OpenCL设计优化(基于Intel FPGA SDK for OpenCL)
1、首先了解Intel FPGA SDK for OpenCL实现OpenCL的设计组件,包括:
kernels, global memory interconnect, local memory, loops 以及channels
(1) Kernels
Loops一般是Kernel优化的重点,尤其是nested loops。
OpenCL系统中每个kernel是通过一系列block表示的。Block主要由三部分:输入或循环输入节点,一组指令以及一个分支节点。若block中没有分支则没有输入与分支节点,输入或循环输入节点根据分支在block中的起始位置决定变量的初始值。block的余下部分包含可停顿以及不可停顿指令以及clusters。优化好的模型应该包含最少数量的可停顿指令,例如I/O或内存访问。
在block中不可停顿的指令被分组成多个clusters,以减小可停顿指令的握手开销。cluster包含入口/出口节点,且cluster是不可停顿的。可以在cluster的出口节点找到出口FIFO信息,在这种情况下,分支节点会通知下一个要跳转到的block。
只有当Kernel中不使用get_global_id()以及get_local_id()这种内置的work-item时,SDK才会将其编译为single work-item kernel,否则将其编译为NDRange kernel。
而offline compiler不能将NDRange中的loops进行pineline,但这些loops可以同时接受多个work-item。一个kernel可能包括多个循环,且每个都有嵌套循环。若将每个外部loop的nested loop的迭代总数制表,kernel的吞吐量一般会因此降低。而要有效率地执行NDRange Kernel,通常需要巨大数量的线程。
(2) Global memory interconnect
为读写访问最大化内存带宽的能力对高性能计算非常重要。OpenCL中存在用于读写全局存储器的各种类型的模块,称为负载储存单元(load-store units, LSUs)。
与GPU不同,FPGA可以构建最适合应用程序编译内存访问模式的任意自定义的LSU。选择最理想的LSU类型会为应用程序显著地提高设计性能。
(3) Local memory
Local Memory比较复杂,不同于GPU结构具有不同级别缓存的架构,FPGA在内部使用专用的内存块实现local memory。
Local Memory有以下特性:
对local memory的每次读写访问都要映射到一个端口;
可以将local memory中的内容划分为一个或多个存储体bank,以使每个存储体包含该local memory的数据子集。
一个存储体由一个或多个副本组成。Bank中的副本与其他的副本包含相同的数据。创建副本是为了有效的支持local memory的多次访问。每个副本都具有一个写端口与读端口,从而可以同时访问。如果local memory是double dumped,那么每个副本有四个物理端口,可以最多有三个读端口。
在kernel代码中,用 local 类型来声明local memory:
local int lmem[];
Intel SDK能够自己设定local memory的width, deph, banks, replication, private copies的数量, interconnect等。离线编译器可以分析访问模式然后优化local memory最小化访问竞争。
实现Kernel高效工作的关键是不停歇地访问内存。离线编译器始终尝试为Kernel中所有的local memory找到不停歇访问的配置方法,但由于kernel比较复杂,离线编译器可能没有足够的信息推断内存访问是否有冲突,那么就需要local interconnect仲裁寄存器来仲裁内存访问,会降低性能。
