Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下)
- 自动使用cookie的方法,告别手动拷贝cookie
- http模块包含一些关于cookie的模块,通过他们我们可以自动的使用cookie
- CookieJar- 管理存储Cookie,向传出的http请求添加cookie
- 这里Cookie存储在内存中,CookieJar实例回收后cookie将消失
- FileCookieJar(filename, delayload=None, policy=None)
- 使用文件管理cookie
- filename是保存cookie的文件
- MozillaCookieJar(filename, delayload=None, policy=None)
- 创建Mocilla浏览器cookie.txt兼容的FileCookieJar实例
-
- 火狐Firefox浏览器需要单独处理
- LwpCookieJar(filename, delayload=None, policy=None)
- 创建于libww-per标准兼容的Set-Cookie3格式的FileCookieJar
- 它们之间的关系: CookieJar-->FileCookieJar-->MozillaCookieJar & LwpCookieJar
利用CookieJar访问人人网
- 自动使用cookie登录,使用步骤:
- 1.打开登录页面后自动通过用户名密码登录
- 2.自动提取反馈回来的cookie
- 3.利用提取的cookie登录个人信息页面
- 创建cookiejar实例
- 生成cookie的管理器
- 创建http请求管理器
- 创建https请求的管理器
- 创建请求管理器
- 通过输入用户名和密码,获取cookie
- 案例13cookiejar文件:https://xpwi.github.io/py/py爬虫/py13cookiejar.py
# 使用cookiejar完整代码
from urllib import request,parse
from http import cookiejar
# 创建cookiejar的实例
cookie = cookiejar.CookieJar()
# 常见cookie的管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
# 创建http请求的管理器
http_handler = request.HTTPHandler()
# 生成https管理器
https_handler = request.HTTPSHandler()
# 创建请求管理器
opener = request.build_opener(http_handler,https_handler,cookie_handler)
def login():
# 负责首次登录,输入用户名和密码,用来获取cookie
url = 'http://www.renren.com/PLogin.do'
id = input('请输入用户名:')
pw = input('请输入密码:')
data = {
# 从input标签的name获取参数的key,value由输入获取
"email": id,
"password": pw
}
# 把数据进行编码
data = parse.urlencode(data)
# 创建一个请求对象
req = request.Request(url,data=data.encode('utf-8'))
# 使用opener发起请求
rsp = opener.open(req)
# 以上代码就可以进一步获取cookie了,cookie在哪呢?cookie在opener里
def getHomePage():
# 地址是用在浏览器登录后的个人信息页地址
url = "http://www.renren.com/967487029/profile"
# 如果已经执行login函数,则opener自动已经包含cookie
rsp = opener.open(url)
html = rsp.read().decode()
with open("rsp1.html", "w", encoding="utf-8")as f:
# 将爬取的页面
print(html)
f.write(html)
if __name__ == '__main__':
login()
getHomePage()
运行结果
看到自己的个人信息就是说明登录成功了
补充:在爬虫代码输入用户名和密码的使用方法
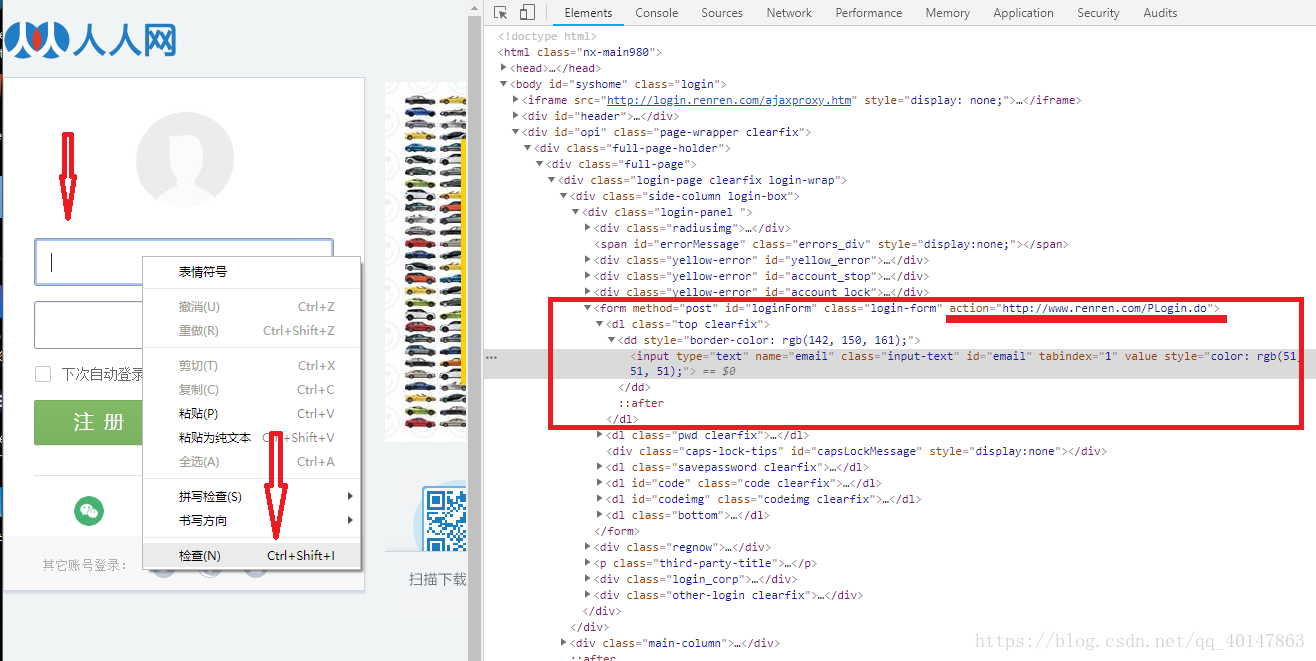
- 1.打开网站首页,登录表单页面
- 2.在输入用户名和密码的地方,【右键检查】,或者查看源代码
- 3.找到登录表单【form标签的action属性】,拷贝地址
- 4.提示:如果不能直接拷贝,【双击】地址,Ctrl+C
- 操作截图:
- 5.找到用户名和密码的【input标签的name属性】,构建参数时使用
- 6.然后在代码中,构建data参数,模拟post请求
# 代码片段
url = 'http://www.renren.com/PLogin.do'
