日爬百万数据的域名限制、url的清洗和管理
一、域名去重
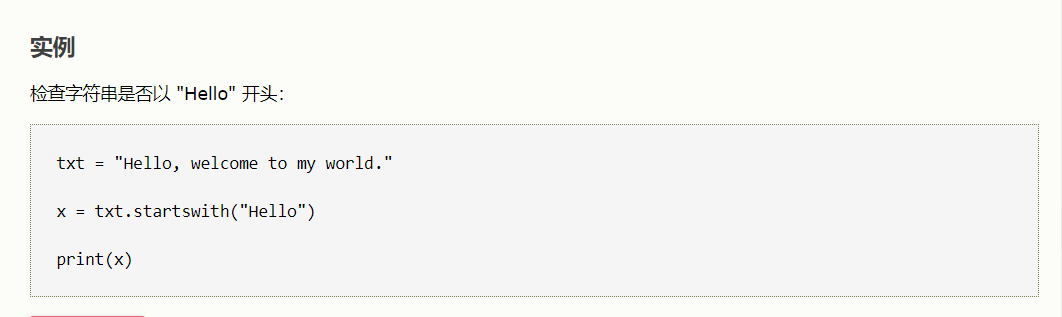
1、检测开头:link.startswith('http')
txt = "Hello, welcome to my world."
x = txt.startswith("Hello")
print(x)
#如果字符串以指定的值开头,则 startswith() 方法返回 True,否则返回 False。
string.startswith(value, start, end)
2、tldextract模块准确获取域名和后缀
tldextract是一个第三方模块,意思就是Top Level Domain extract,即顶级域名提取
使用时 需要安装,命令如下
pip install tldextract
URL的结构,news.baidu.com 里面的news.baidu.com叫做host,它是注册域名baidu.com的子域名,而com就是顶级域名TLD。

tld = tldextract.extract(link)
if tld.domain == 'baidu':
continue
news_links.append(link)
参考链接:https://www.yuanrenxue.com/crawler/news-crawler.html
二、url的清洗
1、判断网页种类(静态网页?图片?等等的内容)
2、去除外部的链接(广告)
#Python find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
g_bin_postfix = set([
'exe', 'doc', 'docx', 'xls', 'xlsx', 'ppt', 'pptx',
'pdf',
'jpg', 'png', 'bmp', 'jpeg', 'gif',
'zip', 'rar', 'tar', 'bz2', '7z', 'gz',
'flv', 'mp4', 'avi', 'wmv', 'mkv',
'apk',
]) g_news_postfix = [
'.html?', '.htm?', '.shtml?',
'.shtm?',
] def clean_url(url):
# 1. 是否为合法的http url
if not url.startswith('http'):
return ''
# 2. 去掉静态化url后面的参数
for np in g_news_postfix:
p = url.find(np)
if p > -1:
p = url.find('?')
url = url[:p]
return url
# 3. 不下载二进制类内容的链接
up = urlparse.urlparse(url)
path = up.path
if not path:
path = '/'
postfix = path.split('.')[-1].lower()
if postfix in g_bin_postfix:
return '' # 4. 去掉标识流量来源的参数
# badquery = ['spm', 'utm_source', 'utm_source', 'utm_medium', 'utm_campaign']
good_queries = []
for query in up.query.split('&'):
qv = query.split('=')
if qv[0].startswith('spm') or qv[0].startswith('utm_'):
continue
if len(qv) == 1:
continue
good_queries.append(query)
query = '&'.join(good_queries)
url = urlparse.urlunparse((
up.scheme,
up.netloc,
path,
up.params,
query,
'' # crawler do not care fragment
))
return url
3、url的管理(urlpool)
mport pickle
import leveldb
import time
import urllib.parse as urlparse class UrlPool:
'''URL Pool for crawler to manage URLs
''' def __init__(self, pool_name):
self.name = pool_name
self.db = UrlDB(pool_name) self.waiting = {} # {host: set([urls]), } 按host分组,记录等待下载的URL
self.pending = {} # {url: pended_time, } 记录已被取出(self.pop())但还未被更新状态(正在下载)的URL
self.failure = {} # {url: times,} 记录失败的URL的次数
self.failure_threshold = 3
self.pending_threshold = 10 # pending的最大时间,过期要重新下载
self.waiting_count = 0 # self.waiting 字典里面的url的个数
self.max_hosts = ['', 0] # [host: url_count] 目前pool中url最多的host及其url数量
self.hub_pool = {} # {url: last_query_time, } 存放hub url
self.hub_refresh_span = 0
self.load_cache() def __del__(self):
self.dump_cache() def load_cache(self,):
path = self.name + '.pkl'
try:
with open(path, 'rb') as f:
self.waiting = pickle.load(f)
cc = [len(v) for k, v in self.waiting.items()]
print('saved pool loaded! urls:', sum(cc))
except:
pass def dump_cache(self):
path = self.name + '.pkl'
try:
with open(path, 'wb') as f:
pickle.dump(self.waiting, f)
print('self.waiting saved!')