Local Memory Banks and Private Copis
默认local memory的存储体只在最小维度上起作用,多个存储体允许同时写入。在下面的例子中,循环中每个local memory的访问都有单独的的地址。离线编译器可以推断出访问模式,从而创建四个单独的存储体bank,四个独立bank允许对4个lmem同时访问,从而实现了无停顿的程序配置。此外,离线编译器为lmem创建了两个private copies,从而允许两个work-groups同时pipline运行。
#define BANK_SIZE 4
__attribute__(reqd_work_group_size(, , ))
kernel void bank_arb_consecutive_multidim(global int* restrict in, global int* restrict out)
{
local int lmem[][BANK_SIZE];
int gi = get_global_id();
int gs = get_global_size();
int li = get_local_id();
int ls = get_local_size();
int res = in[gi];
#progma unroll
for(int i = ; i < BANK_SIZE; i++)
{
lmem[((li + i ) & 0x7f)][i] = res + i;
res = res >> ;
}
int rdata = ;
barrier(CLK_GLOBAL_MEM_FENCE);
#progma unroll
for(int i = ; i < BANK_SIZE; i++)
{
rdata ^= lmem[(li + i) & 0x7f][i];
}
out[gi] = rdata;
return;
}
如果私有副本显著增加了设计area,考虑减少kernel中barrier的数量或增加max_work_group_size的值来减少SDK推断出的private copies的数量。
可以使用 __attribute__((numbanks(N)) 指定bank的数量。
若不希望在最小维度上进行存储,使用 bank_bits 指定存储字节。而通过使用 bank_bits 能够将memory中的数据分开存储在多个bank中,同时可以指定使用哪些地址位选择bank。下例中,使用第七位和第八位而不是最低的两个维度来进行bank存储。
#define BANK_SIZE 4
kernel void bank_arb_consecutive_multidim_origin (global int* restrict in,
global int* restrict out) {
local int a[BANK_SIZE][] __attribute__((bank_bits(,),bankwidth()));
int gi = get_global_id();
int li = get_local_id();
int res = in[gi];
#pragma unroll
for (int i = ; i < BANK_SIZE; i++) {
a[i][((li+i) & 0x7f)] = res + i;
res = res >> ;
}
int rdata = ;
barrier(CLK_GLOBAL_MEM_FENCE);
#pragma unroll
for (int i = ; i < BANK_SIZE; i++) {
rdata ^= a[i][((li+i) & 0x7f)];
}
out[gi] = rdata;
return;
}
Local Memory Replication
为了实现无停顿的程序配置,编译器可能复制一个local memory系统来增加可读端口的数量。对local memory的每个存储操作都是在每个副本上同时执行的,梅格副本都具有相同相同的数据,可以独立读取。这样增加了local memory系统可支持的同时读取操作的数量。