data = {
# 参数使用正确的用户名密码
"email": "18322295195",
"password": "oaix51607991"
}
# 把数据进行编码
data = parse.urlencode(data)
爬虫使用cookie,自动获取cookie解介绍到这里了
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)的更多相关文章
- Python爬虫教程-12-爬虫使用cookie爬取登录后的页面(人人网)(上)
Python爬虫教程-12-爬虫使用cookie(上) 爬虫关于cookie和session,由于http协议无记忆性,比如说登录淘宝网站的浏览记录,下次打开是不能直接记忆下来的,后来就有了cooki ...
- Python之爬虫(二十一) Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- 爬虫(二)Python网络爬虫相关基础概念、爬取get请求的页面数据
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆 ...
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- Python爬虫实战(2):爬取京东商品列表
1,引言 在上一篇<Python爬虫实战:爬取Drupal论坛帖子列表>,爬取了一个用Drupal做的论坛,是静态页面,抓取比较容易,即使直接解析html源文件都可以抓取到需要的内容.相反 ...
- Python网络爬虫第三弹《爬取get请求的页面数据》
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- python网络爬虫《爬取get请求的页面数据》
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在python3中的为urllib.request和urllib. ...
随机推荐
- BZOJ 3437: 小P的牧场
传送门 显然考虑 $dp$,设 $f[i]$ 表示前 $i$ 个牧场都被控制的最小代价 那么枚举所有 $j<i$ ,$f[i]=f[j]+val[i][j]+A[i]$ $val[i][j]$ ...
- QRegExp
这段代码会越界,百思不得七姐(过了N久时间 之后^^)原来是把i写成了1 --! //#if 0 QRegExp re1("AT+CGATT?"); QRegExp re2(&q ...
- Python下使用 redis数据库
初识Rdeis数据库 简介 redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zs ...
- Vivado 的IP:Global 和 Out-Of-Context选项问题
在Vivado定制IP的时候,或者在IP Catalog中双击一个IP,不论该IP是我们自己添加到工程的自定义IP,还是Vivado自己带的IP,选择"Customize IP"后 ...
- Shiro入门指引
最近项目中用到Shiro,专门对其研究了一番,颇有收获,以下是笔者最近写的博客,希望对大家入门有所帮助. Shiro入门资源整理 Shiro在SpringBoot中的使用 Shiro源码解析-登录篇 ...
- $bzoj1016-JSOI2008$ 最小生成树计数 最小生成树 $dfs/matrix-tree$定理
题面描述 现在给出了一个简单无向加权图.你不满足于求出这个图的最小生成树,而希望知道这个图中有多少个不同的最小生成树.(如果两颗最小生成树中至少有一条边不同,则这两个最小生成树就是不同的).由于不同的 ...
- gVim安装vim-template插件后提示Undefined variable vim_template_subtype/Press ENTER or type command to continue
Win7 64位 gVim:version 8.1.1234 vim-template:github链接 安装方式: 直接下载master的zip压缩包,解压后放入本地gVim安装目录的plugin, ...
- Java框架-mybatis03使用注解实现mybatis
1.面向接口编程: 好处:扩展性好,分层开发中,上层不用管具体的实现,都遵循共同的标准,使得开发变得容易.规范性更好 2.注解的实现 a)编写Dao接口 public interface UserDa ...
- Robot Framework的安装、更新与卸载
Robot Framework的安装.更新与卸载 一,安装RF前的准备 一般就三种执行环境 Python, Jython (JVM) 和 IronPython (.NET): 安装python: #T ...
- 011-filter模板
1 模板一 package ${enclosing_package}; import java.io.IOException; import javax.servlet.FilterChain; im ...