机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化
1 数据无量纲化
在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”。
譬如梯度和矩阵为核心的算法中,譬如逻辑回归,支持向量机,神经网络,无量纲化可以加快求解速度;而在距离类模型,譬如K近邻,K-Means聚类中,
无量纲化可以帮我们提升模型精度,避免某一个取值范围特别大的特征对距离计算造成影响。(一个特例是决策树和树的集成算法们,对决策树我们不需要无量纲化,决策树可以把任意数据都处理得很好。)
数据的无量纲化可以是线性的,也可以是非线性的。线性的无量纲化包括中心化(Zero-centered或者Mean-subtraction)处理和缩放处理(Scale)。
中心化的本质是让所有记录减去一个固定值,即让数据样本数据平移到某个位置。缩放的本质是通过除以一个固定值,将数据固定在某个范围之中,取对数也算是一种缩放处理。
preprocessing.MinMaxScaler
当数据(x)按照最小值中心化后,再按极差(最大值 - 最小值)缩放,数据移动了最小值个单位,并且会被收敛到[0,1]之间,而这个过程,就叫做数据归一化(Normalization,又称Min-Max Scaling)。
注意,Normalization是归一化,不是正则化,真正的正则化是regularization,不是数据预处理的一种手段。归一化之后的数据服从正态分布,公式如下: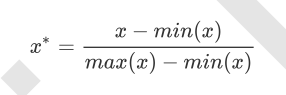
在sklearn当中,我们使用preprocessing.MinMaxScaler来实现这个功能。MinMaxScaler有一个重要参数,feature_range控制我们希望把数据压缩到的范围,默认是[0,1]。
from sklearn.preprocessing import MinMaxScaler data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]] #不太熟悉numpy的小伙伴,能够判断data的结构吗?
#如果换成表是什么样子?
import pandas as pd
pd.DataFrame(data) #实现归一化
scaler = MinMaxScaler() #实例化
scaler = scaler.fit(data) #fit,在这里本质是生成min(x)和max(x)
result = scaler.transform(data) #通过接口导出结果
result result_ = scaler.fit_transform(data) #训练和导出结果一步达成 scaler.inverse_transform(result) #将归一化后的结果逆转 #使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外的范围中 data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler(feature_range=[5,10]) #依然实例化
result = scaler.fit_transform(data) #fit_transform一步导出结果
result #当X中的特征数量非常多的时候,fit会报错并表示,数据量太大了我计算不了
#此时使用partial_fit作为训练接口
#scaler = scaler.partial_fit(data)
BONUS: 使用numpy来实现归一化
import numpy as np
X = np.array([[-1, 2], [-0.5, 6], [0, 10], [1, 18]]) #归一化
X_nor = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_nor #逆转归一化
X_returned = X_nor * (X.max(axis=0) - X.min(axis=0)) + X.min(axis=0)
X_returned
preprocessing.StandardScaler
当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分布),而这个过程,就叫做数据标准化(Standardization,又称Z-score normalization),公式如下:

from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]] scaler = StandardScaler() #实例化
scaler.fit(data) #fit,本质是生成均值和方差 scaler.mean_ #查看均值的属性mean_
scaler.var_ #查看方差的属性var_ x_std = scaler.transform(data) #通过接口导出结果 x_std.mean() #导出的结果是一个数组,用mean()查看均值
x_std.std() #用std()查看方差 scaler.fit_transform(data) #使用fit_transform(data)一步达成结果 scaler.inverse_transform(x_std) #使用inverse_transform逆转标准化
对于StandardScaler和MinMaxScaler来说,空值NaN会被当做是缺失值,在fit的时候忽略,在transform的时候保持缺失NaN的状态显示。
并且,尽管去量纲化过程不是具体的算法,但在fit接口中,依然只允许导入至少二维数组,一维数组导入会报错。
通常来说,我们输入的X会是我们的特征矩阵,现实案例中特征矩阵不太可能是一维所以不会存在这个问题。
StandardScaler和MinMaxScaler选哪个?
看情况。大多数机器学习算法中,会选择StandardScaler来进行特征缩放,因为MinMaxScaler对异常值非常敏感。在PCA,聚类,逻辑回归,支持向量机,神经网络这些算法中,StandardScaler往往是最好的选择。MinMaxScaler在不涉及距离度量、梯度、协方差计算以及数据需要被压缩到特定区间时使用广泛,比如数字图像处理中量化像素强度时,都会使用MinMaxScaler将数据压缩于[0,1]区间之中。建议先试试看StandardScaler,效果不好换MinMaxScaler。
除了StandardScaler和MinMaxScaler之外,sklearn中也提供了各种其他缩放处理(中心化只需要一个pandas广播一下减去某个数就好了,因此sklearn不提供任何中心化功能)。
比如,在希望压缩数据,却不影响数据的稀疏性时(不影响矩阵中取值为0的个数时),我们会使用MaxAbsScaler;在异常值多,噪声非常大时,我们可能会选用分位数来无量纲化,此时使用RobustScaler。更多详情请参考以下列表。
机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化的更多相关文章
- 机器学习实战基础(三十五):随机森林 (二)之 RandomForestClassifier 之重要参数
RandomForestClassifier class sklearn.ensemble.RandomForestClassifier (n_estimators=’10’, criterion=’g ...