Double Pumping
通常来说,每个local memory 副本具有两个物理端口,而double pumping是的每个副本最多支持四个物理端口。
优点:可以增加可使用的物理端口;可能会通过减少复制操作从而减少RAM的使用。
缺点:与single pumping相比逻辑更复杂、延迟更高;有可能会降低kernel时钟频率
可以使用 __attribute __((singlepump)) 和 __attribute __((doublepump)) 来控制本地内存系统的pump配置。
以下代码示例说明了具有三个读取端口和三个写入端口的本地内存的实现。 脱机编译器启用了double pumping功能,并复制了本地内存三次,以实现无停顿内存配置。
#define BANK_SIZE 4
kernel void bank_arb_consecutive_multidim_origin (global int* restrict in,
global int* restrict out) {
local int a[BANK_SIZE][];
int gi = get_global_id();
int li = get_local_id();
int res = in[gi];
#pragma unroll 1
for (int i = ; i < BANK_SIZE; i++) {
a[i][li+i] = res + i;
a[gi][li+i] = res + i;
a[gi+i][li] = res + i;
res = res >> ;
}
int rdata = ;
barrier(CLK_GLOBAL_MEM_FENCE);
#pragma unroll 1
for (int i = ; i < BANK_SIZE; i++) {
rdata ^= a[i][li+i];
rdata += a[gi+i][li+i];
rdata += a[gi][li];
}
out[gi] = rdata;
return;
}
(4) Nested Loop
Intel® FPGA SDK for OpenCL的离线编译器由于循环迭代无法infer pipeline的执行,会导致外循环的迭代相对于随后的内循环可能是乱序的,因为对于不同的外循环迭代,内循环的迭代次数可能会有所不同。要解决无序的外循环迭代问题,需要设计上下限在外循环迭代之间不变的内循环。
通过使用 loop_coalesce 减少嵌套循环消耗的面积。当循环嵌套层数在三层以上时,要消耗更多的面积area,利用loop coalescing可以减小延迟,减小area。
(5) Loops in a Single Work-item Kernel
SDK离线编译器通过pipeline循环来优化单work-item 的kernel的性能。
单个work-item的kernel中循环的数据路径可以包含多个正在运行的迭代。 此行为与NDRange内核中的循环不同,NDRange内核的循环包含正在运行的多个工作项(而不是循环迭代)。 在最佳pipeline循环中,每个时钟周期都会启动一个新的循环迭代。 每个时钟周期启动一次循环迭代可最大化流水线效率并产生最佳性能。
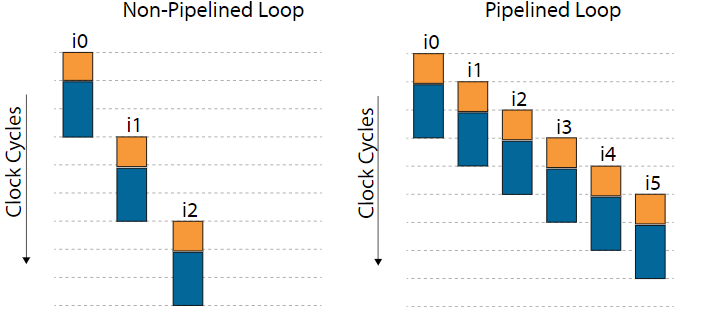
一次循环迭代与下一次之间的时钟周期数称为循环的启动间隔(initiation interval, II)。 最佳流水线循环的II值为1,因为每个时钟周期都会启动一个新的循环迭代。而SDK可能无法流水线化内核中的每个循环。 如果未对循环进行流水线处理,则直到上一次迭代执行完毕,循环迭代才能开始。 在这种情况下,一次在循环的数据路径中只有一个循环迭代处于活动状态。
在II启动间隔与最大频率之间trade-off权衡
有些情况下,离线编译器会以减小最大频率为代价使II启动间隔达到1。