except:
pass def set_hubs(self, urls, hub_refresh_span):
self.hub_refresh_span = hub_refresh_span
self.hub_pool = {}
for url in urls:
self.hub_pool[url] = 0 def set_status(self, url, status_code):
if url in self.pending:
self.pending.pop(url) if status_code == 200:
self.db.set_success(url)
return
if status_code == 404:
self.db.set_failure(url)
return
if url in self.failure:
self.failure[url] += 1
if self.failure[url] > self.failure_threshold:
self.db.set_failure(url)
self.failure.pop(url)
else:
self.add(url)
else:
self.failure[url] = 1
self.add(url) def push_to_pool(self, url):
host = urlparse.urlparse(url).netloc
if not host or '.' not in host:
print('try to push_to_pool with bad url:', url, ', len of ur:', len(url))
return False
if host in self.waiting:
if url in self.waiting[host]:
return True
self.waiting[host].add(url)
if len(self.waiting[host]) > self.max_hosts[1]:
self.max_hosts[1] = len(self.waiting[host])
self.max_hosts[0] = host
else:
self.waiting[host] = set([url])
self.waiting_count += 1
return True def add(self, url, always=False):
if always:
return self.push_to_pool(url)
pended_time = self.pending.get(url, 0)
if time.time() - pended_time < self.pending_threshold:
print('being downloading:', url)
return
if self.db.has(url):
return
if pended_time:
self.pending.pop(url)
return self.push_to_pool(url) def addmany(self, urls, always=False):
if isinstance(urls, str):
print('urls is a str !!!!', urls)
self.add(urls, always)
else:
for url in urls:
self.add(url, always) def pop(self, count, hub_percent=50):
print('\n\tmax of host:', self.max_hosts) # 取出的url有两种类型:hub=1, 普通=0
url_attr_url = 0
url_attr_hub = 1
# 1. 首先取出hub,保证获取hub里面的最新url.
hubs = {}
hub_count = count * hub_percent // 100
for hub in self.hub_pool:
span = time.time() - self.hub_pool[hub]
if span < self.hub_refresh_span:
continue
hubs[hub] = url_attr_hub # 1 means hub-url
self.hub_pool[hub] = time.time()
if len(hubs) >= hub_count:
break # 2. 再取出普通url
left_count = count - len(hubs)
urls = {}
for host in self.waiting:
if not self.waiting[host]:
continue
url = self.waiting[host].pop()
urls[url] = url_attr_url
self.pending[url] = time.time()
if self.max_hosts[0] == host:
self.max_hosts[1] -= 1
if len(urls) >= left_count:
break
self.waiting_count -= len(urls)
print('To pop:%s, hubs: %s, urls: %s, hosts:%s' % (count, len(hubs), len(urls), len(self.waiting)))
urls.update(hubs)
return urls def size(self,):
return self.waiting_count def empty(self,):
return self.waiting_count == 0
来自猿人学官网
日爬百万数据的域名限制、url的清洗和管理的更多相关文章
- scrapy爬取数据的基本流程及url地址拼接
说明:初学者,整理后方便能及时完善,冗余之处请多提建议,感谢! 了解内容: Scrapy :抓取数据的爬虫框架 异步与非阻塞的区别 异步:指的是整个过程,中间如果是非阻塞的,那就是异步 ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 阿狸V任务页面爬取数据解析
需求: 爬取:https://v.taobao.com/v/content/video 所有主播详情页信息 首页分析 分析可以得知数据是通过ajax请求获取的. 分析请求头 详情页分析 详情页和详情页 ...
