08 分布式计算MapReduce--词频统计
def getText():
txt=open("D:\\test.txt","r").read()
txt=txt.lower()
punctuation = r"""!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~“”?,!【】()、。:;’‘……¥·"""
for ch in punctuation:
txt=txt.replace(ch,"")
return txt
hamletTxt=getText()
words=hamletTxt.split()
counts={}
for word in words:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(100):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words=line.split()
for word in words:
print("{}\t{}".format(word,1))
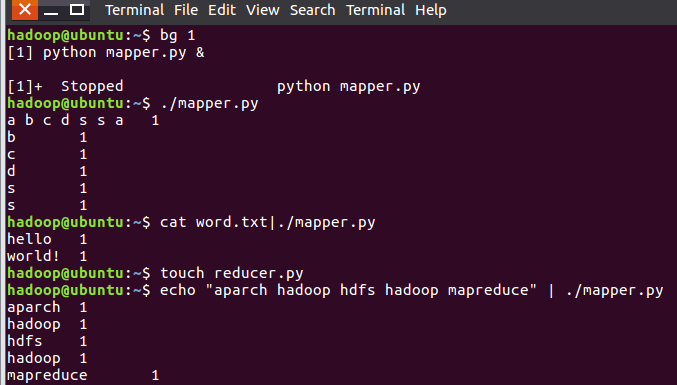
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print "%s\t%s" % (current_word, current_count)
current_count = count
current_word = word
if word == current_word:
print "%s\t%s" % (current_word, current_count)

2.3分布式运行自带词频统计示例
- 启动HDFS与YARN
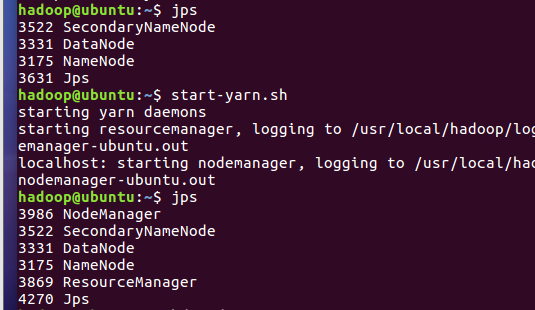
- 准备待处理文件
- 上传HDFS