循环依赖会影响循环的II启动间隔
一些情况下,loop是pipelined,但II启动间隔不是1。通常是loop的数据依赖或内存依赖引起的。
数据依赖是指循环迭代使用依赖于先前迭代的变量的情况。内存依赖是指在循环迭代中的内存访问无法完成,直到完成来自先前循环迭代的内存访问为止的情况。
循环推测
循环推测是一种优化技术,它通过允许在确定循环是否已经退出之前启动将来的迭代来启用更有效的循环pipeline。
循环融合
循环融合是一种编译器转换,其中两个相邻循环在相同索引范围内合并为一个循环。 此转换通常用于减少循环开销并提高运行时性能。
循环融合的条件:
能够融合的循环必须相邻;
循环必须具有相同的迭代计数;
每个循环必须具有一个入口和一个出口。 例如,不考虑包含break语句的循环进行融合。
循环必须没有负距离依赖关系。
(6) Channels
Intel® FPGA SDK for OpenCL™的通道实现提供了数据从一个kernel传递到另一个kernel的灵活方法,以提高性能。在kernel的代码中添加channel的关键字,例如:
channel long16 myCh __attribute__((depth()));
(7) Load-Store Units
SDK会生成许多不同类型的负载存储单元(LSU)。 对于某些类型的LSU,编译器可能会根据内存访问模式和其他内存属性来修改LSU行为和属性。
LSU类型(Best Practice Guide-3.7.1):
- Burst-Coalesced Load-Store Units
- Prefetching Load-Store Units
- Pipelined Load-Store Units
- Constant-Pipelined Load-Store Units
- Atomic-Pipelined Load-Store Units
LSU修饰符:
Cached
Write-Acknowledge(write-ack)
Nonaligned
Never-Stall
LSU的控制:
离线编译器允许通过一组内置调用来控制为全局存储器访问而生成的LSU的类型,可以使用这些调用加载和存储到全局存储器。
Load Built-ins
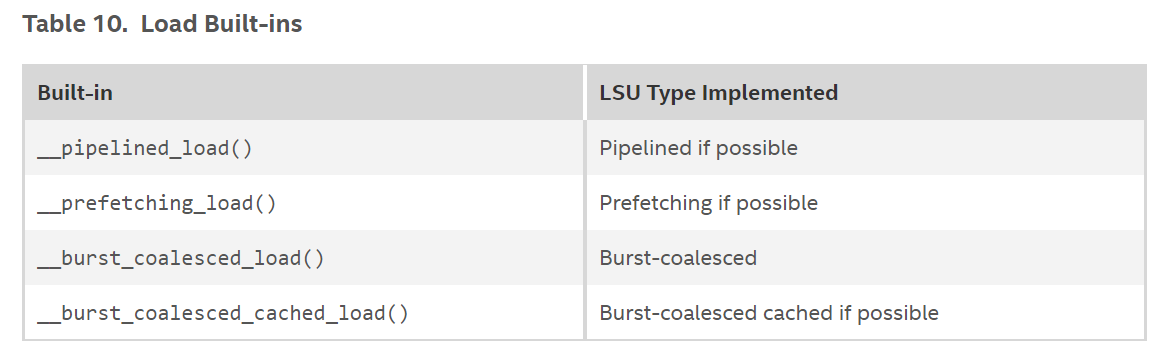
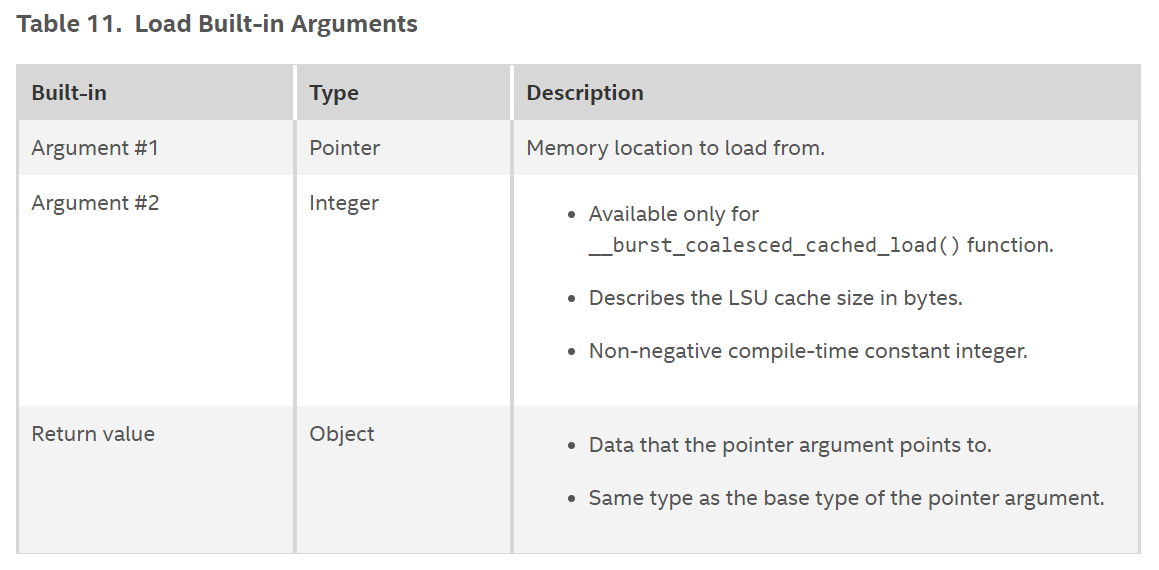
Load Built-in Arguments
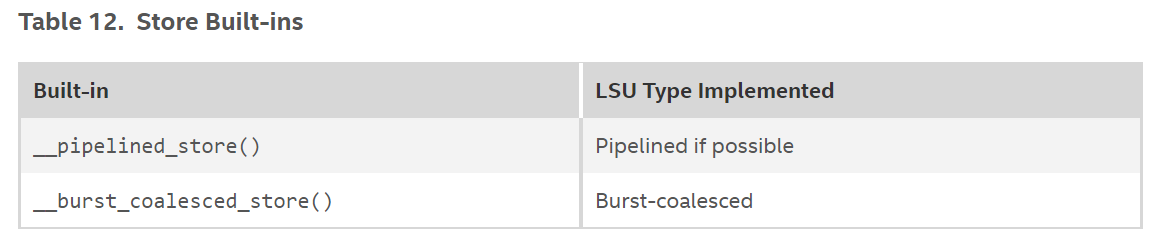
Store Built-ins
Store Built-in Arguments
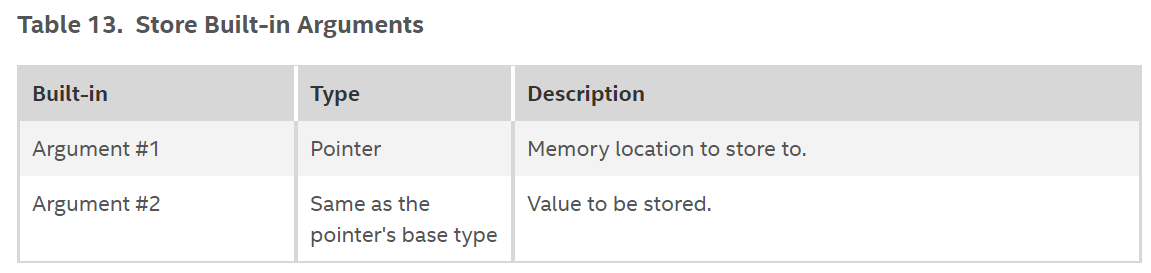
Example:
kernel void oclTest(global int * restrict in,
global int * restrict out) {
int i = get_global_id(); int a1 = __pipelined_load(in + *i+); // Uses a pipelined LSU
// Uses a burst-coalesced LSU with a cache of size 1024 bytes
int a2 = __burst_coalesced_cached_load(&in[*i+], );
int a3 = __prefetching_load(&in[*i+]); // Uses a prefetching LSU __burst_coalesced_store(&out[*i+], a3); // Uses a burst-coalesced LSU
}
Note:编译器不允许选择可能在请求上下文中导致功能上不正确的结果的LSU;Prefeching LSU在Intel®Stratix®10设备上不可用。
对于LSU使用时的选择:
