scrapy爬取数据的基本流程及url地址拼接
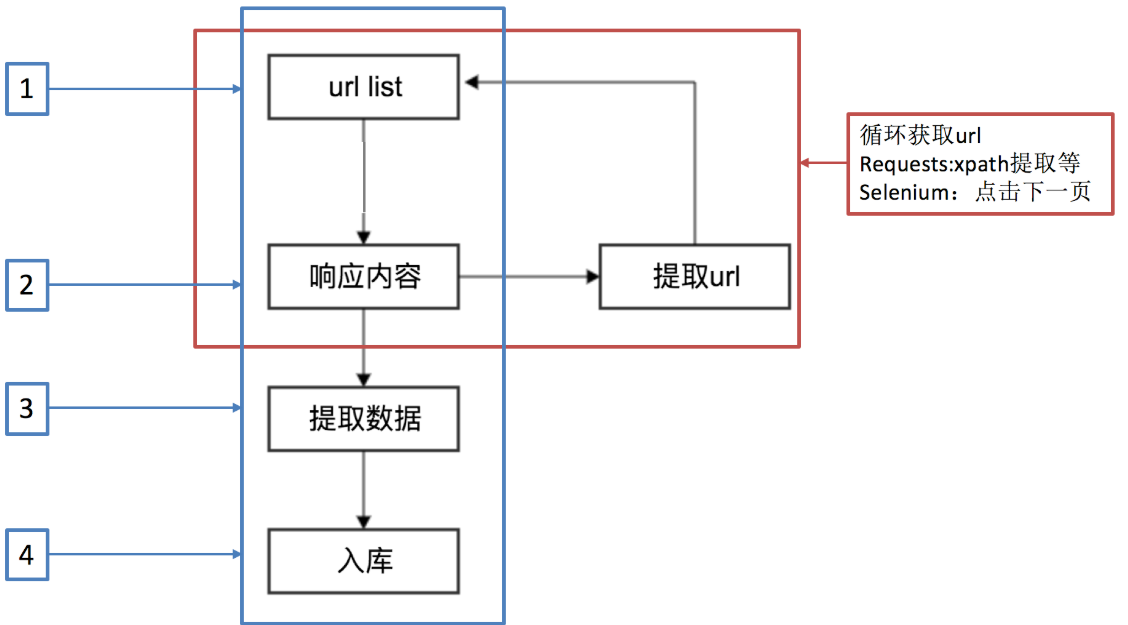

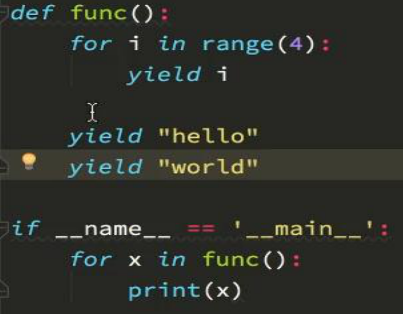

上面的代码应该改成:yield item
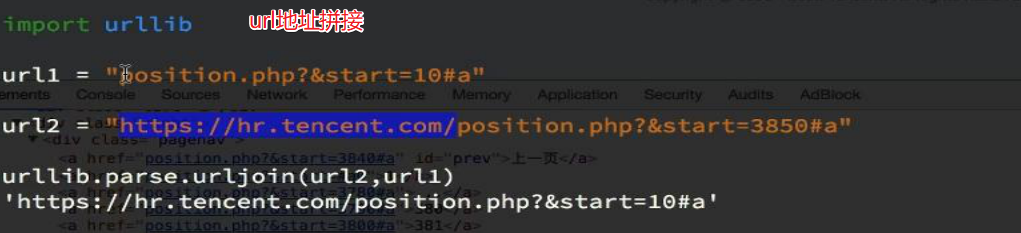
#主站链接 用来拼接
base_site = 'https://www.jpdd.com' def parse(self,response):
book_urls = response.xpath('//table[@class="p-list"]//a/@href').extract() for book_url in book_urls:
url = self.base_site + book_url
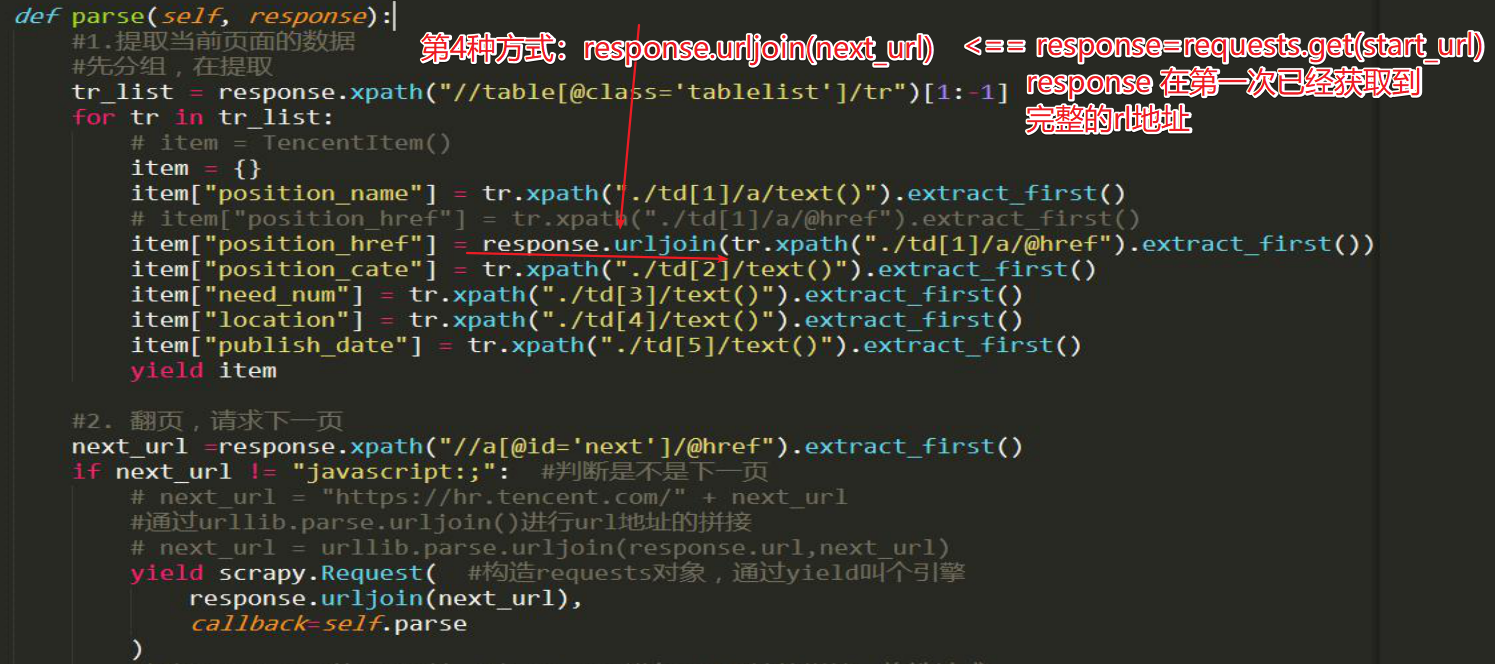
yield scrapy.Request(url, callback=self.getInfo) #获取下一页
next_page_url = self.base_site + response.xpath(
'//table[@class="p-name"]//a[contains(text(),"下一页")]/@href'
).extract()[0] yield scrapy.Request(next_page_url, callback=self.parse)
