初学Hadoop之WordCount词频统计
1、WordCount源码
将源码文件WordCount.java放到Hadoop2.6.0文件夹中。
import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2、编译源码
$ bin/hadoop com.sun.tools.javac.Main WordCount.java #将WordCount.java编译成三个.class文件
$ jar cf wc.jar WordCount*.class #将三个.class文件打包成jar文件
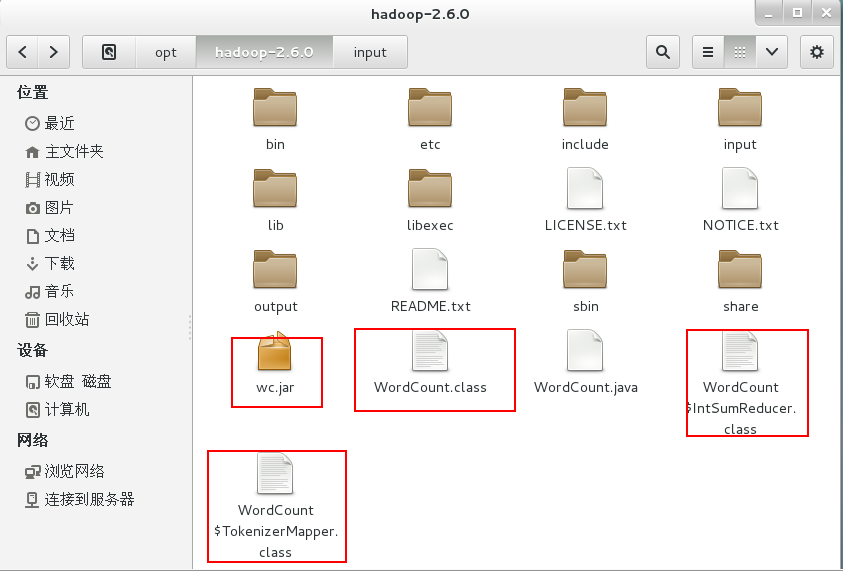
3、运行
新建input文件夹,用于存放需要统计的文本。
cd /opt/hadoop-2.6.0
mkdir input
复制hadoop-2.6.0文件夹下的txt文件到input文件夹下。
cp *.txt /opt/hadoop-2.6.0/input
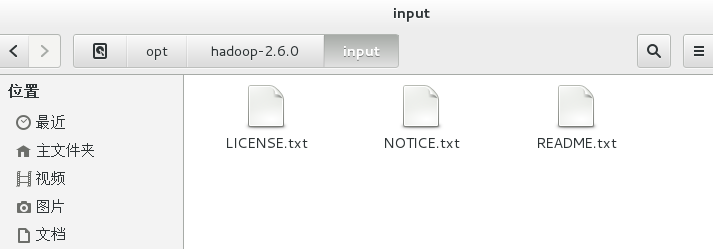
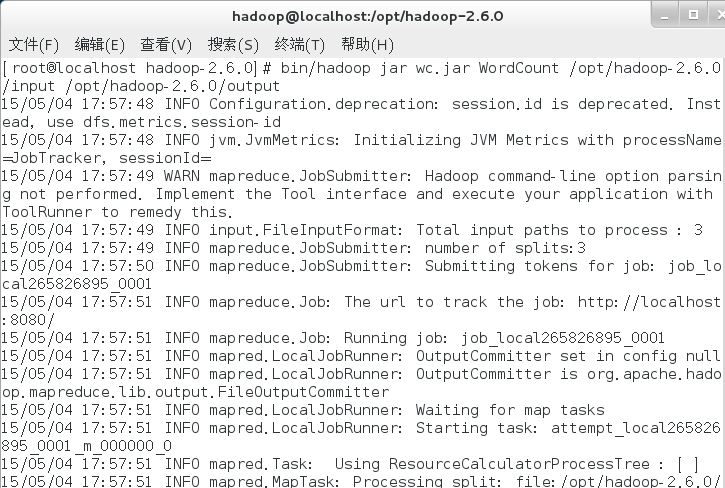
运行命令。
bin/hadoop jar wc.jar WordCount /opt/hadoop-2.6.0/input /opt/hadoop-2.6.0/output #自动生成output文件夹,用于存放分词统计结果。
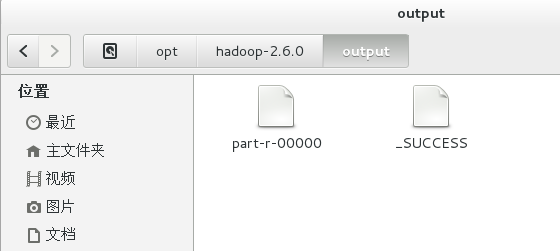
4、查看结果
bin/hdfs dfs -cat /opt/hadoop-2.6.0/output/part-r-00000
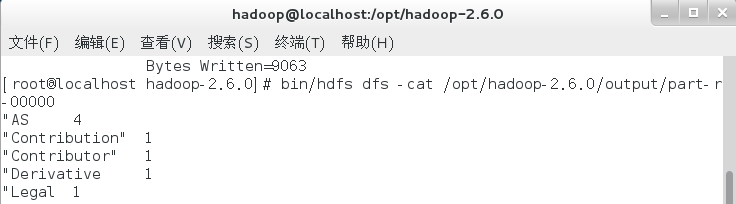
至此,WordCount词频统计运行成功,Hadoop单机模式环境搭建成功。
初学Hadoop之WordCount词频统计的更多相关文章
- 初学Hadoop之中文词频统计
1.安装eclipse 准备 eclipse-dsl-luna-SR2-linux-gtk-x86_64.tar.gz 安装 1.解压文件. 2.创建图标. ln -s /opt/eclipse/ec ...