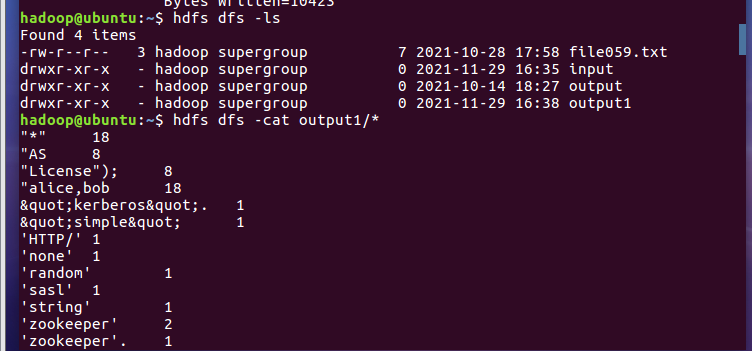
- 运行hadoop-mapreduce-examples-2.7.1.jar

- 查看结果
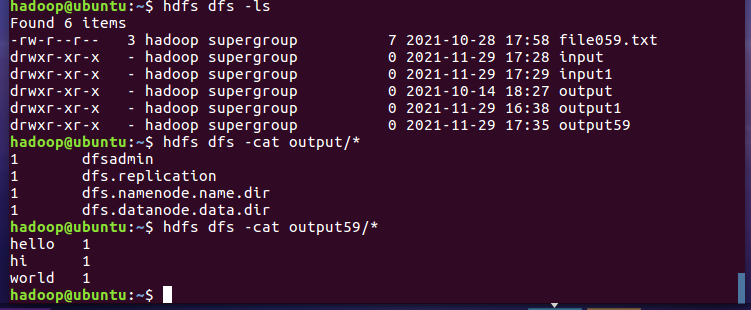
2.4 分布式运行自写的词频统计
- 停止HDFS与YARN

08 分布式计算MapReduce--词频统计的更多相关文章
- MapReduce词频统计
自定义Mapper实现 import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; impor ...
- MapReduce实现词频统计
问题描述:现在有n个文本文件,使用MapReduce的方法实现词频统计. 附上统计词频的关键代码,首先是一个通用的MapReduce模块: class MapReduce: __doc__ = ''' ...
- Hadoop之词频统计小实验
声明: 1)本文由我原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Ubuntu操作系统,hadoop1-2-1,jdk1.8.0. 3)统计词频工作在单节点的伪分布上,至于真正实 ...
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- Hive简单编程实践-词频统计
一.使用MapReduce的方式进行词频统计 (1)在HDFS用户目录下创建input文件夹 hdfs dfs -mkdir input 注意:林子雨老师的博客(http://dblab.xmu.ed ...
- hive进行词频统计
统计文件信息: $ /opt/cdh-5.3.6/hadoop-2.5.0/bin/hdfs dfs -text /user/hadoop/wordcount/input/wc.input hadoo ...
- Hadoop的改进实验(中文分词词频统计及英文词频统计)(4/4)
声明: 1)本文由我bitpeach原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Windows系统下的百度云(联网),和Ubuntu系统的hadoop1-2-1(自己提前配好).如不 ...
- 初学Hadoop之中文词频统计
1.安装eclipse 准备 eclipse-dsl-luna-SR2-linux-gtk-x86_64.tar.gz 安装 1.解压文件. 2.创建图标. ln -s /opt/eclipse/ec ...
- 初学Hadoop之WordCount词频统计
1.WordCount源码 将源码文件WordCount.java放到Hadoop2.6.0文件夹中. import java.io.IOException; import java.util.Str ...
随机推荐
- nmap扫描结果保存 xml to html for windows
首先 Nmap扫描443端口并保存为xml报告输出 nmap -T5 -Pn -p 443 -iL C:\Users\loki\Desktop\443_Scan.txt -oX C:\Users\lo ...
- matlab画图之plot画折线图
Matlab绘制折线图 使用plot(x,y)函数创建折线图时,x,y有以下要求: ①如果 X 和 Y 都是向量,则它们的长度必须相同.plot 函数绘制 Y 对 X 的图. ②如果 X 和 Y 均为 ...
- linux 网络操作 route iptables ufw
linux 网络操作 route iptables ufw sudo ufw status sudo ufw allow ssh sudo ufw allow http sudo ufw deny h ...
- Mac下Virtual Box 6.1 Host-Only 网络配置 没有虚拟网卡
Virtual Box 6.1 mac下 Virtual Box Host-Only 没有 vboxnet0 点击 tools -> 右边的三杆,点 Network 可以添加,修改,删除 虚拟 ...
- password_encryption_type 和 pg_hba.conf 不匹配导致用户连不上
# 问题概述xxx客户新上一套opengauss数据库,在测试中用户输入正确的密码,提示用户密码错误,导致用户被锁# 问题原因password_encryption_type 和 pg_hba.con ...
- drf从入门到飞升仙界 04
序列化类常用字段和字段参数 常用字段类 #1 BooleanField BooleanField() #2 NullBooleanField NullBooleanField() #3 CharFie ...
- vue页面多表单验证保存
页面中有多个表单需要验证,可以使用以下方法: export default { data: { return { addOrEditVo: { name: '', description: '', a ...
- 在项目中配置proxy 解决调试过程中的跨域问题
- 语言-页面-模板-Velocity
Velocity教程 - 简书 (jianshu.com) Velocity模板引擎详解 - Velocity 教程 | 编程字典 (codingdict.com) Velocity模板(VM)语言介 ...
- vue中key
使用key维护列表的状态 当列表的数据变化时,默认情况下,vue尽可能的服用已存在的DOM元素,从而提升渲染的性能.但这种默认的性能优化策略,会导致由状态的列表无法被正确更新. key的使用注意事项: ...