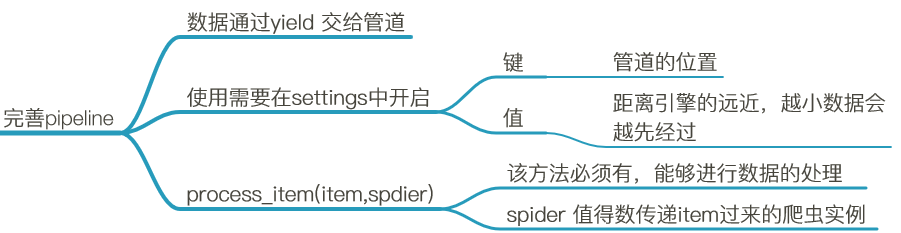


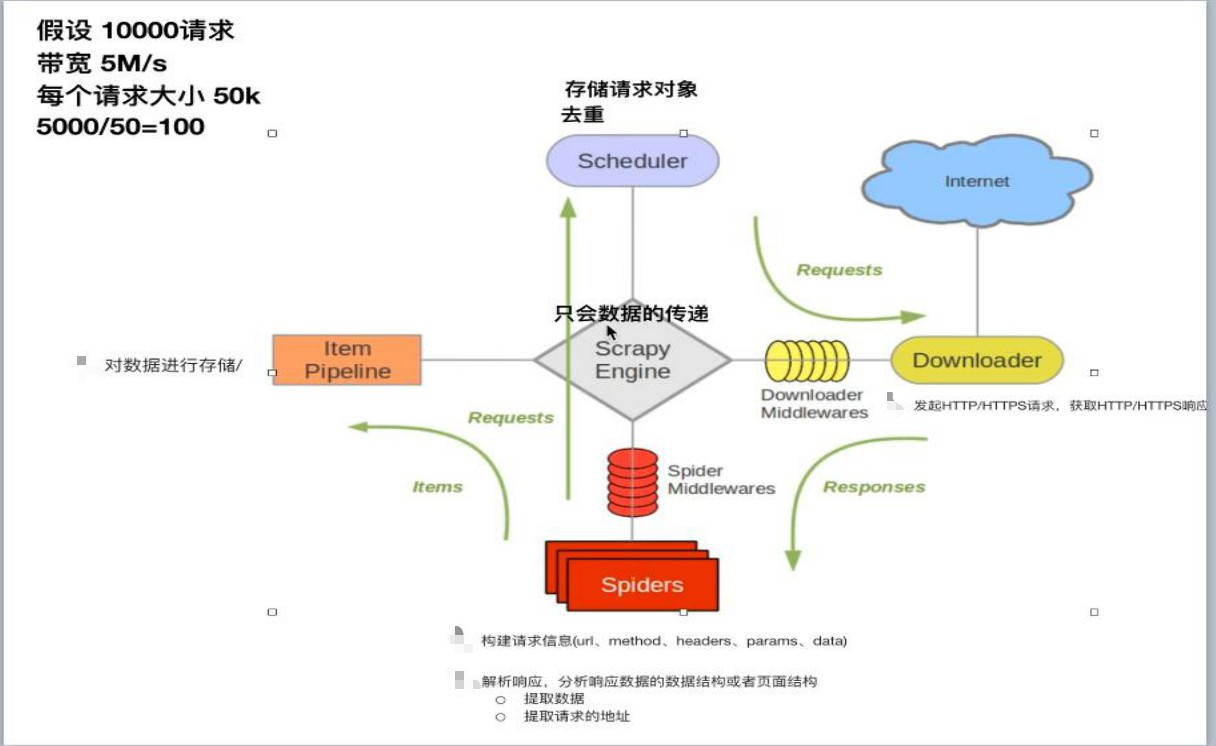
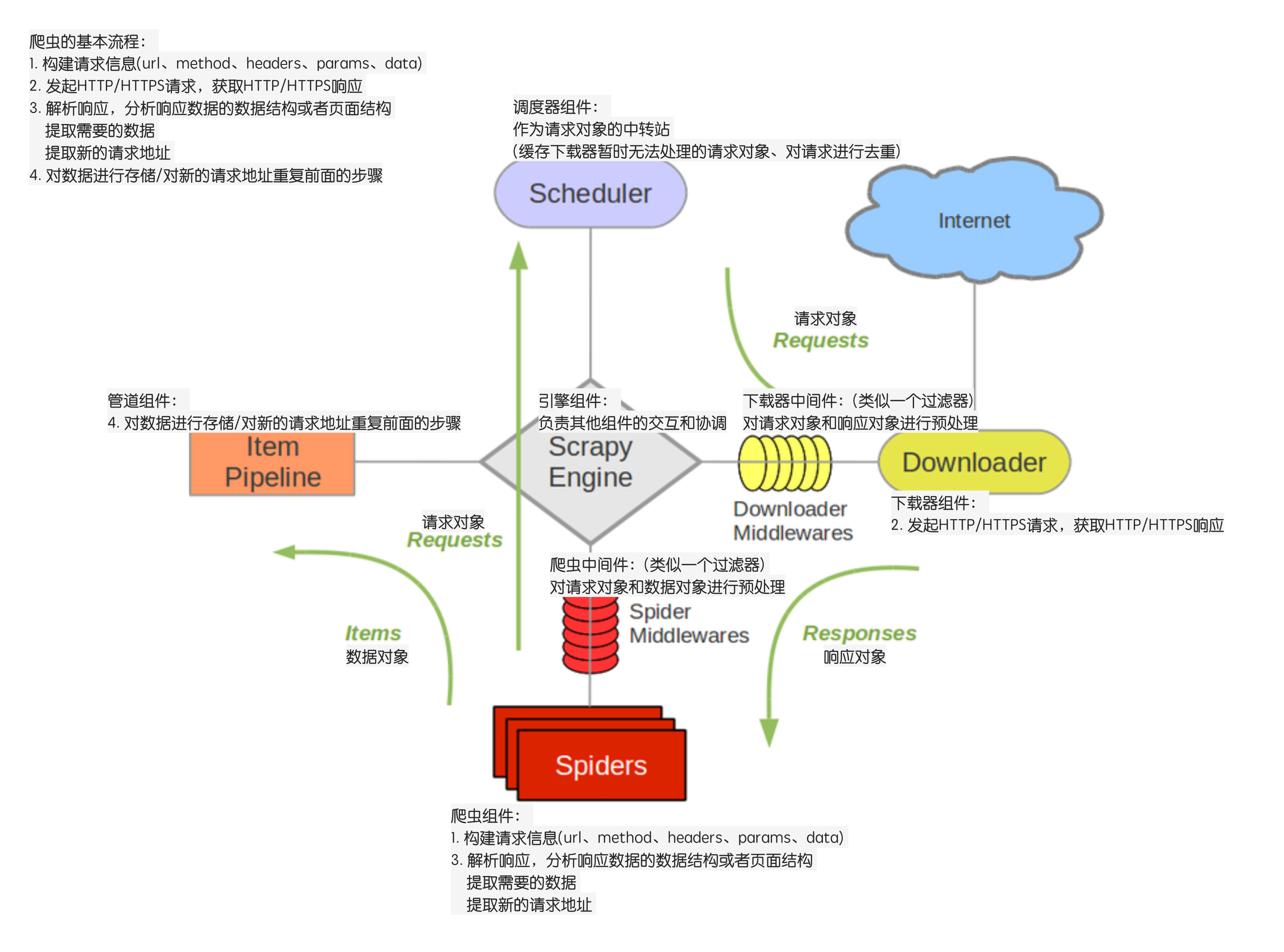
------数字越小,表示离引擎越近,数据越先经过处理,反之 。
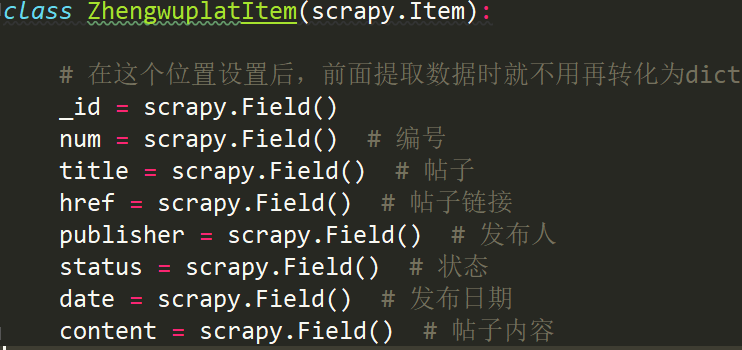
from yanguan.items import YanguanItem
item = YanguanItem() #实例化
参数说明:
括号中的参数为可选参数
callback:表示当前的url的响应交给哪个函数去处理
meta:实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等
dont_filter:默认会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动
scrapy爬取数据的基本流程及url地址拼接的更多相关文章
- 如何提升scrapy爬取数据的效率
在配置文件中修改相关参数: 增加并发 默认的scrapy开启的并发线程为32个,可以适当的进行增加,再配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100. ...