- Hadoop基础学习(一)分析、编写并执行WordCount词频统计程序
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/jiq408694711/article/details/34181439 前面已经在我的Ubuntu ...
- 使用HDFS完成wordcount词频统计
任务需求 统计HDFS上文件的wordcount,并将统计结果输出到HDFS 功能拆解 读取HDFS文件 业务处理(词频统计) 缓存处理结果 将结果输出到HDFS 数据准备 事先往HDFS上传需要进行 ...
- Eclipse上运行第一个Hadoop实例 - WordCount(单词统计程序)
需求 计算出文件中每个单词的频数.要求输出结果按照单词的字母顺序进行排序.每个单词和其频数占一行,单词和频数之间有间隔. 比如,输入两个文件,其一内容如下: hello world hello had ...
- 第六篇:Eclipse上运行第一个Hadoop实例 - WordCount(单词统计程序)
需求 计算出文件中每个单词的频数.要求输出结果按照单词的字母顺序进行排序.每个单词和其频数占一行,单词和频数之间有间隔. 比如,输入两个文件,其一内容如下: hello world hello had ...
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
- Hadoop之词频统计小实验
声明: 1)本文由我原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Ubuntu操作系统,hadoop1-2-1,jdk1.8.0. 3)统计词频工作在单节点的伪分布上,至于真正实 ...
- Hadoop的改进实验(中文分词词频统计及英文词频统计)(4/4)
声明: 1)本文由我bitpeach原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Windows系统下的百度云(联网),和Ubuntu系统的hadoop1-2-1(自己提前配好).如不 ...
- 词频统计小程序-WordCount.exe
一. 背景 最近顶哥为了完成学历提升学业中的小作业,做了一个词频统计的.exe小程序.因为当时做的时候网上的比较少,因此顶哥决定把自己拙略的作品发出来给需要的人提供一种思路,希望各位看官不要dis ...
随机推荐
- Agreement has been updated--Edit Phone Number最便捷解决办法(不需要安全提示问题和双重认证)
2018年06月04日亲测有效: CSDN博客跳转网址:
- Balance(Stack)
栈的运用 mooc视频连接 #include <iostream> using namespace std; ]; ; void Push(char c) { ) { Top = ; S[ ...
- 关于Java中SQL语句的拼接规则
实现目标语句是这个注意,这里的java变量是idd int idd; String sql = "SELECT id, piUrl FROM picinfos WHERE id BETWEE ...
- pycharm 不显示代码提示
1.检查是否代码本身有问题. 2.检查代码提示是否成功开启. 3.检查IDE省电模式是否关闭状态. 4.使用快捷键:ctrl+j.ctrl+space.alt+/ 其他(不能安装): 1.检查是否Py ...
- 老男孩Day10作业:主机管理程序
一.作业需求: 1, 运行程序列出主机组或者主机列表 2,选择指定主机或主机组 3,选择主机或主机组传送文件(上传/下载) 4,充分使用多线程或多进程 5,不同主机的用户名,密码,端口可以不同 6,可 ...
- SDUT OJ 数据结构实验之二叉树四:(先序中序)还原二叉树
数据结构实验之二叉树四:(先序中序)还原二叉树 Time Limit: 1000 ms Memory Limit: 65536 KiB Submit Statistic Discuss Problem ...
- SDUT OJ 数据结构实验之链表八:Farey序列
数据结构实验之链表八:Farey序列 Time Limit: 10 ms Memory Limit: 600 KiB Submit Statistic Discuss Problem Descript ...
- Navicat Premium 12破解激活
下载Navicat Premium 12并安装: 蓝奏云下载:Navicat Premium 12注册机 链接:https://pan.baidu.com/s/1mN-urlh--SX1vbq7h ...
- redis中使用lua脚本
lua脚本 Lua是一个高效的轻量级脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能 使用脚本的好处 1.减少网络开销,在Lua脚 ...
- ASP.NET中MD5的加密方式很简单
在ASP.NET中MD5的加密方式很简单,代码如下: FormsAuthentication.HashPasswordForStoringInConfigFile(str, "MD5&quo ...