python 爬虫 基于requests模块发起ajax的get请求
基于requests模块发起ajax的get请求
需求:爬取豆瓣电影分类排行榜 https://movie.douban.com/中的电影详情数据
用抓包工具捉取 使用ajax加载页面的请求
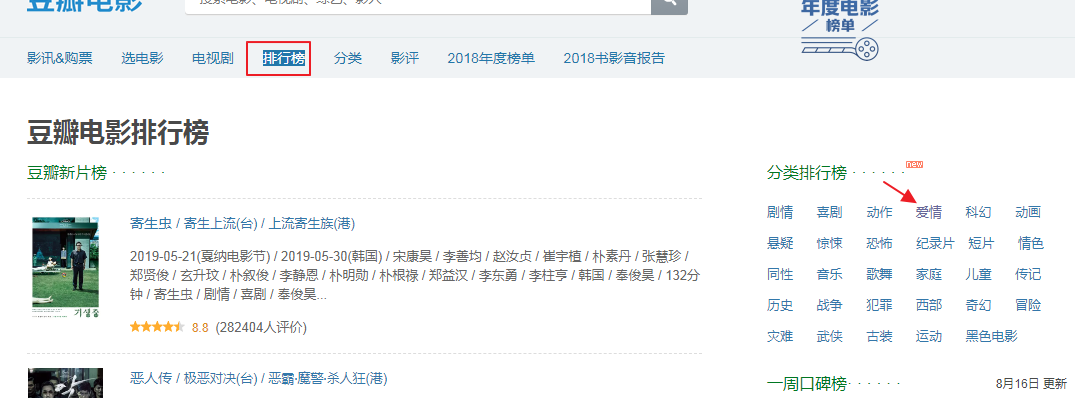
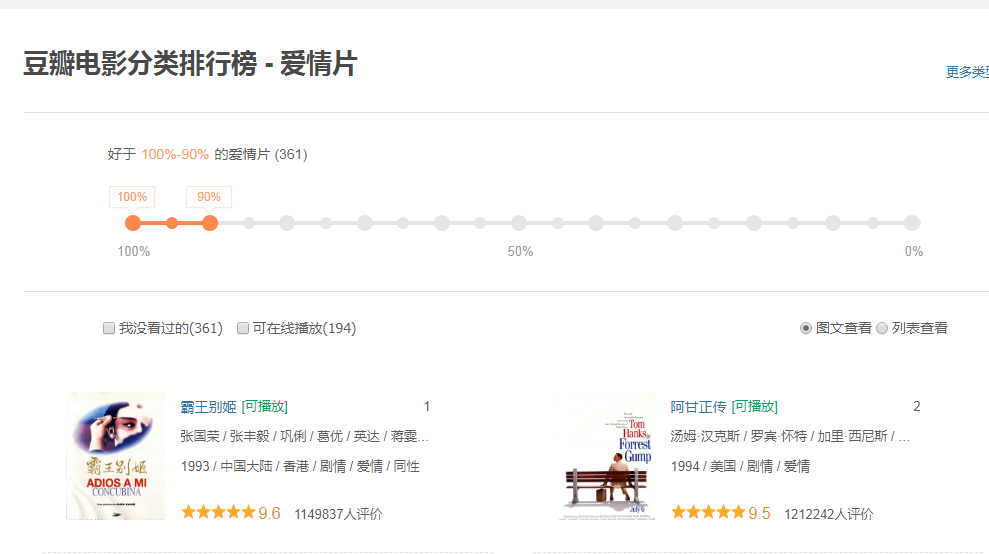
鼠标往下下滚轮拖动页面,会加载更多的电影信息,这个局部刷新是当前页面发起的ajax请求,
用抓包工具捉取页面刷新的ajax的get请求,捉取滚轮在最底部时候发起的请求
这个get请求是本次发起的请求的url
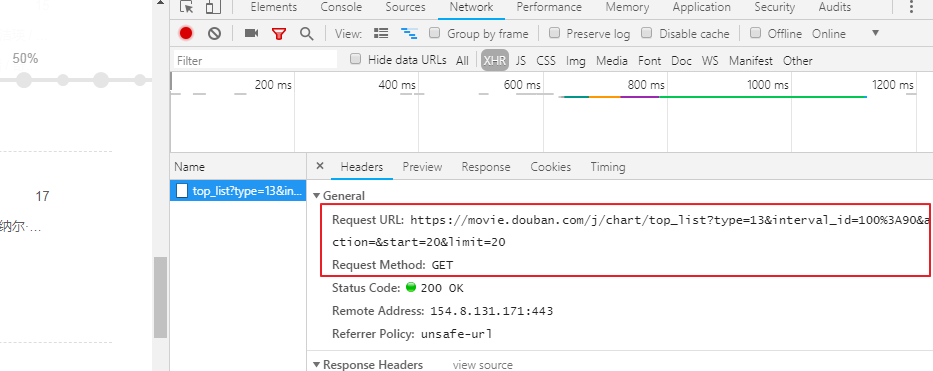
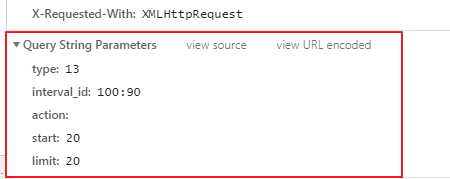
ajax的get请求携带参数
获取响应内容不再是页面数据,是json字符串,是通过异步请求获取的电影详情信息
start和limit参数 需要注意,改变这两个参数获取的电影详情不一样
import requests
import json # 指定ajax-get请求的url(通过抓包进行获取)
url = 'https://movie.douban.com/j/chart/top_list?' # 封装ajax的get请求携带的参数(从抓包工具中获取) 封装到字典
param = {
'type': '',
'interval_id': '100:90',
'action': '',
'start': '', # 从第20个电影开始获取详情
'limit': '', # 获取多少个电影详情
# 改变这两个参数获取的电影详情不一样
} # 定制请求头信息,相关的头信息必须封装在字典结构中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
} # 发起ajax的get请求还是用get方法
response = requests.get(url=url,params=param,headers=headers) # 获取响应内容:响应内容为json字符串
data = response.text
data = json.loads(data)
for data_dict in data:
print(data_dict["rank"],data_dict["title"]) '''
21 芙蓉镇
22 沉静如海
23 淘金记
24 马戏团
25 情迷意乱
26 士兵之歌
27 战争与和平
28 怦然心动
29 大话西游之月光宝盒
30 罗马假日
31 音乐之声
32 一一
33 雨中曲
34 我爱你
35 莫娣
36 卡比利亚之夜
37 婚姻生活
38 本杰明·巴顿奇事
39 情书
40 春光乍泄
'''
从21个电影开始获取信息,总共获取20个电影详情信息
python 爬虫 基于requests模块发起ajax的get请求的更多相关文章
- python 爬虫 基于requests模块发起ajax的post请求
基于requests模块发起ajax的post请求 需求:爬取肯德基餐厅查询http://www.kfc.com.cn/kfccda/index.aspx中指定某个城市地点的餐厅数据 点击肯德基餐厅查 ...
- python 爬虫 基于requests模块的get请求
需求:爬取搜狗首页的页面数据 import requests # 1.指定url url = 'https://www.sogou.com/' # 2.发起get请求:get方法会返回请求成功的响应对 ...
- Python爬虫之requests模块(1)
一.引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃 ...
- python爬虫值requests模块
- 基于如下5点展开requests模块的学习 什么是requests模块 requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求.功能强大,用法简洁高效.在 ...
- 孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块
孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块 (完整学习过程屏幕记录视频地址在文末) 从今天起开始正式学习Python的爬虫. 今天已经初步了解了两个主要的模块: ...
- Python爬虫练习(requests模块)
Python爬虫练习(requests模块) 关注公众号"轻松学编程"了解更多. 一.使用正则表达式解析页面和提取数据 1.爬取动态数据(js格式) 爬取http://fund.e ...
- Python爬虫之requests模块(2)
一.今日内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 二.回顾 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 三. ...
- Python 爬虫二 requests模块
requests模块 Requests模块 get方法请求 整体演示一下: import requests response = requests.get("https://www.baid ...
- Python爬虫(requests模块)
Requests是唯一的一个非转基因的Python HTTP库,人类可以安全享用. Requests基础学习 使用方法: 1.导入Requests模块: import requests 2.尝试用g ...
随机推荐
- vim文本编辑器的用法
vi是一个命令行界面的文本编辑器: vim是vi的改进版: vim不仅有文本编辑:还有文本处理.代码编辑等功能: 1.VIM简介 vim 命令可启动vim编辑器: 一般 vim 文件路径 来使用: ...
- 移动端布局Rem
一.最好用没有之一 http://www.jianshu.com/p/b00cd3506782 虽然博主说这个方案已经过期了 但是新方案还没有理解 就接着沿用这个 可以根据自己常用的设计稿的宽度修改 ...
- webpack4 单入口文件配置 多入口文件配置 以及常用的配置
单入口文件配置 webpack.config.js const path = require('path'); const HtmlWebpackPlugin = require('html-webp ...
- fanout(Publish/Subscribe)发布/订阅
引言 它是一种通过广播方式发送消息的路由器,所有和exchange建立的绑定关系的队列都会接收到消息 不处理路由键,只需要简单的将队列绑定到交换机上 fanout交换机转发消息是最快的,它不需要做路由 ...
- JavaWeb-RESTful(三)_使用SpringMVC开发RESTful_下
JavaWeb-RESTful(一)_RESTful初认识 传送门 JavaWeb-RESTful(二)_使用SpringMVC开发RESTful_上 传送门 JavaWeb-RESTful(三)_使 ...
- hive分区表插入一条测试数据
1.show create table tb_cdr;+-------------------------------------------------------+--+| ...
- C++入门经典-例7.3-析构函数的调用
1:析构函数的名称标识符就是在类名标识符前面加“~”.例如: ~CPerson(); 2:实例代码: (1)title.h #include <string>//title是一个类,此为构 ...
- 黑马lavarel教程---13、分页
黑马lavarel教程---13.分页 一.总结 一句话总结: - lavarel里面的分页操作和tp里面的分页操作几乎是一模一样的 - 控制器:$data=Lesson::paginate(2); ...
- hadoop学习笔记以及遇到的坑整理(长期更新)
1.要看官方文档 http://hadoop.apache.org/docs/current/ 2.start-dfs.sh时提示rcmd: socket: Permission denied 解决方 ...
- 堆排序 java
<pre name="code" class="java">package heapSort; /** * 大根堆 * @author root * ...