- 将scrapy爬取数据通过django入到SQLite数据库
1. 在django项目根目录位置创建scrapy项目,django_12是django项目,ABCkg是scrapy爬虫项目,app1是django的子应用 2.在Scrapy的settings.p ...
- python之scrapy爬取数据保存到mysql数据库
1.创建工程 scrapy startproject tencent 2.创建项目 scrapy genspider mahuateng 3.既然保存到数据库,自然要安装pymsql pip inst ...
- 42.scrapy爬取数据入库mongodb
scrapy爬虫采集数据存入mongodb采集效果如图: 1.首先开启服务切换到mongodb的bin目录下 命令:mongod --dbpath e:\data\db 另开黑窗口 命令:mongo. ...
- scrapy爬取数据进行数据库存储和本地存储
今天记录下scrapy将数据存储到本地和数据库中,不是不会写,因为小编每次都写觉得都一样,所以记录下,以后直接用就可以了-^o^- 1.本地存储 设置pipel ines.py class Ak17P ...
- scrapy爬取数据保存csv、mysql、mongodb、json
目录 前言 Items Pipelines 前言 用Scrapy进行数据的保存进行一个常用的方法进行解析 Items item 是我们保存数据的容器,其类似于 python 中的字典.使用 item ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 爬虫必知必会(6)_提升scrapy框架爬取数据的效率之配置篇
如何提升scrapy爬取数据的效率:只需要将如下五个步骤配置在配置文件中即可 增加并发:默认scrapy开启的并发线程为32个,可以适当进行增加.在settings配置文件中修改CONCURRENT_ ...
- 提高Scrapy爬取效率
1.增加并发: 默认scrapy开启的并发线程为32个,可以适当进行增加.在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100. 2.降低 ...
随机推荐
- 一个商品SKU是怎么生成的
首先说一说什么是SKU.......自己百度去... 类似京东上面,未来人类S5这个台笔记本(没错,我刚入手了) 都是S5这个型号,但是因为CPU,显卡,内存,硬盘等不同,价格也不一样.CPU,显卡, ...
- java与js互调 调用系统播放器
<?xml version="1.0" encoding="utf-8"?> <RelativeLayout xmlns:android=&q ...
- centos下安装nodejs及websocket
软件环境: VMware Workstation CentOS 6.5 NodeJS v0.12.5 安装过程: Step 1.确认服务器有nodejs编译及依赖相关软件,如果没有可通过运行以下命令安 ...
- 《机器学习实战》学习笔记第三章 —— 决策树之ID3、C4.5算法
主要内容: 一.决策树模型 二.信息与熵 三.信息增益与ID3算法 四.信息增益比与C4.5算法 五.决策树的剪枝 一.决策树模型 1.所谓决策树,就是根据实例的特征对实例进行划分的树形结构.其中有两 ...
- Codeforces Round #461 (Div. 2) B C D
题目链接:http://codeforces.com/contest/922 B. Magic Forest time limit per test 1 second memory limit per ...
- matlab字符串链接的三种方式
1.fprintf()函数: a='I love you,'; b='China'; c=123; fprintf('%s%s\n',a,b); fprintf('%s%s*****%d\n',a,b ...
- Mac系统存储-其他存储无故增大
解决办法:打开Finder:安全倾倒废纸篓就会减少很大一部分存储.
- .net中后台c#数组与前台js数组交互
第一步:定义cs数组 cs文件里后台程序中要有数组,这个数组要定义成公共的数组. public string[] lat = null; public string[] lng = null; ...
- densenet tensorflow 中文汉字手写识别
densenet 中文汉字手写识别,代码如下: import tensorflow as tf import os import random import math import tensorflo ...
- ACM学习历程—Hihocoder 1177 顺子(模拟 && 排序 && gcd)(hihoCoder挑战赛12)
时间限制:6000ms 单点时限:1000ms 内存限制:256MB 描述 你在赌场里玩梭哈,已经被发了4张牌,现在你想要知道发下一张牌后你得到顺子的概率是多少? 假定赌场使用的是一副牌,四种 ...