中文本
download_soup_texts = download_soup_texts.text
# 写入章节标题
f.write(link.text + '\n\n')
# 写入章节内容
f.write(download_soup_texts)
f.write('\n\n')
f.close()
执行结果显示 [Finished in 32.3s] 。
打开F盘查看花千骨文件。

爬虫成功。备好纸巾,快快去感受尊上和小骨的虐恋吧。
5.总结
代码还有很多改进的地方。例如文本中包含广告的js代码可以去除,还可以加上爬虫进度显示等等。实现这些功能需要包含正则表达式和os模块知识,就不多说了,大家可以继续完善。
码字辛苦,码代码费神,文字和代码同码更是艰辛无比。如果您觉得文章有那么一丢丢价值,请不要吝啬您的赞赏。
python爬虫——爬取小说 | 探索白子画和花千骨的爱恨情仇(转载)的更多相关文章
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
随机推荐
- 分享两个提高效率的AndroidStudio小技巧
这次分享两个 Android Studio 的小技巧,能够有效提高效率和减少犯错,尤其是在团队协作开发中. Getter 模板修改--自动处理 null 判断 格式化代码自动整理方法位置--广度 or ...
- 第二次作业之微信小程序
2.1 介绍产品相关信息 你选择的产品是? 微信小程序 为什么选择该产品作为分析? 在等待了1年多以后,小程序终于在今年初上线,即速应用在H5领域的累计,便承接在小程序上.8月7日,即速应用的用户微信 ...
- django的模板(二)
模板(二) 实验简介 本节继续介绍模板的常用标签,for.if.ifequal和注释标签. 一.基本的模板标签和过滤器 1. 标签 if/else {% if %} 标签检查(evaluate)一个变 ...
- D的下L
D的小L 时间限制:4000 ms | 内存限制:65535 KB 难度:2 描述 一天TC的匡匡找ACM的小L玩三国杀,但是这会小L忙着哩,不想和匡匡玩但又怕匡匡生气,这时小L给 ...
- JAVA_SE基础——19.数组的定义
数组是一组相关数据的集合,数组按照使用可以分为一维数组.二维数组.多维数组 本章先讲一维数组 不同点: 不使用数组定义100个整形变量:int1,int2,int3;;;;;; 使用数组定义 int ...
- JAVA_SE基础——1.JDK&JRE下载及安装
这是我学了JAVA来写的第一篇博客: 我首先是在传智播客领了张.毕向东老师的免费JAVA学习光盘来学习! 下面我来教大家安装使用JAVA时候必备的JDK 1.首先上甲骨文公司的官方网站下载JDK的安装 ...
- Web Service的工作原理
Web Service基本概念 Web Service也叫XML Web Service WebService是一种可以接收从Internet或者Intranet上的其它系统中传递过来的请求,轻量级的 ...
- build.gradle & gradle.properties
一.build.gradle buildscript { ext { springBootVersion = '1.5.9.RELEASE' } repositories { maven { cred ...
- eclipse开发Groovy代码,与java集成,maven打包编译
今天尝试了一下在eclipse里面写Groovy代码,并且做到和Java代码相互调用,折腾了一下把过程记录下来. 首先需要给eclipse安装一下Groovy的插件,插件地址:https://gith ...
- EasyUI datagrid动态生成列
任务描述:根据用户选择时间段,生成列数据,如图