08 分布式计算MapReduce--词频统计
def getText():
txt=open("D:\\test.txt","r").read()
txt=txt.lower()
punctuation = r"""!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~“”?,!【】()、。:;’‘……¥·"""
for ch in punctuation:
txt=txt.replace(ch,"")
return txt
hamletTxt=getText()
words=hamletTxt.split()
counts={}
for word in words:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(100):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words=line.split()
for word in words:
print("{}\t{}".format(word,1))
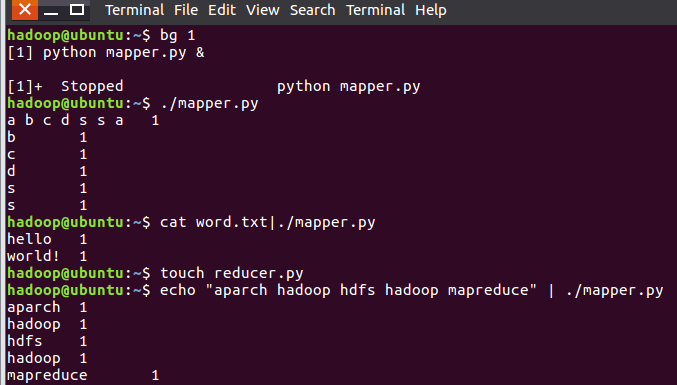
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print "%s\t%s" % (current_word, current_count)
current_count = count
current_word = word
if word == current_word:
print "%s\t%s" % (current_word, current_count)

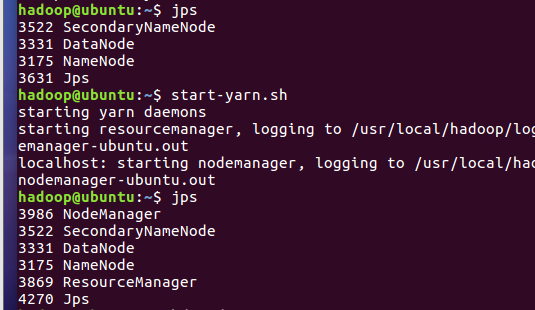
2.3分布式运行自带词频统计示例
- 启动HDFS与YARN
- 准备待处理文件
- 上传HDFS

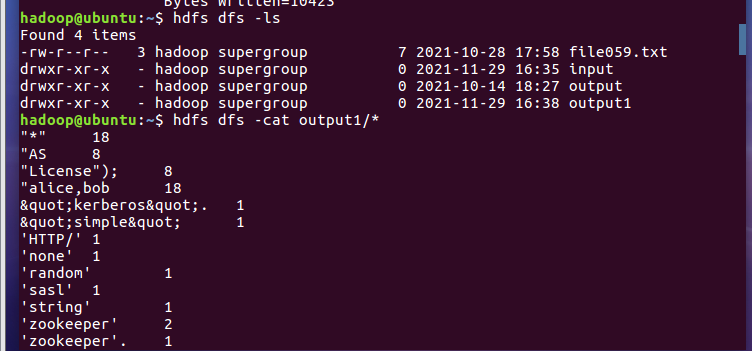
- 运行hadoop-mapreduce-examples-2.7.1.jar

- 查看结果
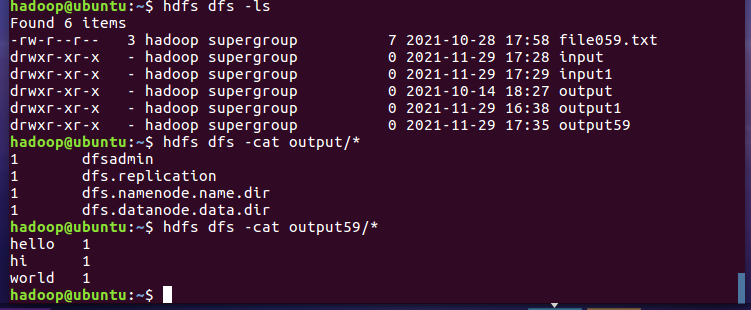
2.4 分布式运行自写的词频统计
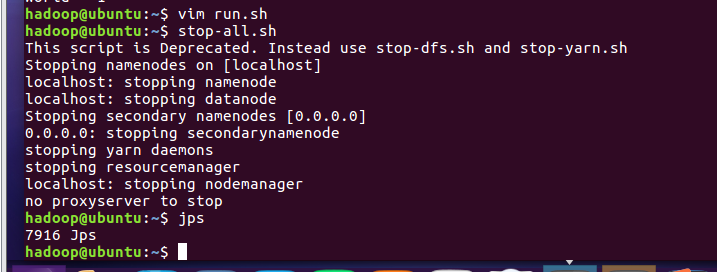
- 停止HDFS与YARN