可以根据对加载/存储站点的访问模式的了解或根据硅面积要求来决定LSU的类型。 以下是LSU按其面积需求的升序排列:
Pipelined LSU (load/store):区域有效,但可能比其他LSU慢。 如果受区域限制或访问方式不一定是连续的,则应使用此LSU。
Prefetching LSU (only for loads): 也是区域有效的,但对于完全连续的访问模式来说是完美的。 将其用于非连续访问模式会导致吞吐量下降,因此,仅当知道访问的地址严格连续时,才使用它。
Burst-coalesced LSU (load/store): 需求面积很大,但可以非常有效地处理连续的访问模式。 检查访问模式是否连续要付出代价。 如果可能,这种LSU动态地尝试将多个内核请求组合为一个跨越多个内存字的大burst。
Burst-coalesced cached LSU (only for loads): 最消耗面积,因为它包含LSU本地的额外缓存。 如果打算多次读取内存中的同一位置,尤其是在多个ND范围线程中,则使用这种LSU可以提高吞吐量。
2、OpenCL Kernel Design Best Practices设计的最佳做法
使用Intel® FPGA SDK for OpenCL™ 离线编译器,不需要调整kernel代码便可以将其最佳的适应于固定的硬件设备,而是离线编译器会根据kernel的要求自适应调整硬件的结构。
通常来说,应该先优化针对单个计算单元的kernel,之后累哦通过增加计算单元数量来拓展硬件以填充FPGA其余的部分,从而提升性能。Kernel的使用面积与硬件编译所需要的时间有关,因此为了避免硬件编译时间过长,首先要专注于优化kernel在单个计算单元上的性能。
要优化kernel的性能,主要包括数据处理以及内存访问优化。
a. 通过SDK的channel 或pipe来传输数据。为了提高kernel之间的数据传输效率,在kernel程序中使用channel通道拓展。 如果想利用通道功能,又想使用其他SDK运行kernel,则使用OpenCL pipes。
b. 展开循环。
c. 优化浮点运算。对于浮点操作,可以手动引导SDK的离线编译器进行优化,从而在硬件中创建更有效的pipeline结构并减少总体硬件使用率。
d. 分配对齐的内存。再分配与FPGA进行数据传输的主机端存储器时,存储器至少是64字节对齐的。
e. 使用或不用Padding来对齐结构。
f. 保持向量元素的相似结构。如果更新了向量的一个元素,那么更新这个向量的所有元素。
g. 避免指针混淆。尽量在指针参数中插入strict关键字。
h. 避免开销大的函数/功能。有些函数在FPGA中实现开销很大,可能会减低kernel的性能,或是需要大量硬件来实现。
i. 避免依赖于work-item id的后向分支。避免在kernel中包括任何与工作项ID相关的向后分支(即,循环中发生的分支),因为这会降低性能。
OpenCL设计优化(基于Intel FPGA SDK for OpenCL)的更多相关文章
- 基于INTEL FPGA硬浮点DSP实现卷积运算
概述 卷积是一种线性运算,其本质是滑动平均思想,广泛应用于图像滤波.而随着人工智能及深度学习的发展,卷积也在神经网络中发挥重要的作用,如卷积神经网络.本参考设计主要介绍如何基于INTEL 硬浮点的DS ...
- OpenCL Kernel设计优化
使用Intel® FPGA SDK for OpenCL™ 离线编译器,不需要调整kernel代码便可以将其最佳的适应于固定的硬件设备,而是离线编译器会根据kernel的要求自适应调整硬件的结构. 通 ...
- Getting Started with the Intel Media SDK
By Gael Hofemeier on March 19, 2015 Follow Gael on Twitter: @GaelHof Media SDK Developer’s Guide Med ...