- web scraper——简单的爬取数据【二】
web scraper——安装[一] 在上文中我们已经安装好了web scraper现在我们来进行简单的爬取,就来爬取百度的实时热点吧. http://top.baidu.com/buzz?b=1&a ...
- 关于js渲染网页时爬取数据的思路和全过程(附源码)
于js渲染网页时爬取数据的思路 首先可以先去用requests库访问url来测试一下能不能拿到数据,如果能拿到那么就是一个普通的网页,如果出现403类的错误代码可以在requests.get()方法里 ...
- node.js爬取数据并定时发送HTML邮件
node.js是前端程序员不可不学的一个框架,我们可以通过它来爬取数据.发送邮件.存取数据等等.下面我们通过koa2框架简单的只有一个小爬虫并使用定时任务来发送小邮件! 首先我们先来看一下效果图 差不 ...
- 【Spider】使用CrawlSpider进行爬虫时,无法爬取数据,运行后很快结束,但没有报错
在学习<python爬虫开发与项目实践>的时候有一个关于CrawlSpider的例子,当我在运行时发现,没有爬取到任何数据,以下是我敲的源代码:import scrapyfrom UseS ...
- 【个人】爬虫实践,利用xpath方式爬取数据之爬取虾米音乐排行榜
实验网站:虾米音乐排行榜 网站地址:http://www.xiami.com/chart 难度系数:★☆☆☆☆ 依赖库:request.lxml的etree (安装lxml:pip install ...
- R中使用rvest爬取数据小试
总结R中使用 xpath 和 css selectors 获取标签内容(xpath功能强大,而CSS选择器通常语法比较简洁,运行速度更快些) 例:抓取下面标签的内容: <h3 class=&qu ...
- 如何分页爬取数据--beautisoup
'''本次爬取讲历史网站'''#!usr/bin/env python#-*- coding:utf-8 _*-"""@author:Hurrican@file: 分页爬 ...
随机推荐
- Beats:使用Elastic Stack对Nginx Web服务器监控
- Elasticsearch之集群角色类型
角色划分 在Elasticsearch中,有很多角色,常用的角色有如下: Master Node:主节点 Master eligible nodes:合格节点 Data Node:数据节点 Coord ...
- 用prometheus监控Nginx
GitHub上官方地址:https://github.com/knyar/nginx-lua-prometheus 告警规则地址:https://awesome-prometheus-alerts.g ...
- Gitlab注册Runner
1.先启动Gitlab,然后登陆进去,找到项目设置界面 2.部署Runner 这里采用docker安装的方式,也可以采用其他方式安装 # 创建docker镜像使用的数据卷 {20-07-16 16:2 ...
- Activate MFA报错:MFADevice entity at the same path and name already exists
MFA即:Multi-factor authentication (MFA) 今天在为自己账号Activate MFA时报错,如下图所示: Entity already exists This ent ...
- 驱动开发:内核通过PEB得到进程参数
PEB结构(Process Envirorment Block Structure)其中文名是进程环境块信息,进程环境块内部包含了进程运行的详细参数信息,每一个进程在运行后都会存在一个特有的PEB结构 ...
- 绝杀processOn,这款UML画图神器,阿里字节都用疯了,你还不知道?
大家好,我是陶朱公Boy,又和大家见面了. 前言 在文章开始前,想先问大家一个问题,大家平时在项目需求评审完后,是直接开始编码了呢?还是会先写详细设计文档,后再开始进行编码开发? ☆现实 这个时候可能 ...
- uoj221【NOI2016】循环之美
前面部分比较简单,就是无脑化式子,简单点讲好了. 首先肯定在\((x,y)=1\)时才考虑这个分数,要求纯循环的话,不妨猜猜结论,就是y必须和K互质.所以答案是\(\sum_{i=1}^n \sum_ ...
- 累加和为 K 的子数组问题
累加和为 K 的子数组问题 作者:Grey 原文地址: 博客园:累加和为 K 的子数组问题 CSDN:累加和为 K 的子数组问题 题目说明 数组全为正数,且每个数各不相同,求累加和为K的子数组组合有哪 ...
- HTML元素大全(1)
01.基础元素 <h1/2/3/4/5/6>标题 从大h1到小h6,块元素,有6级标题.是一种标题类语义标签,内置了字体.边距样式. 合理使用h标签,主要用于标题,不要为了加粗效果而随意使 ...