08 分布式计算MapReduce--词频统计的更多相关文章
- MapReduce词频统计
自定义Mapper实现 import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; impor ...
- MapReduce实现词频统计
问题描述:现在有n个文本文件,使用MapReduce的方法实现词频统计. 附上统计词频的关键代码,首先是一个通用的MapReduce模块: class MapReduce: __doc__ = ''' ...
- Hadoop之词频统计小实验
声明: 1)本文由我原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Ubuntu操作系统,hadoop1-2-1,jdk1.8.0. 3)统计词频工作在单节点的伪分布上,至于真正实 ...
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- Hive简单编程实践-词频统计
一.使用MapReduce的方式进行词频统计 (1)在HDFS用户目录下创建input文件夹 hdfs dfs -mkdir input 注意:林子雨老师的博客(http://dblab.xmu.ed ...
- hive进行词频统计
统计文件信息: $ /opt/cdh-5.3.6/hadoop-2.5.0/bin/hdfs dfs -text /user/hadoop/wordcount/input/wc.input hadoo ...
- Hadoop的改进实验(中文分词词频统计及英文词频统计)(4/4)
声明: 1)本文由我bitpeach原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Windows系统下的百度云(联网),和Ubuntu系统的hadoop1-2-1(自己提前配好).如不 ...
- 初学Hadoop之中文词频统计
1.安装eclipse 准备 eclipse-dsl-luna-SR2-linux-gtk-x86_64.tar.gz 安装 1.解压文件. 2.创建图标. ln -s /opt/eclipse/ec ...
- 初学Hadoop之WordCount词频统计
1.WordCount源码 将源码文件WordCount.java放到Hadoop2.6.0文件夹中. import java.io.IOException; import java.util.Str ...
随机推荐
- 链路状态通告类型知识学习总结,LSA(Link State Advertisement)
链路状态通告类型知识总结,LSA(Link State Advertisement) 一.相关解释,个人相关看法: OSPF是通过LSA数据报文来联系关联路由器,交换信息,同步数据,在此基础上,各路由 ...
- Excel比较两列是否相等
通常的方式: 先将两列排序 通过判定如 =A1=B1 或者ctrl + \ (mac 是 command) 可以定位到差异的那行
- js 自定义可编辑table并获取输入值
1.js加载table,tabid为abc. jsp: <table id="abc"></table> js:var tr_tr = "&quo ...
- 实验室服务器运维踩坑o.0
先说背景:实验室新配了一台Dell T640服务器,双3090, 512G内存, 5 x 8T硬盘(RAID5),2 x 1T固态(RAID1),配置很够用但就是搭建运维踩了很多坑,以下是主要完成的几 ...
- Python发送飞书消息
#!/usr/bin/python3.8 # -*- coding:UTF-8 -*- import os, sys sys.path.append(os.path.dirname(os.path.a ...
- K8S中pod和container的资源管理:CPU和Memory
K8S中创建pod时,可以显示地指明包含的container的资源需求(resouce request和resource limit),通常是CPU和Memory(RAM). kube-schedul ...
- SAP管理员SAP*和DDIC被锁定后如何解锁或重置密码
SAP*初始化密码是06071992或passDDIC默认密码为19920706 环境信息:win server2003,SQL Server2008 R2 账号信息存在于数据库usr02表中,1.删 ...
- 转载安卓或苹果手机获取URL scheme方法
首先,打开支付宝,来到需要抓取的小程序页面.此处以上海的随申码为例演示,打开随申办小程序,点击顶部的「随申码」按钮进入页面. 可以看出这个一个二级页面,如果想要使用 URL Scheme 一键访问,同 ...
- unity shader ide
Shader Languages support for vs Code https://marketplace.visualstudio.com/items?itemName=slevesque.s ...
- h5项目
h5项目,用vue3,用vite搭建就好,是一个新的项目. 接口还在开发,可以用mock模拟. 现有信息:接口url,ui-url,原型url(各部分的交互关系)