- 优化基于FPGA的深度卷积神经网络的加速器设计
英文论文链接:http://cadlab.cs.ucla.edu/~cong/slides/fpga2015_chen.pdf 翻译:卜居 转载请注明出处:http://blog.csdn.net/k ...
- 关于INTEL FPGA设计工具DSP Builder
一段时间以来,MathWorks一直主张使用Matlab和Simulink开发工具进行基于模型的设计,因为好的设计技术使您能够在更短的时间内开发更高质量的复杂软件.基于模块的设计采用了数学和可视化的方 ...
- HBase最佳实践-列族设计优化
本文转自hbase.收藏学习下. 随着大数据的越来越普及,HBase也变得越来越流行.会用HBase现在已经变的并不困难,然而,怎么把它用的更好却并不简单.那怎么定义'用的好'呢?很简单,在保证系统稳 ...
- Web交互设计优化的简易check list
Web交互设计优化的简易check list 00 | 时间: 2011-02-11 | 28,842 Views 交互设计, 用户研究 “优化已有产品的体验”,这是用户体验相关岗位职责中常见的描 ...
- (数字IC)低功耗设计入门(六)——门级电路低功耗设计优化
三.门级电路低功耗设计优化 (1)门级电路的功耗优化综述 门级电路的功耗优化(Gate Level Power Optimization,简称GLPO)是从已经映射的门级网表开始,对设计进行功耗的优化 ...
- 基于Xilinx FPGA的视频图像采集系统
本篇要分享的是基于Xilinx FPGA的视频图像采集系统,使用摄像头采集图像数据,并没有用到SDRAM/DDR.这个工程使用的是OV7670 30w像素摄像头,用双口RAM做存储,显示窗口为320x ...
随机推荐
- SpringBoot + Vue + ElementUI 实现后台管理系统模板 -- 后端篇(五): 数据表设计、使用 jwt、redis、sms 工具类完善注册登录逻辑
(1) 相关博文地址: SpringBoot + Vue + ElementUI 实现后台管理系统模板 -- 前端篇(一):搭建基本环境:https://www.cnblogs.com/l-y-h/p ...
- 二、kafka 中央控制器、主题、分区、副本
集群和中央控制器 一个独立的Kafka服务器被称为broker.broker用来接收来自生产者的消息,为消息设置偏移量,并把消息保存到磁盘.换句话说,多个kafka实例组成kafka集群,每个实例(s ...
- day58 bootstrap效果无法显示
在学习bootstrap时直接复制官网的组件的时候,如果效果无法想官网一样显示,最大的可能是类库导入的顺序问题. 打开页面>检查>Console 我们会发现一条报错,导入的js需要jQue ...
- mysql常见数据类型
#常见的数据类型 /* 数值型: 整型 小数: 定点数 浮点数 字符型: 较短的文本:char.varchar 较长的文本:text.blob(较长的二进制数据) 日期型: */ #一.整型 /* 分 ...
- Python Ethical Hacking - KEYLOGGER(3)
Object-Oriented Programming Keylogger Classes Way of modeling program(blueprint). Logically group fu ...
- Web应用程序安全与风险
一.Web应用程序安全与风险 更多渗透测试相关内容请关注此地址:https://blog.csdn.net/weixin_45380284 1.web发展历程 静态内容阶段(HTML) CGI程序阶段 ...
- VMware虚拟机网络配置详解
VMware网络配置:三种网络模式简介 安装好虚拟机以后,在网络连接里面可以看到多了两块网卡: 其中VMnet1是虚拟机Host-only模式的网络接口,VMnet8是NAT模式的网络接口,这些后面会 ...
- python读取hdfs上的parquet文件方式
在使用python做大数据和机器学习处理过程中,首先需要读取hdfs数据,对于常用格式数据一般比较容易读取,parquet略微特殊.从hdfs上使用python获取parquet格式数据的方法(当然也 ...
- 用windbg查看dmp文件,定位bug位置
windbg + .dmp + .pdb + 源代码,可以看到是哪个代码崩溃的 设置符号文件所在路径 File->Symbol File Path... 在输入框中填入.pdb文件所在的文件夹路 ...
- Springboot(二)springboot之jsp支持
参考恒宇少年的博客:https://www.jianshu.com/p/90a84c814d0c springboot内部对jsp的支持并不是特别理想,而springboot推荐的视图是Thymele ...