- 机器学习实战基础(八):sklearn中的数据预处理和特征工程(一)简介
1 简介 数据挖掘的五大流程: 1. 获取数据 2. 数据预处理 数据预处理是从数据中检测,纠正或删除损坏,不准确或不适用于模型的记录的过程 可能面对的问题有:数据类型不同,比如有的是文字,有的是数字 ...
- 机器学习实战基础(二十):sklearn中的降维算法PCA和SVD(一) 之 概述
概述 1 从什么叫“维度”说开来 我们不断提到一些语言,比如说:随机森林是通过随机抽取特征来建树,以避免高维计算:再比如说,sklearn中导入特征矩阵,必须是至少二维:上周我们讲解特征工程,还特地提 ...
- sklearn中的数据预处理和特征工程
小伙伴们大家好~o( ̄▽ ̄)ブ,沉寂了这么久我又出来啦,这次先不翻译优质的文章了,这次我们回到Python中的机器学习,看一下Sklearn中的数据预处理和特征工程,老规矩还是先强调一下我的开发环境是 ...
- 机器学习实战基础(十八):sklearn中的数据预处理和特征工程(十一)特征选择 之 Wrapper包装法
Wrapper包装法 包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择.但不 ...
- 机器学习实战基础(十七):sklearn中的数据预处理和特征工程(十)特征选择 之 Embedded嵌入法
Embedded嵌入法 嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行.在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大 ...
- 机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤
Filter过滤法 过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法.它是根据各种统计检验中的分数以及相关性的各项指标来选择特征 1 方差过滤 1.1 VarianceThreshold ...
- 机器学习实战基础(十一):sklearn中的数据预处理和特征工程(四) 数据预处理 Preprocessing & Impute 之 处理分类特征:编码与哑变量
处理分类特征:编码与哑变量 在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的 ...
- 机器学习实战基础(十):sklearn中的数据预处理和特征工程(三) 数据预处理 Preprocessing & Impute 之 缺失值
缺失值 机器学习和数据挖掘中所使用的数据,永远不可能是完美的.很多特征,对于分析和建模来说意义非凡,但对于实际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的 ...
随机推荐
- 解决mysql不是内部或外部命令(win10)
1.原因:cmd当前所在路径为c盘下的system32,由于mysql安装位置不在该目录下,所以会报错. 2.解决方法:配置环境变量 step1:右击此电脑->属性 step2:选择高级系统设置 ...
- Shell编译安装nginx
环境及规划 [root@nginx-node01 ~]# cat /etc/redhat-release CentOS Linux release 7.6.1810 (Core) ID 主机名 ip ...
- BT.656视频信号解码
BT.656视频信号解码 BT.656协议标准 ITU-R BT.601和ITU-R BT.656是ITU-R(国际电信联盟)制定的标准.严格来说ITU-R BT.656是ITU-R BT.601 ...
- Java 源码刨析 - String
[String 是如何实现的?它有哪些重要的方法?] String 内部实际存储结构为 char 数组,源码如下: public final class String implements java. ...
- [问题解决]coding时修改代码键入前边后边的自动删除
问题原因:误按下键盘上的Insert键 解决办法:再按一下即可
- 用OpenPyXL处理Excel表格 - 向sheet读取、写入数据
假设一个名叫"模板"的excel表格里有四个sheet,名字分别是['平台', '制冷', '洗衣机', '空调'] 1.读取 from openpyxl import load_ ...
- springboot 2.X 集成redis
在实际开发中,经常会引入redis中间件做缓存,这里介绍springboot2.X后如何配置redis 1 Maven中引入redis springboot官方通过spring-boot-autoco ...
- 01MySQL内核分析-The Skeleton of the Server Code
摘要 这个官方文档一段对MySQL内核分析的一个向导.是对MySQL一条insert语句写入到MySQL数据库的分析. 但是,对于MySQL 5.7版本来说,基本上都是写入到innodb引擎.但也还是 ...
- SQL注入入门
这几天做了不少SQL注入题,对SQL注入有点体会,所以写写自己的学习历程与体会. 什么是SQL注入 SQL注入就是指web程序对用户输入的数据的合法性没有进行判断,由前端传入的参数带着攻击者控制的非法 ...
- js语法基础入门(5.1)
5.流程控制 5.1.选择结构 程序流程图 图例: 椭圆: 开始/结束 矩形: 操作 菱形: 判断 连接线: 走向 可以根据程序流程图,理清楚程序执行的流程 5.2.1.if语句 //if语句语法结构 ...